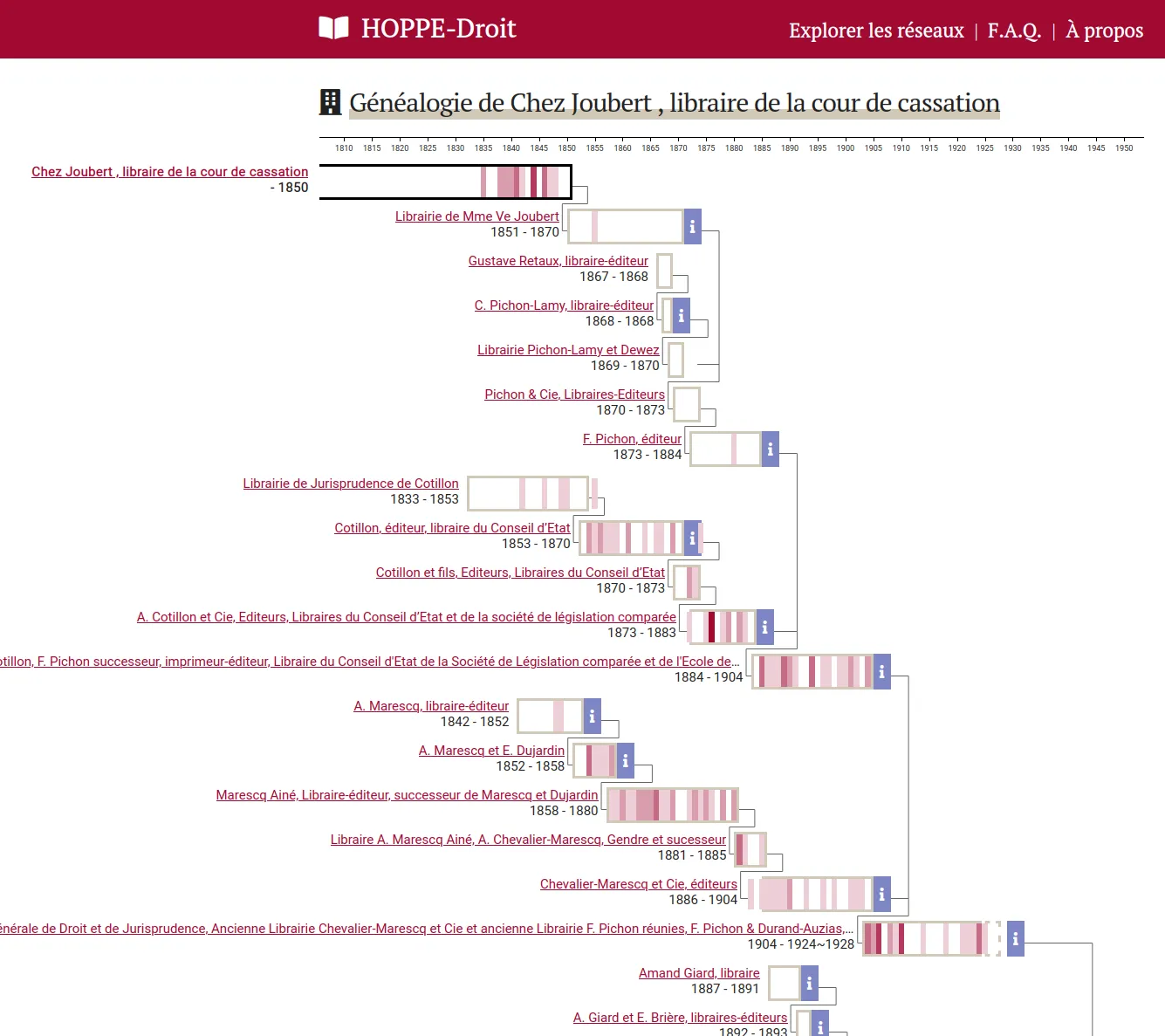
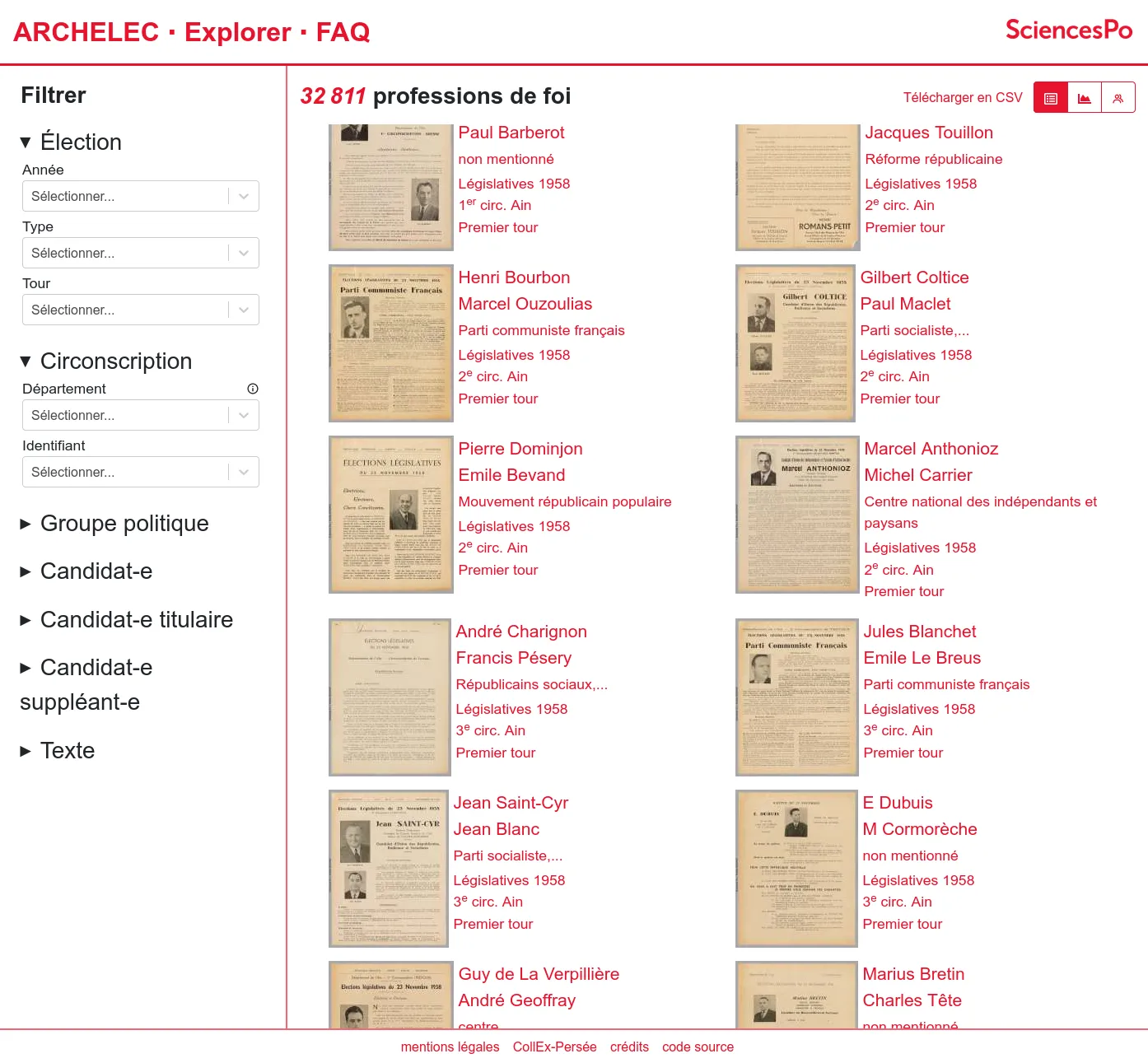
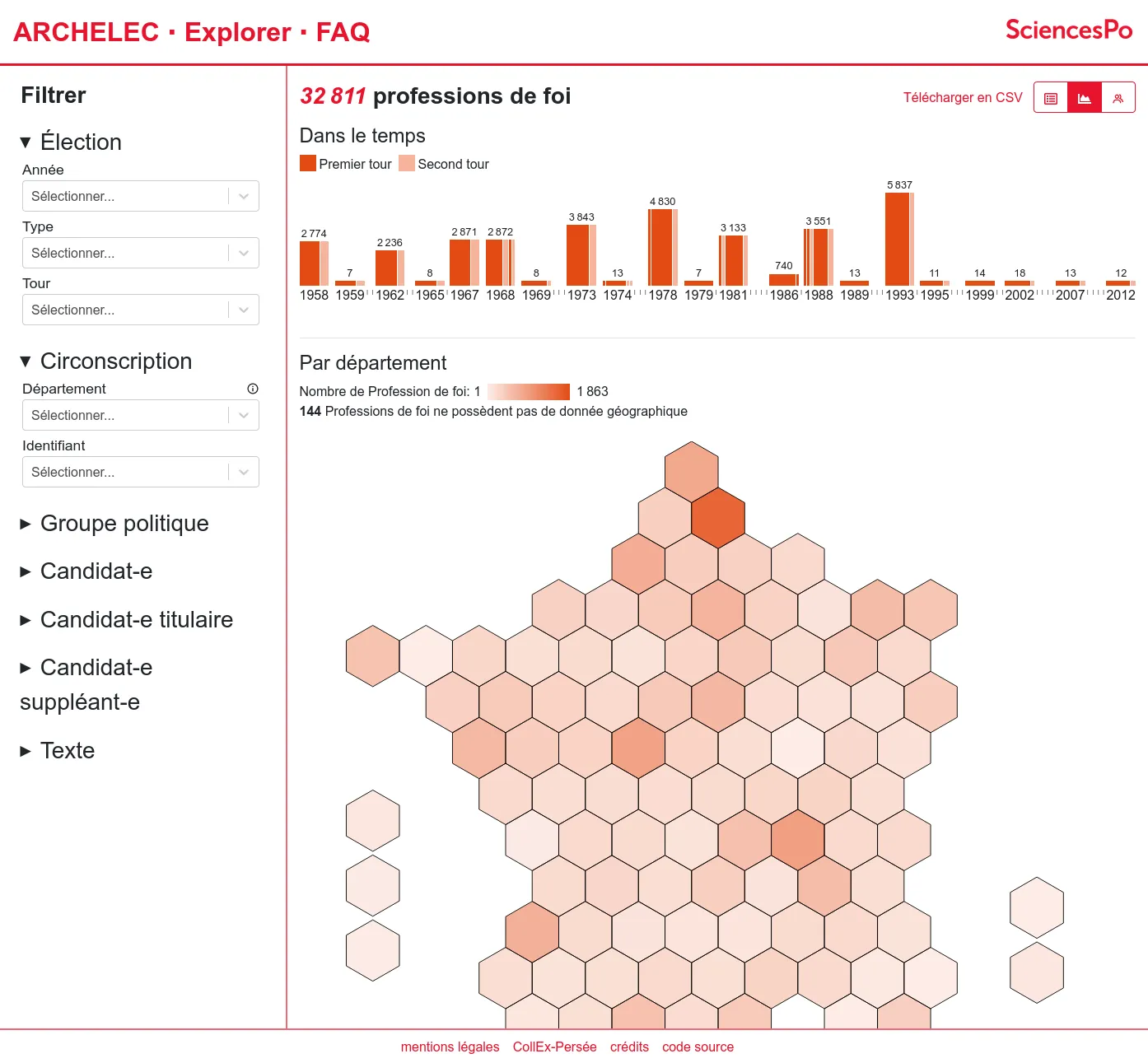
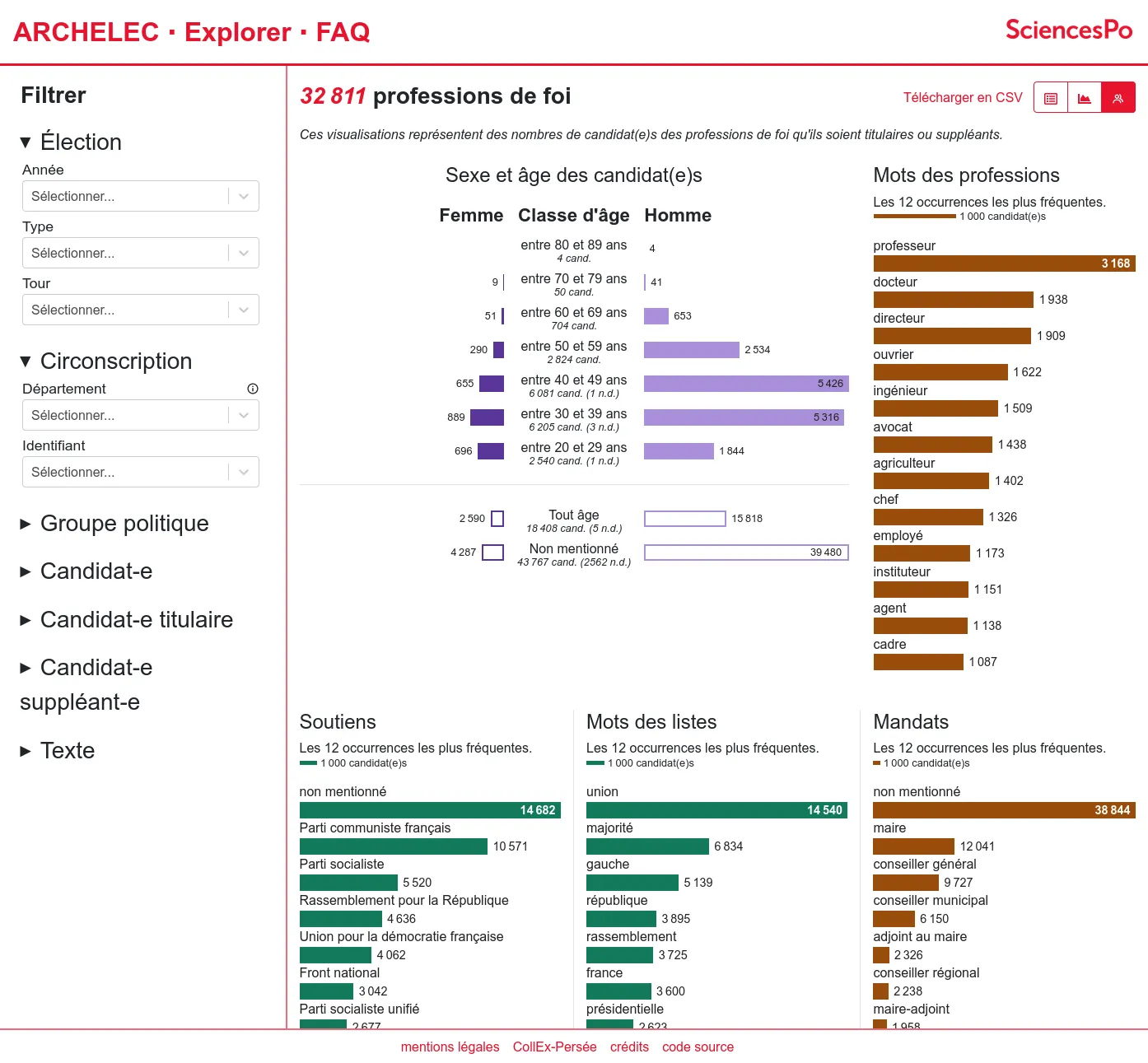
OSRD: Open Source Railway Designer
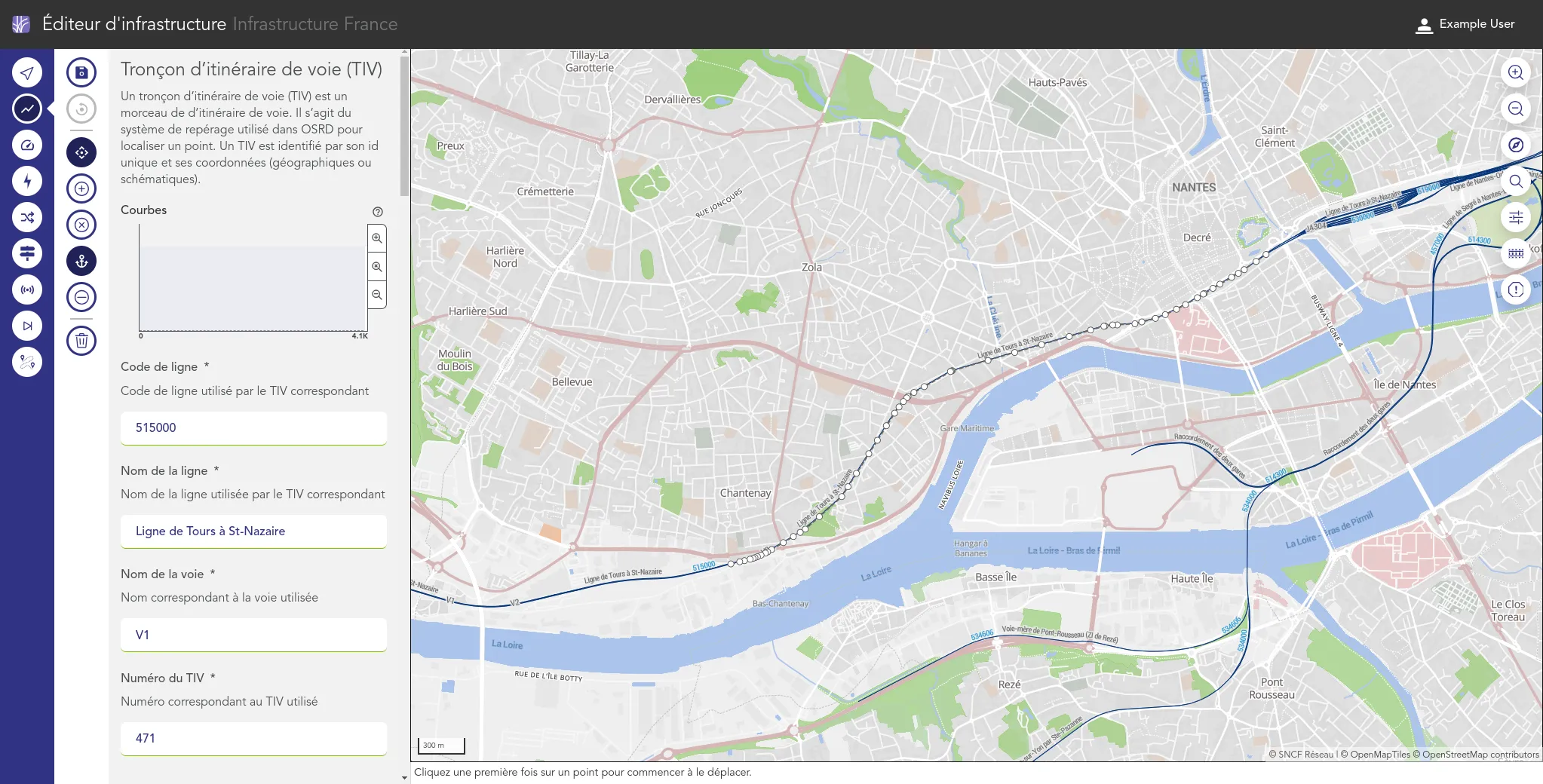
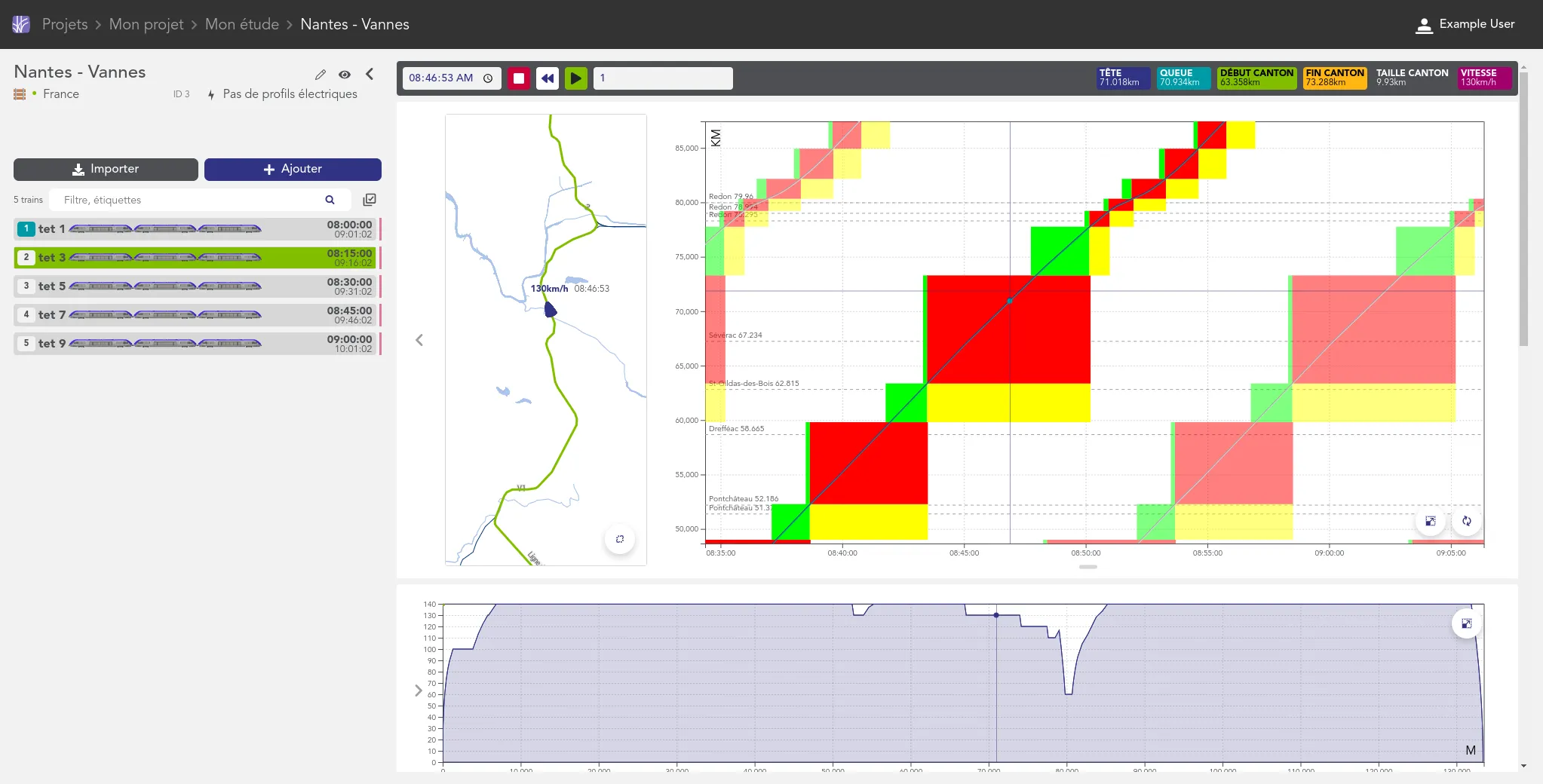
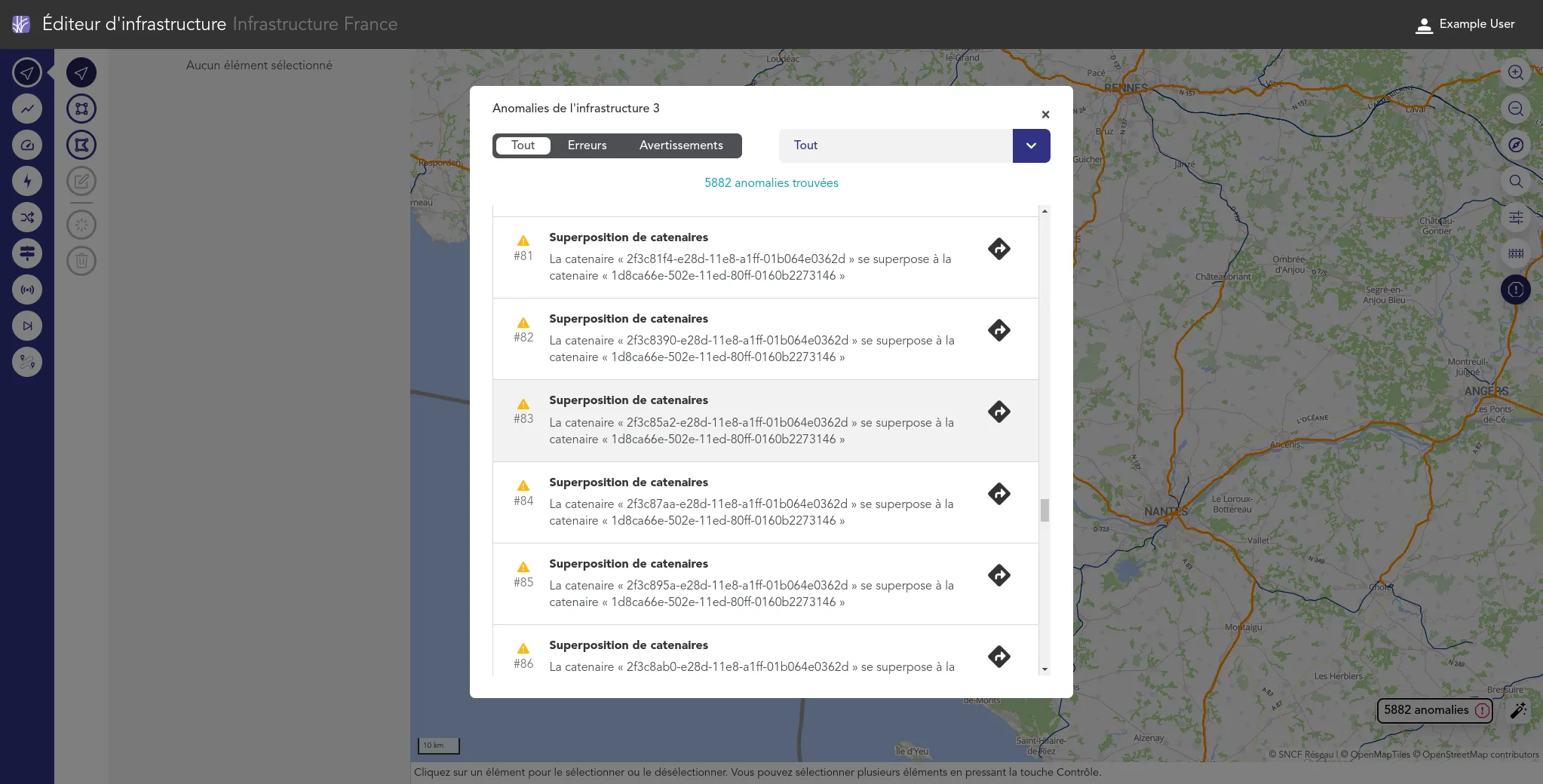
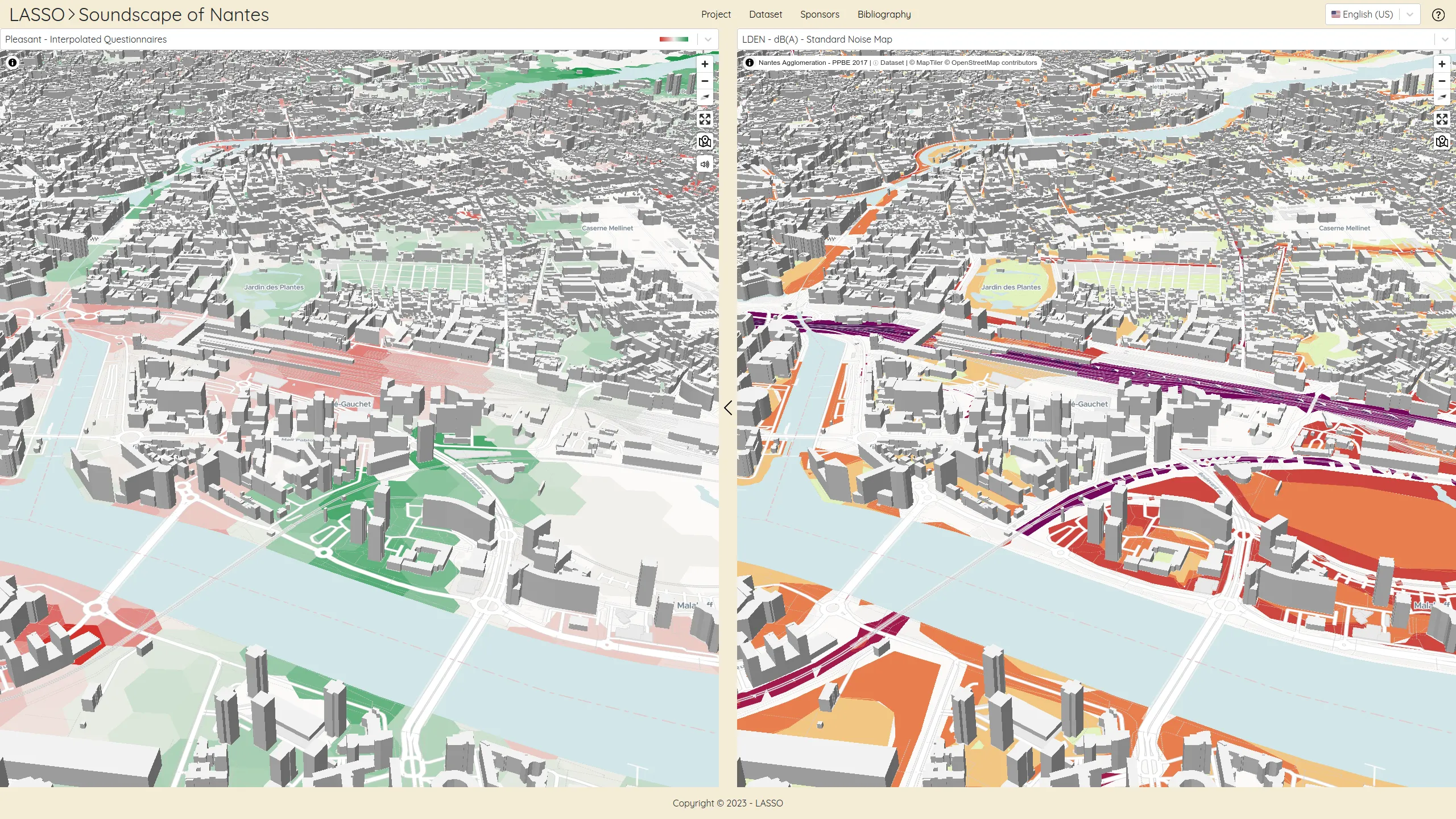
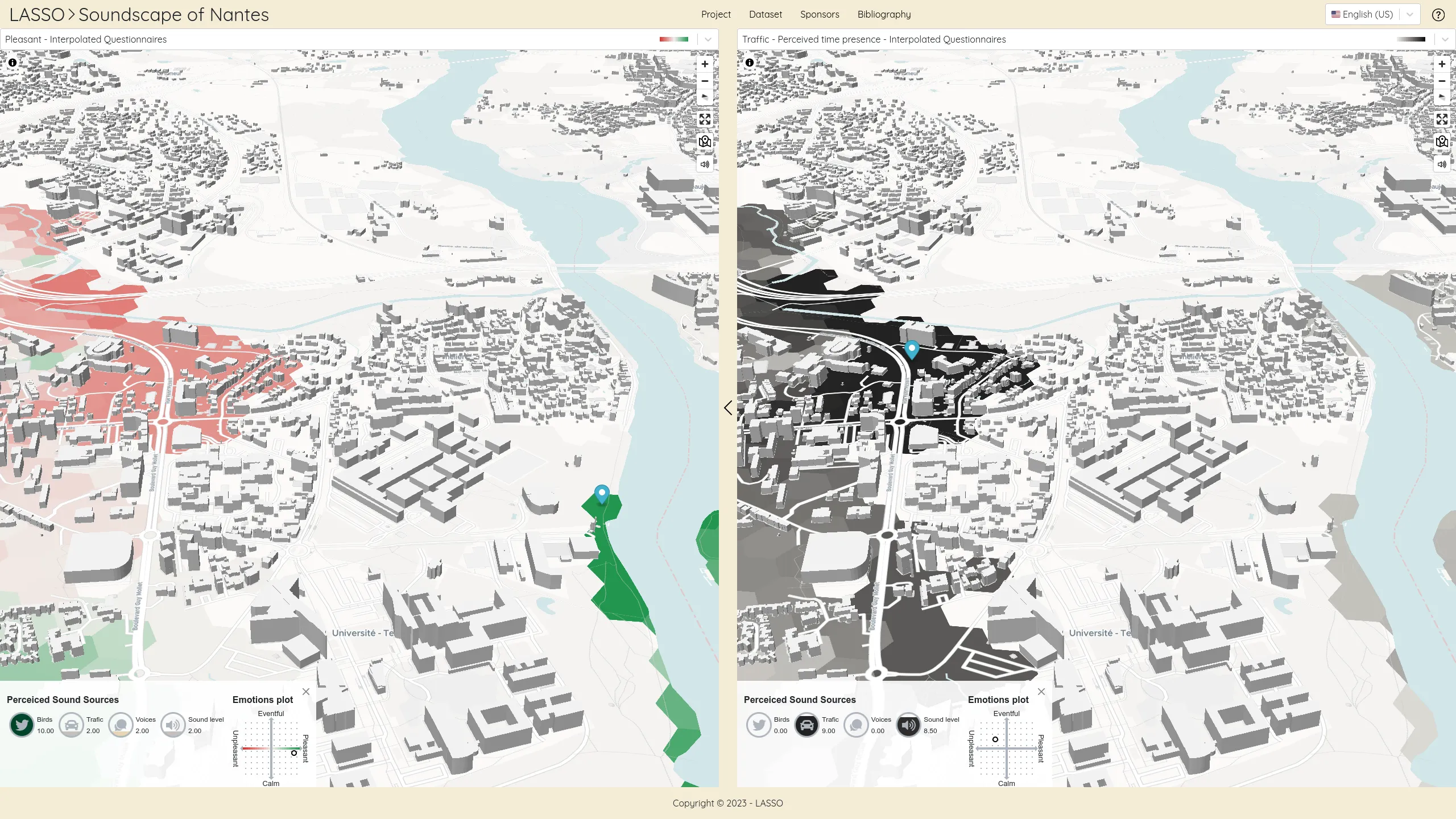
We work for the OSRD team to help developing a web-based railway infrastructure edition and management tool. We more precisely work on web interfaces dedicated to the infrastructure edition based on an advanced cartographic tool. We also contribute to some specific visualization tools such as the time-space graph.
If the project is for now centered on the french railway infrastructure, it is meant to be usable in other national contexts. It is supported by the OpenRail Association which supports efforts to spread open source railway tools across borders.
A Open Source and Open Data project
Industry JavaScript MapLibre React TypeScript