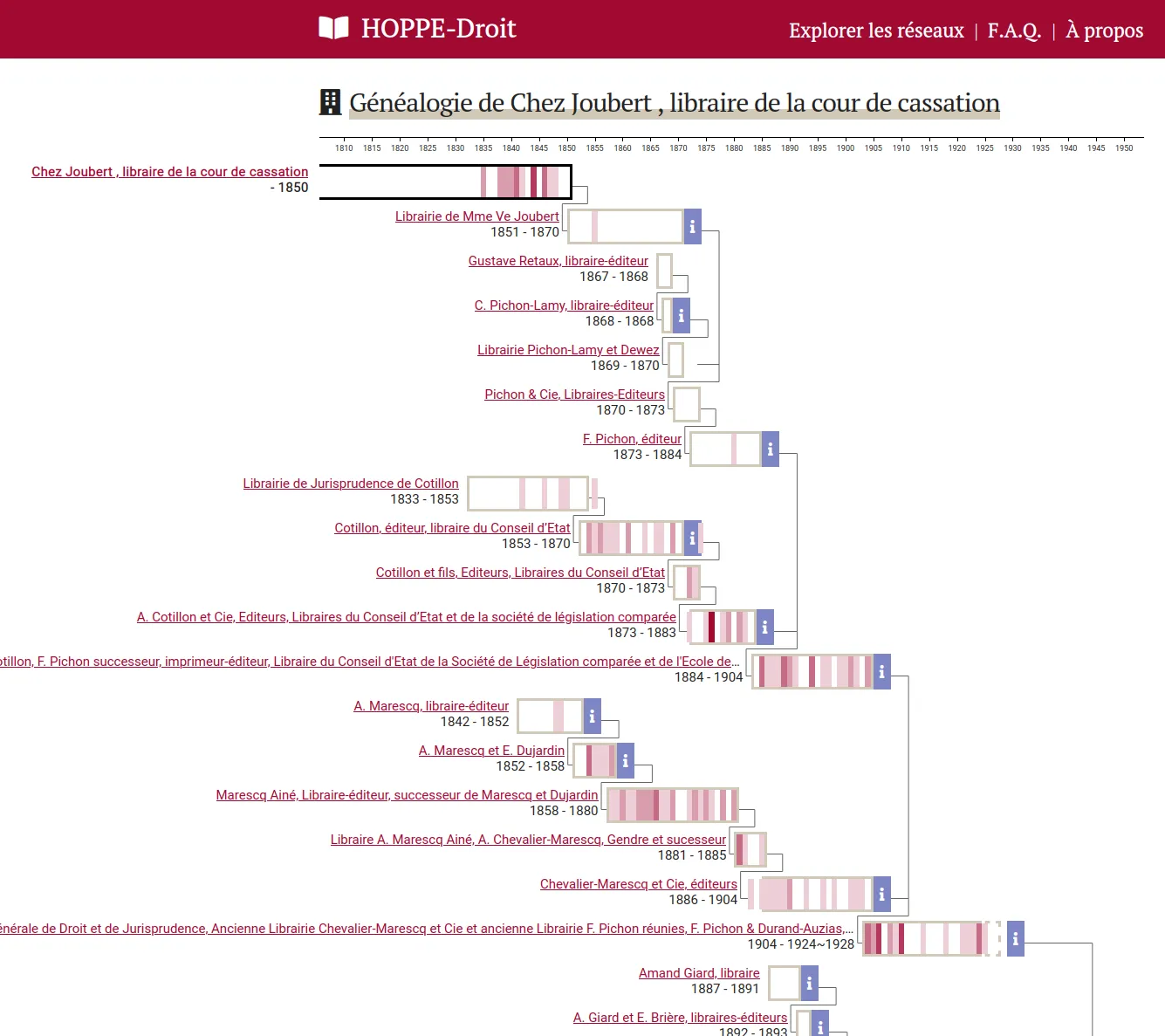
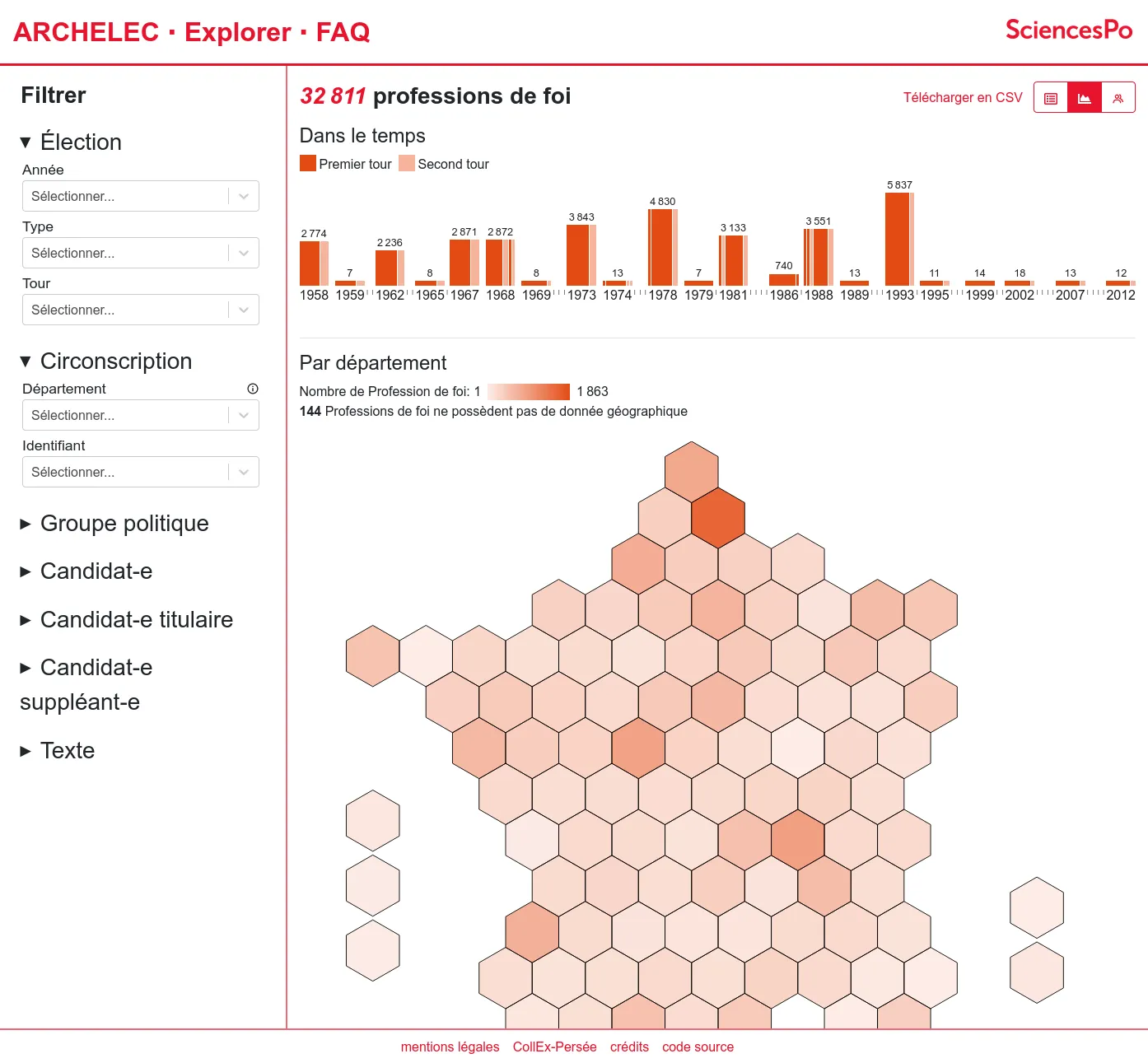
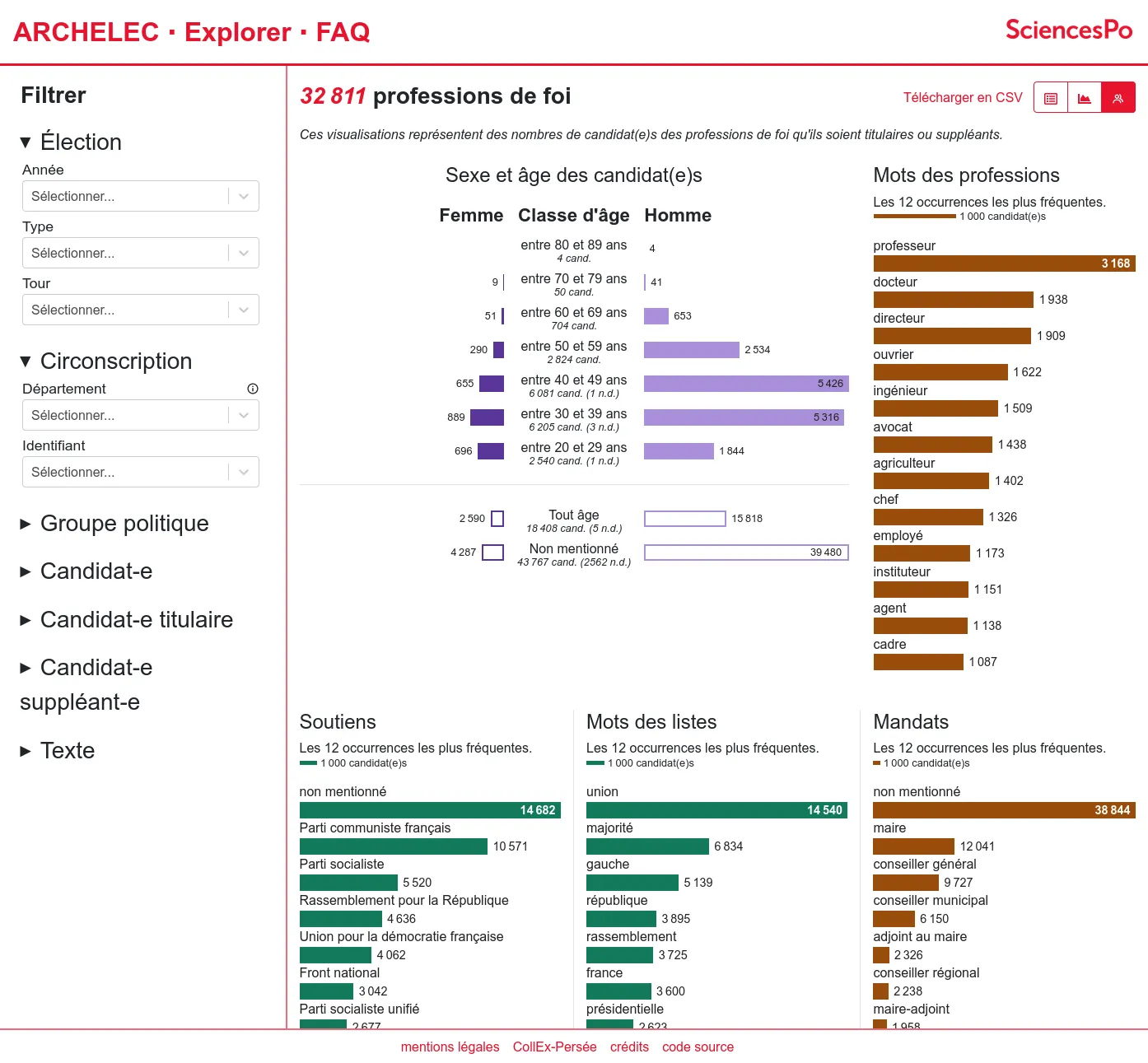
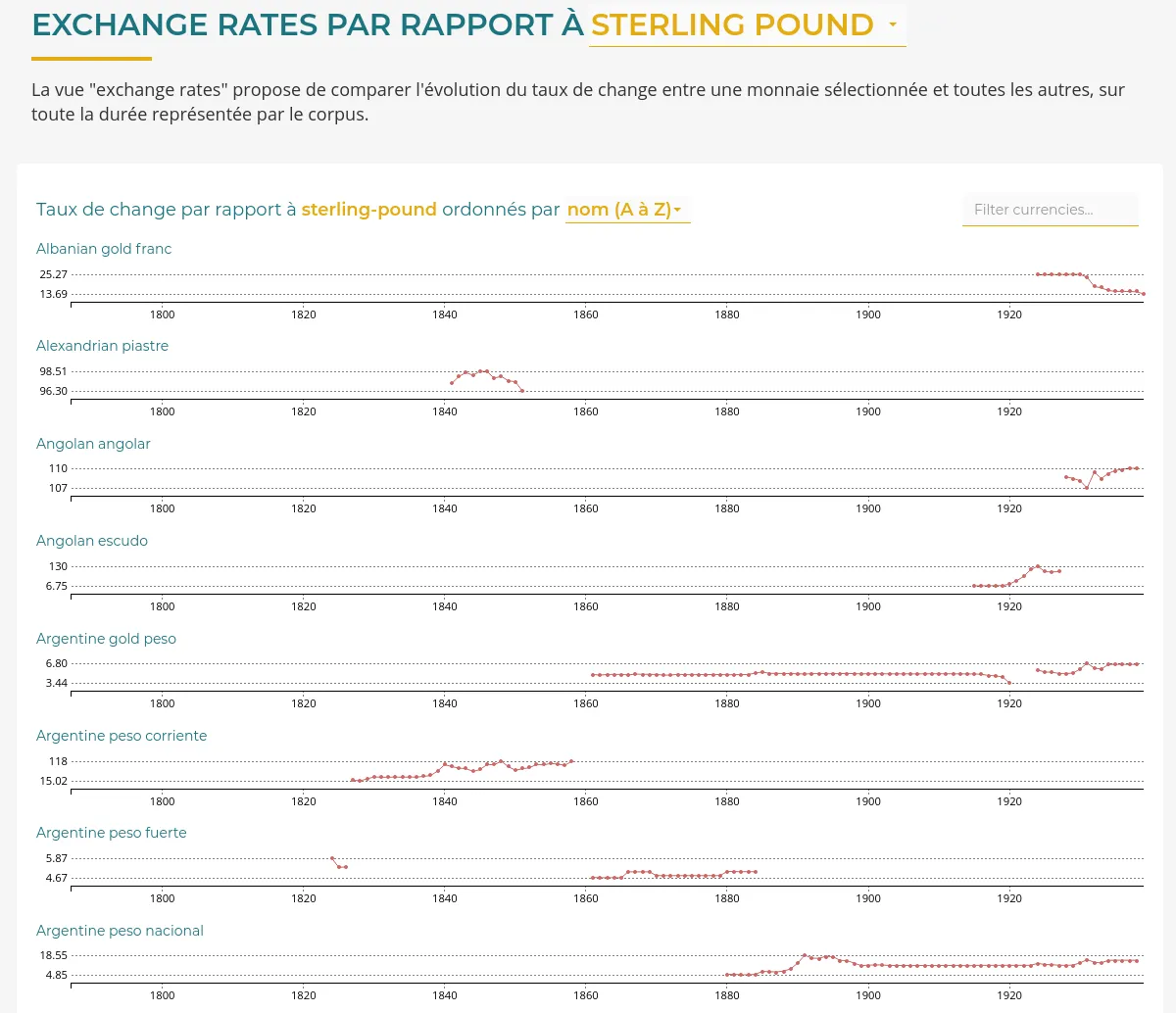
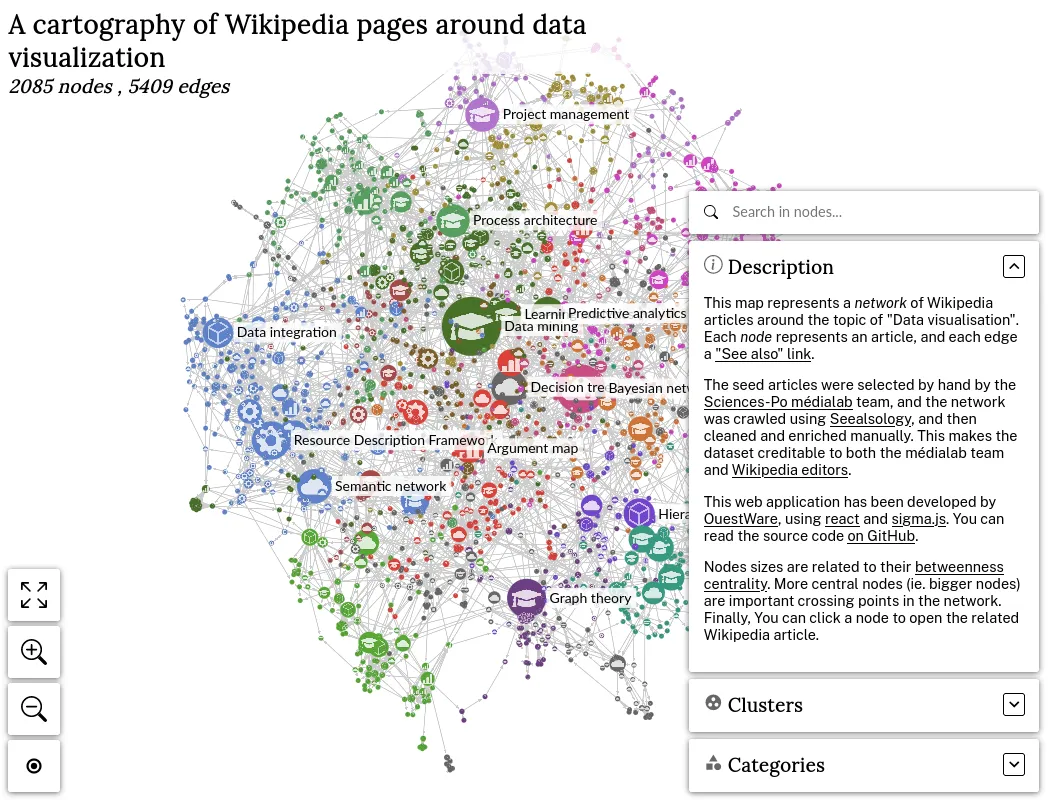
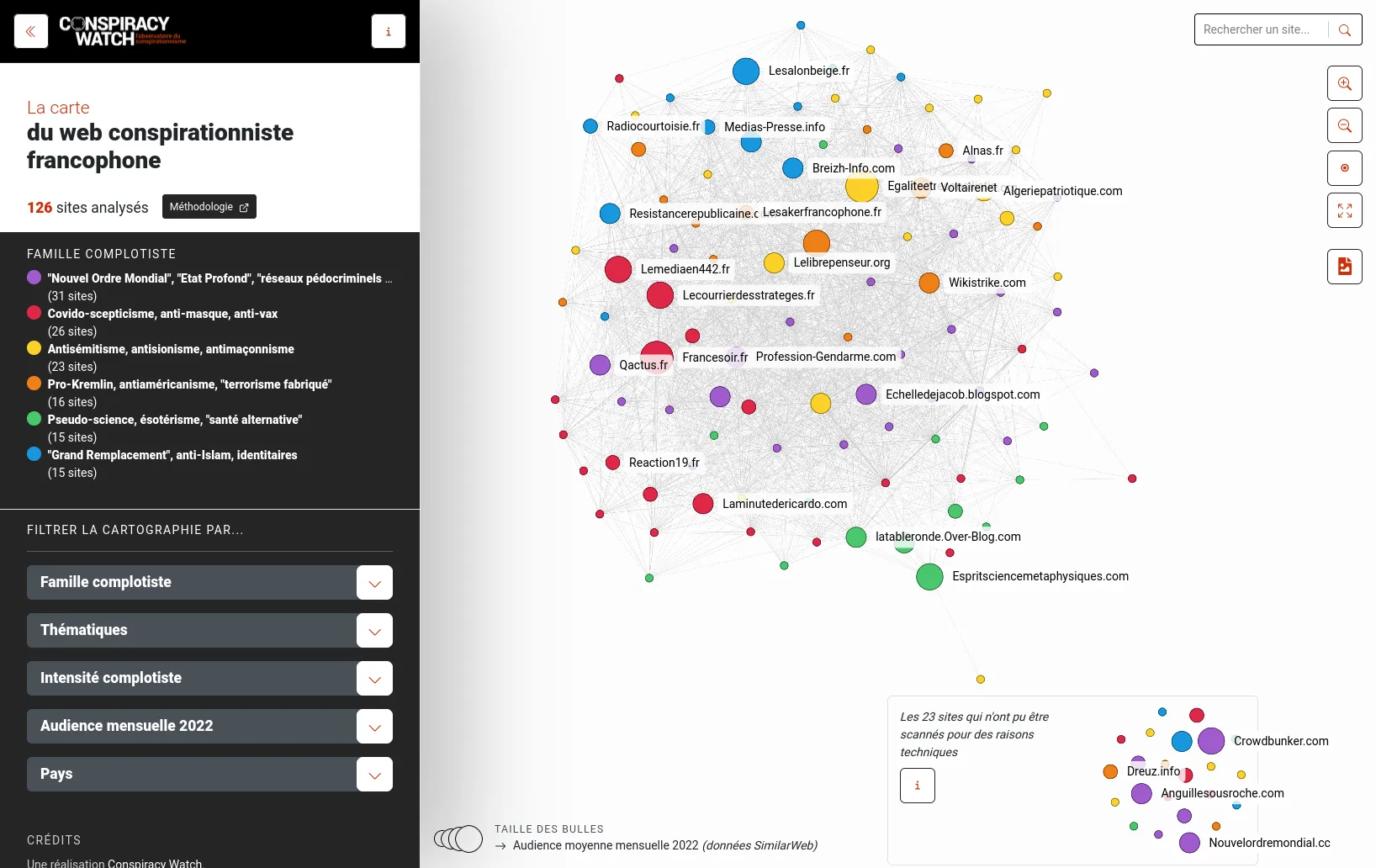
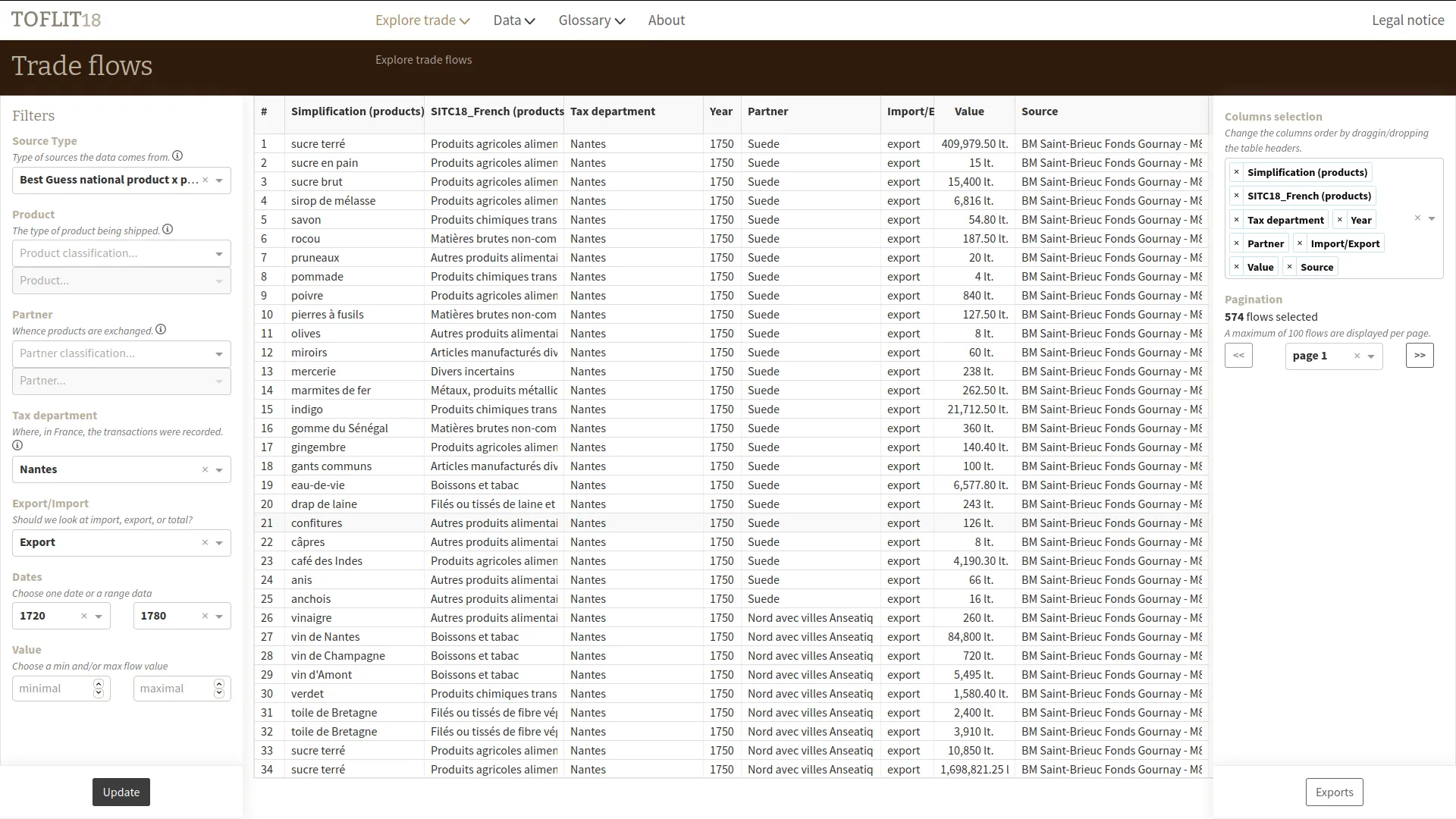
OSRD : éditeur ferroviaire open source
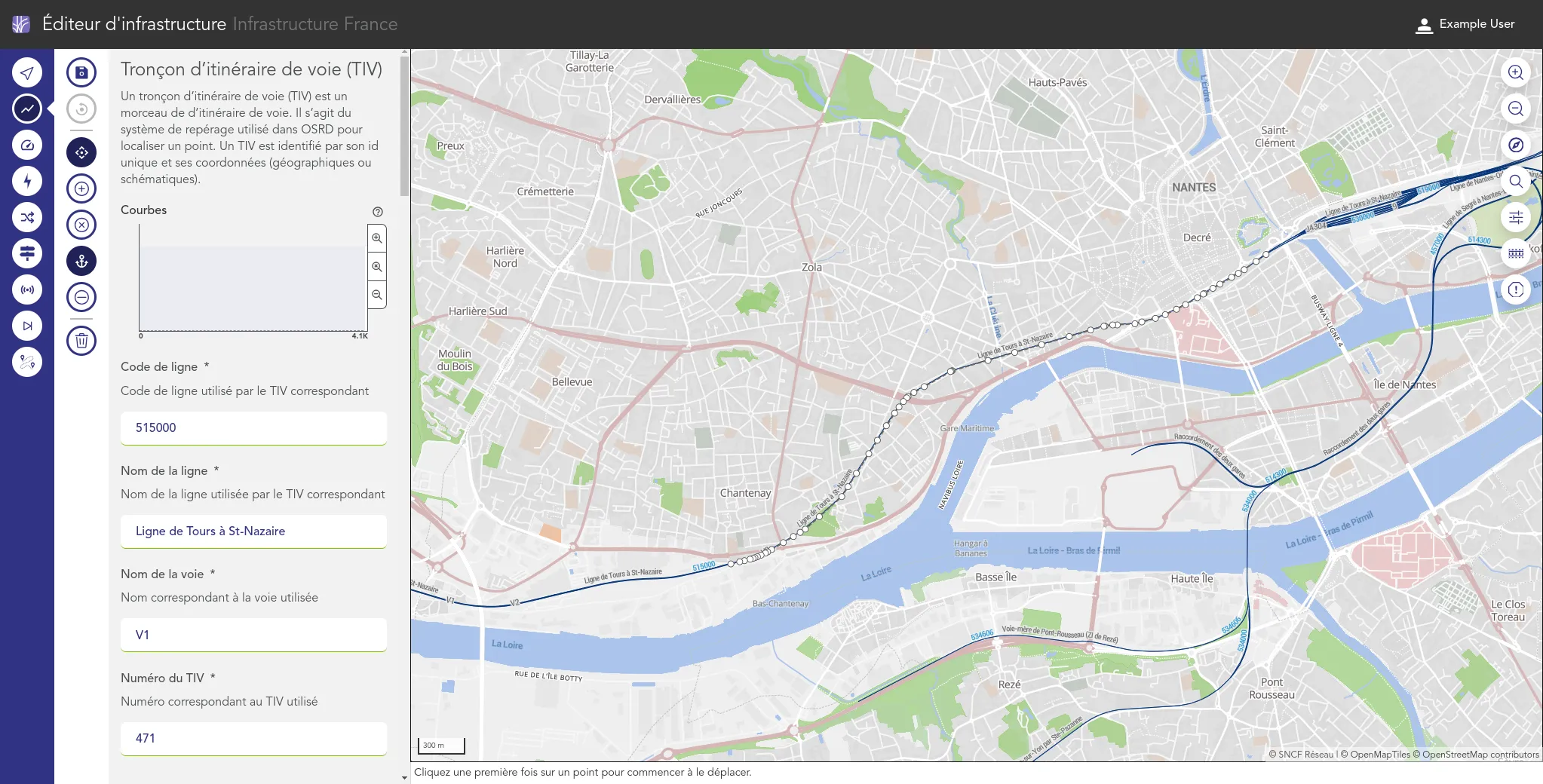
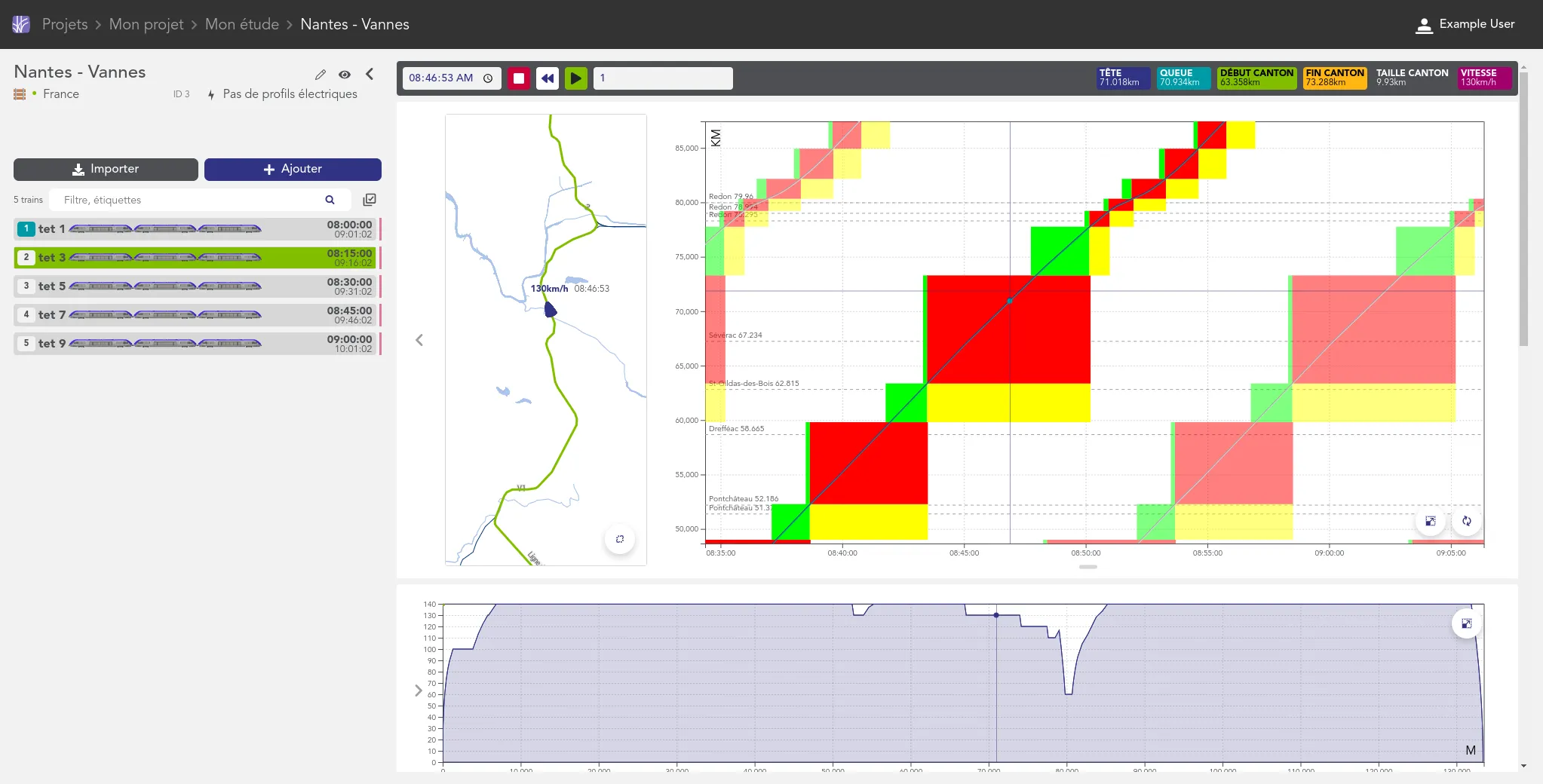
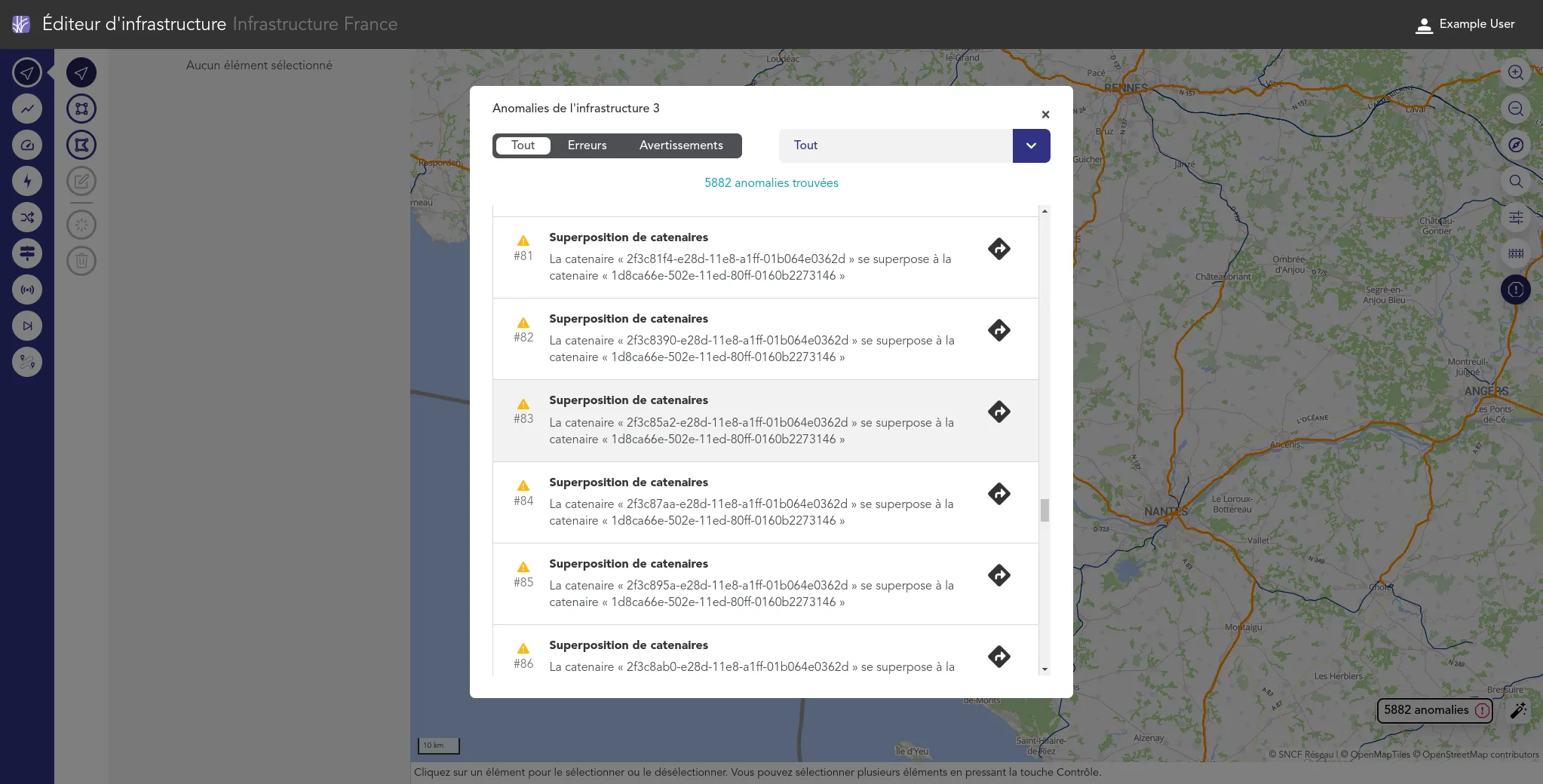
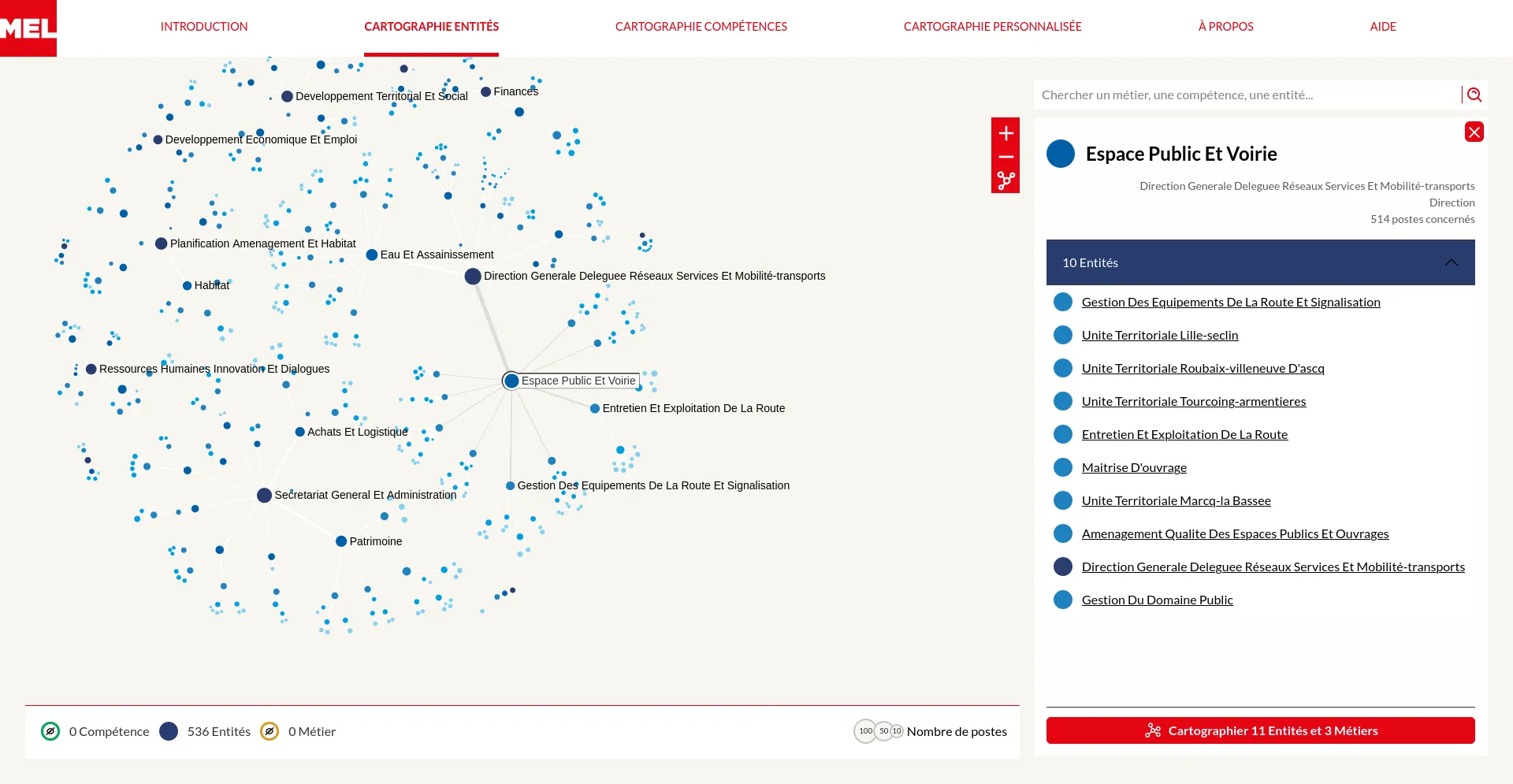
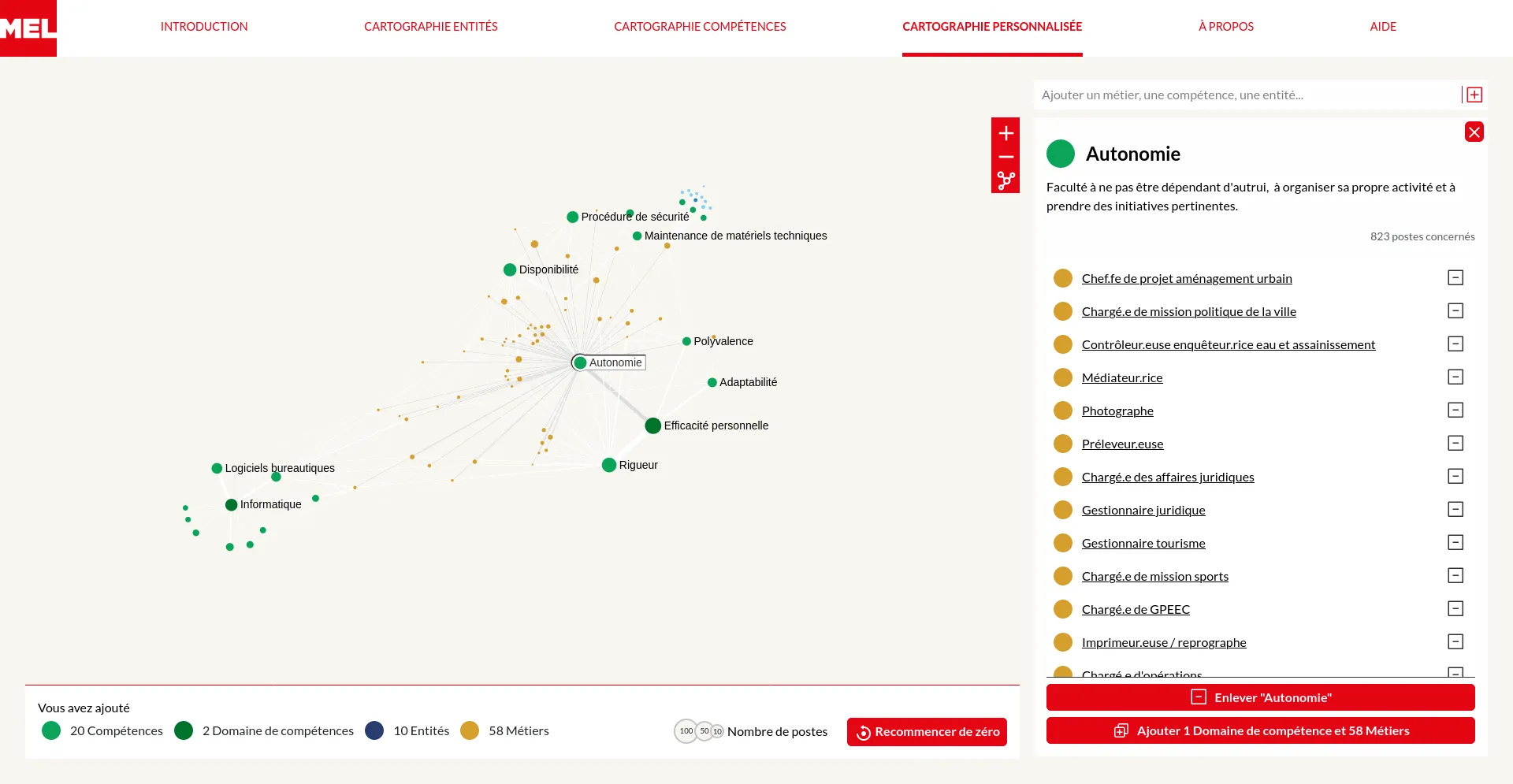
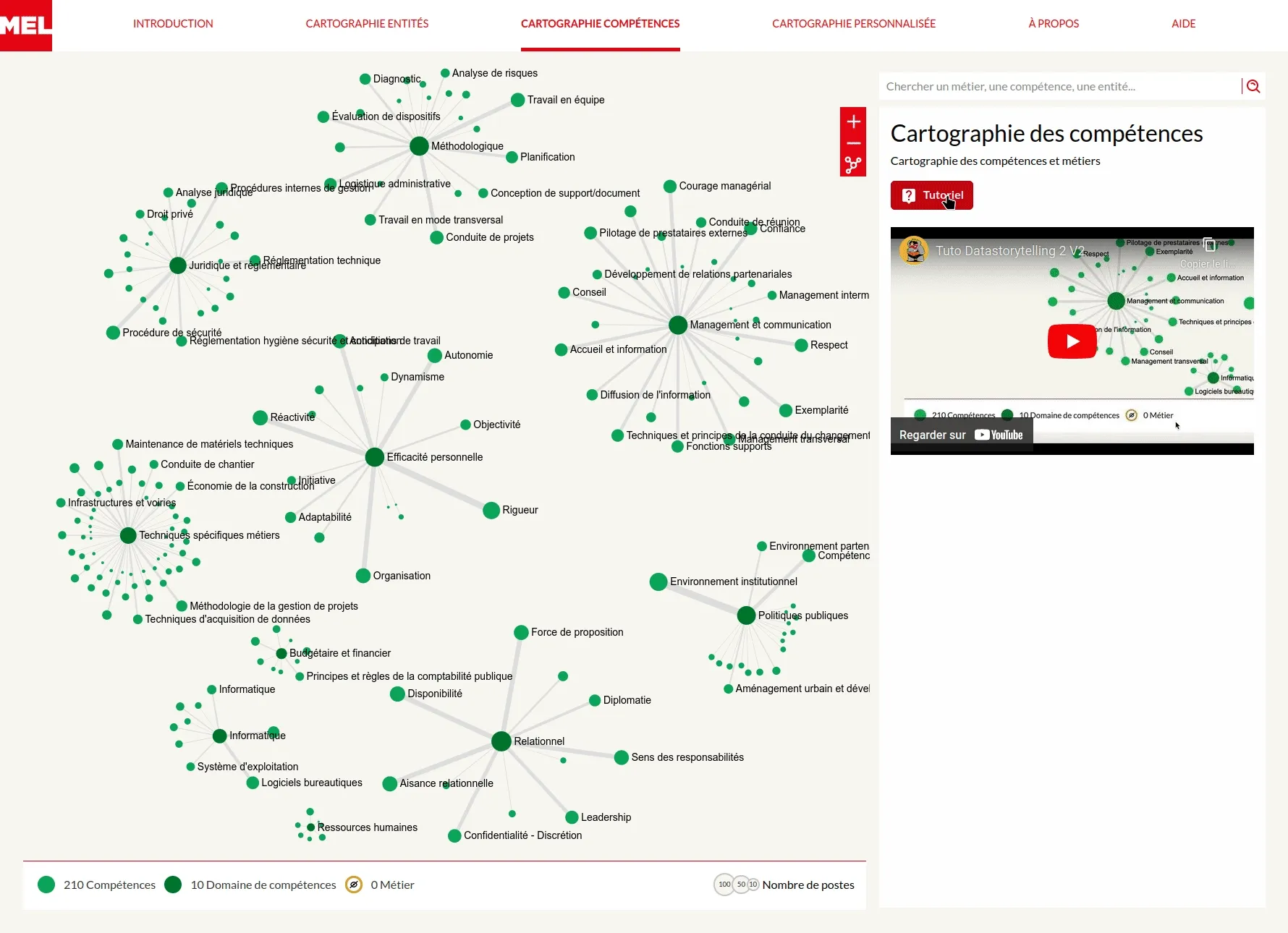
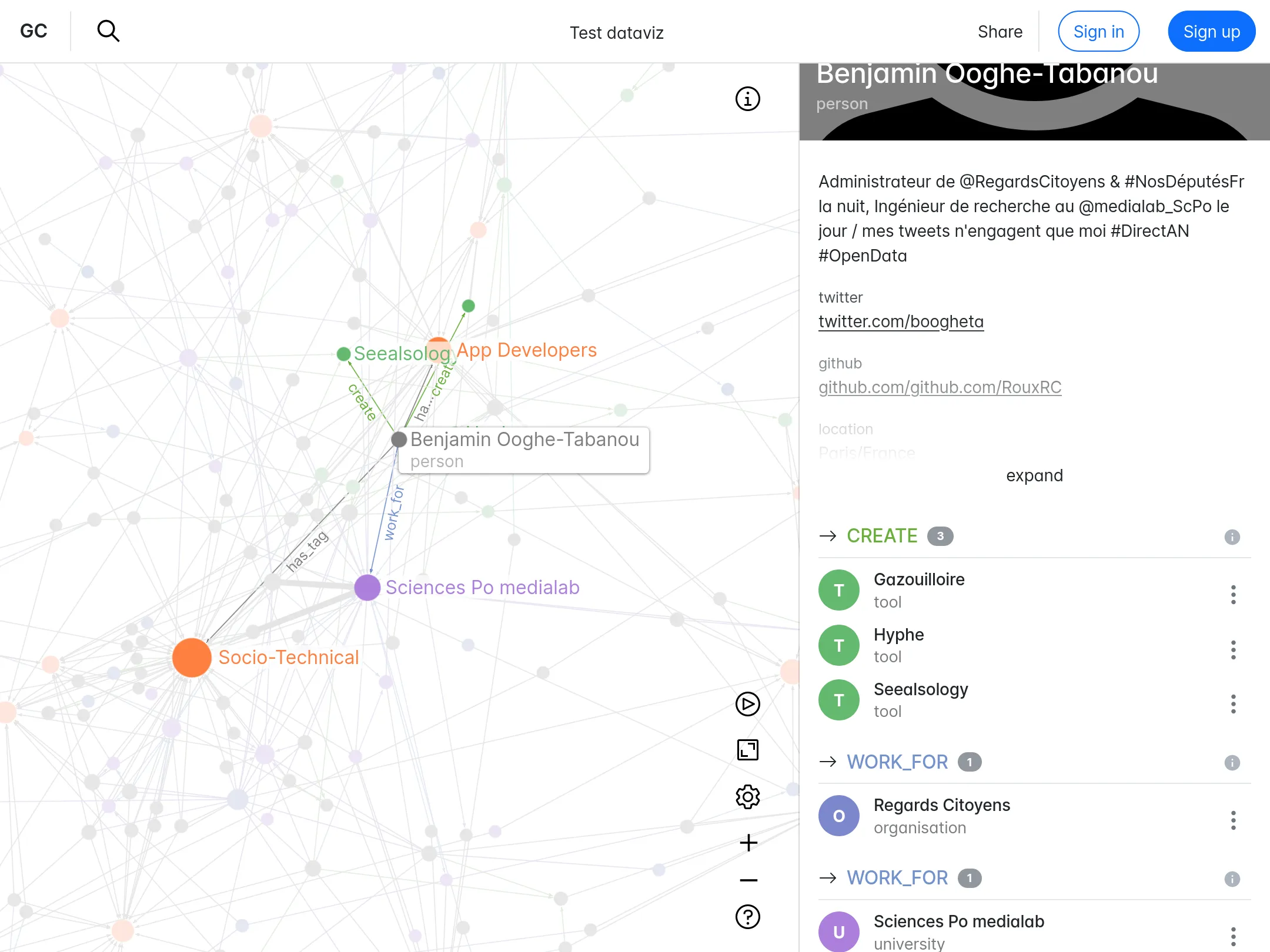
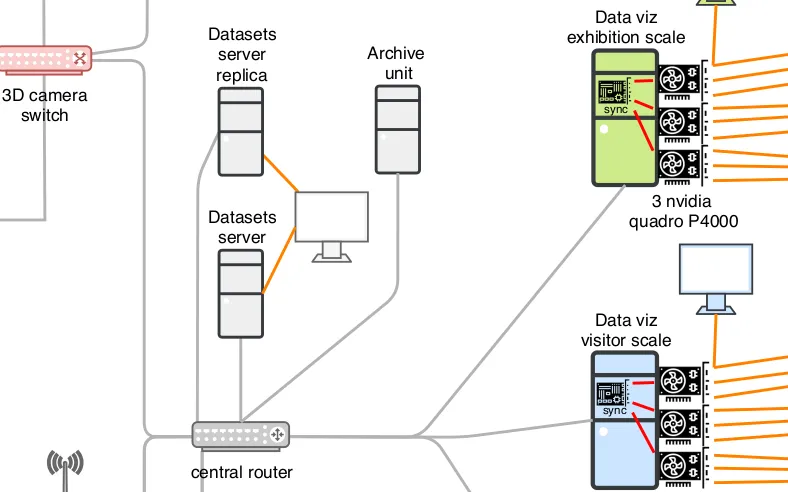
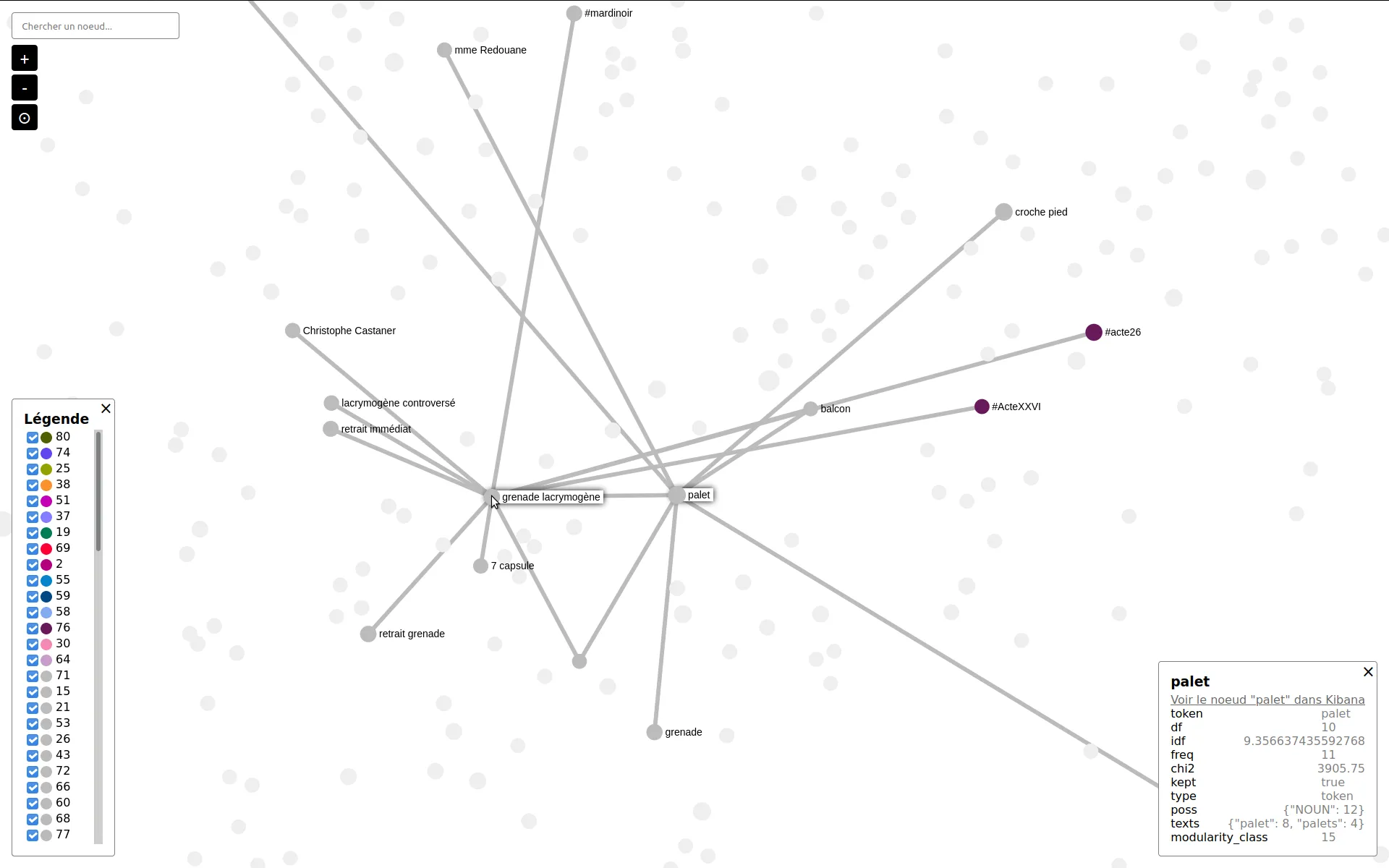
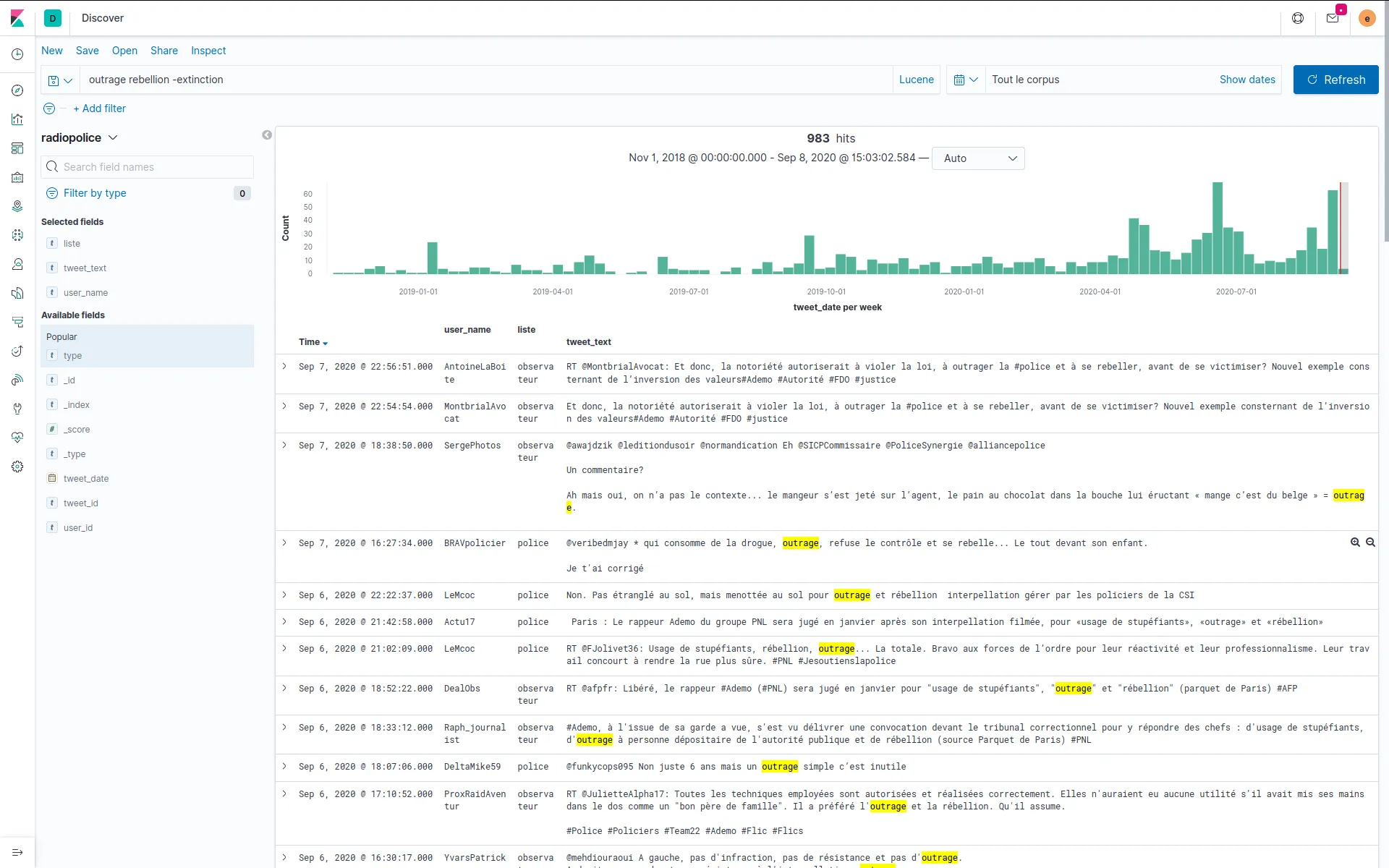
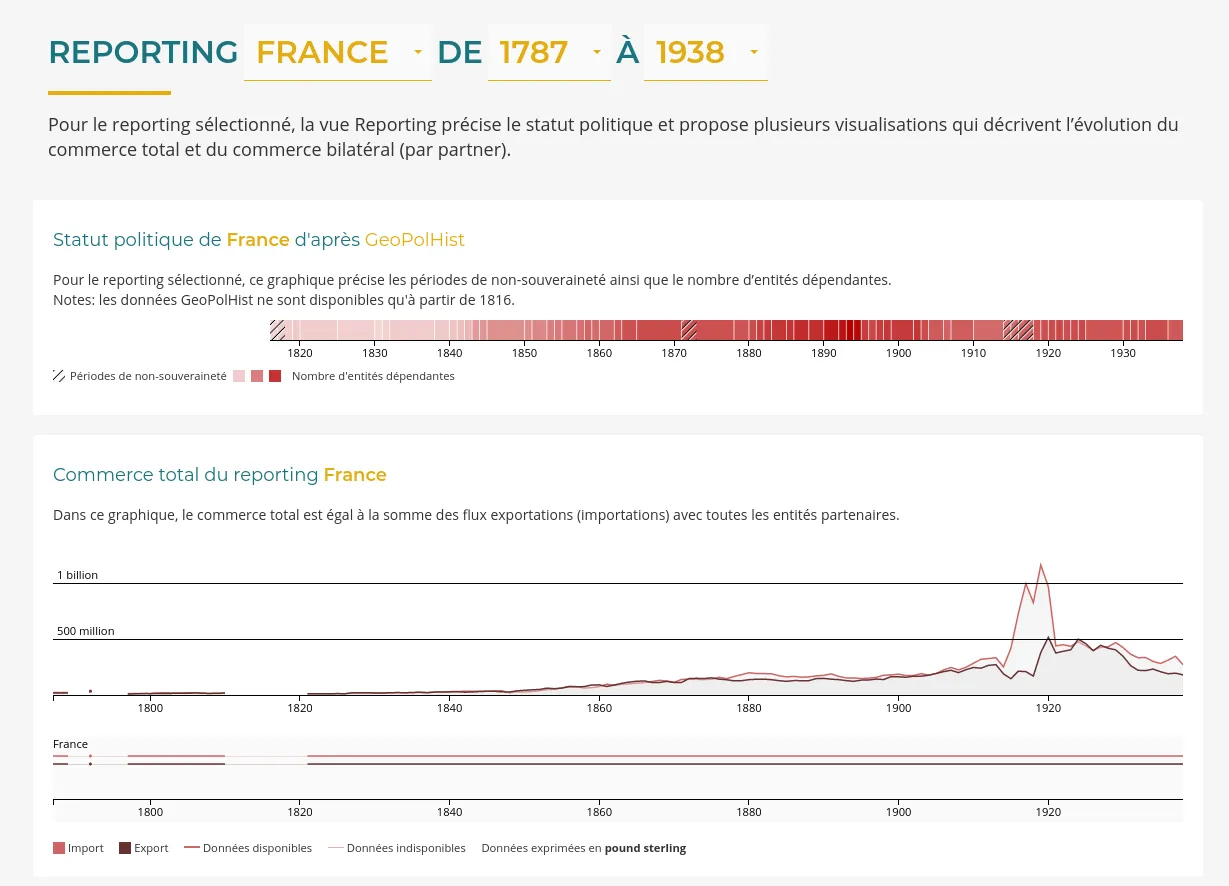
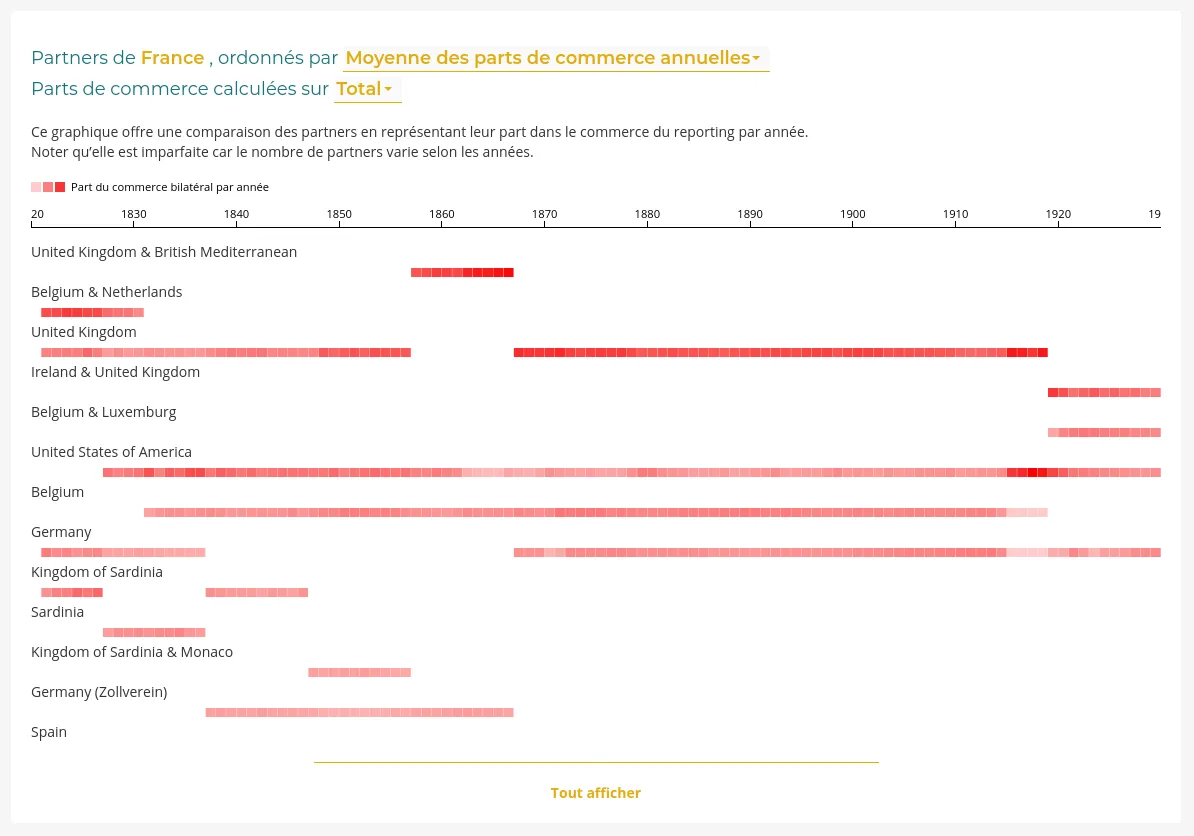
Nous accompagnons les équipes du projet OSRD en participant au développement d'une application web Open Source rassemblant divers outils d'édition et de gestion d'une infrastructure ferroviaire. Nous intervenons plus particulièrement sur les interfaces web permettant l'édition de l'infrastructure dans un outil cartographique avancé. Nous intervenons également sur certaines briques de visualisation comme le graphique espace-temps.
Si ce projet est centré pour le moment sur l'infrastructure française il a pour vocation à terme à être utilisable dans d'autres contextes. Il fait à ce titre partie de la OpenRail Association qui coordonne les efforts transnationaux de convergence des outils open source ferroviaires.
Un projet de Code et Données ouvertes