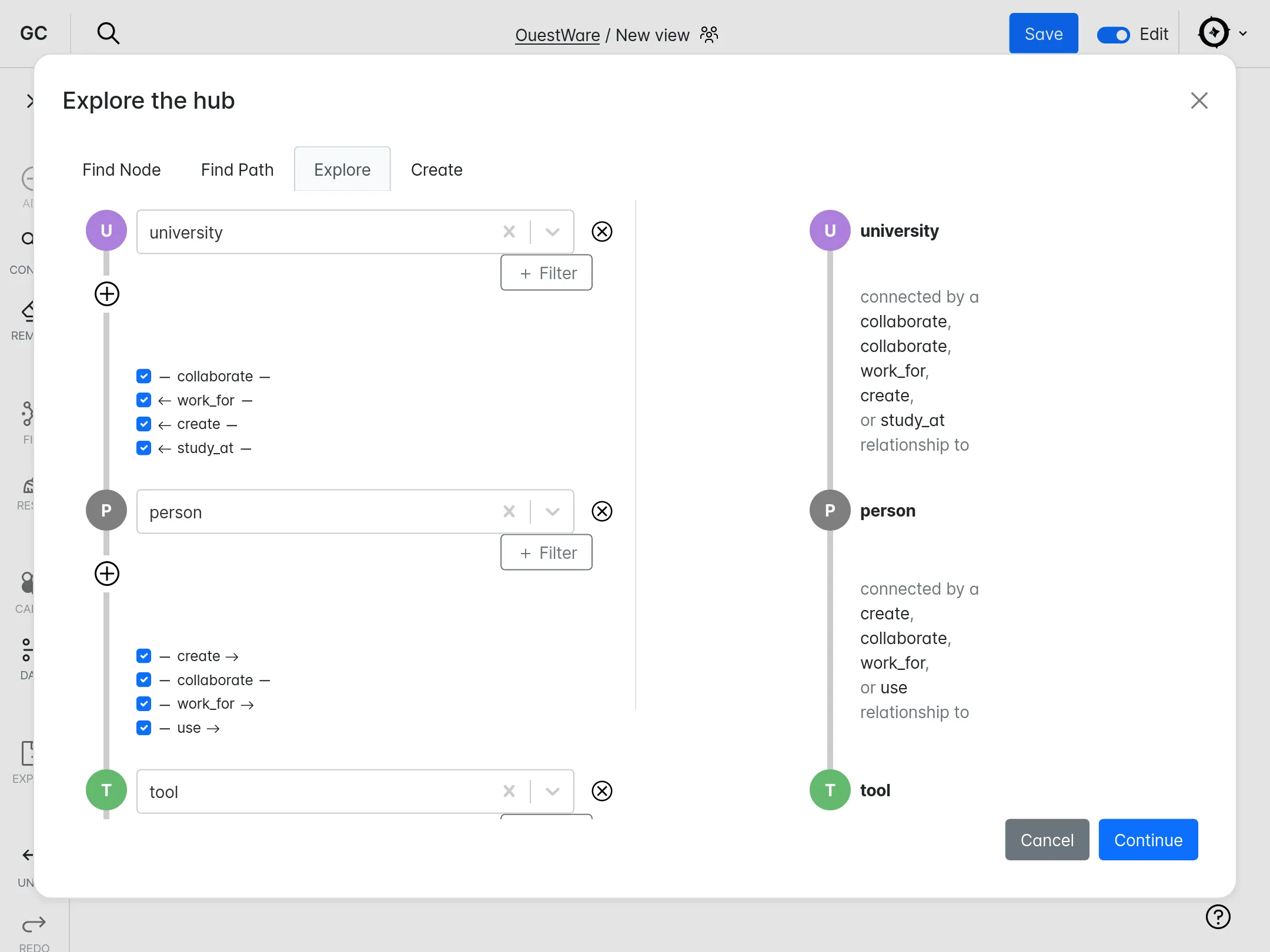
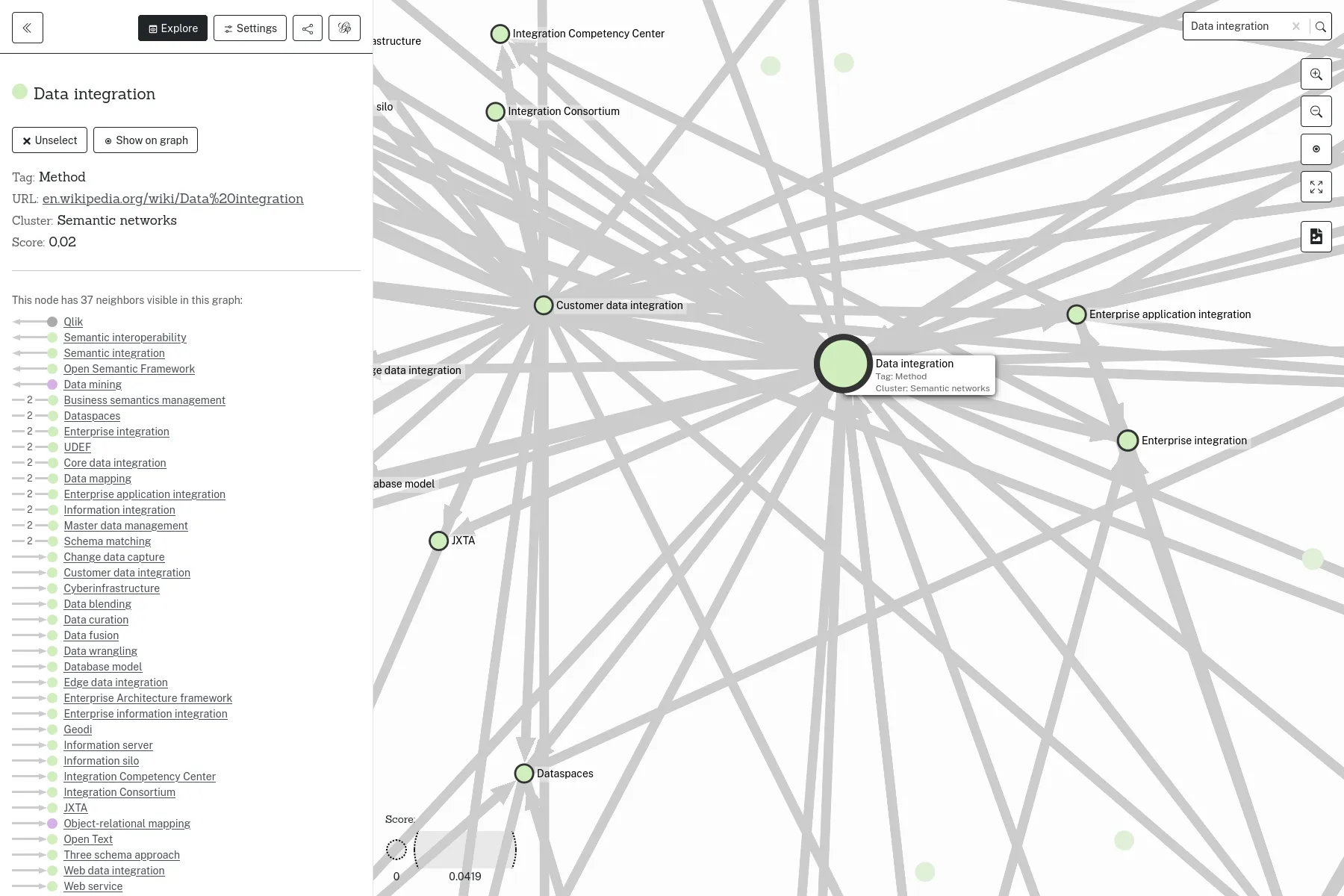
Événement
OpenRail Day @Paris
La première rencontre publique de la communauté OpenRail Association, dont fait parti le projet OSRD.
Paris, France
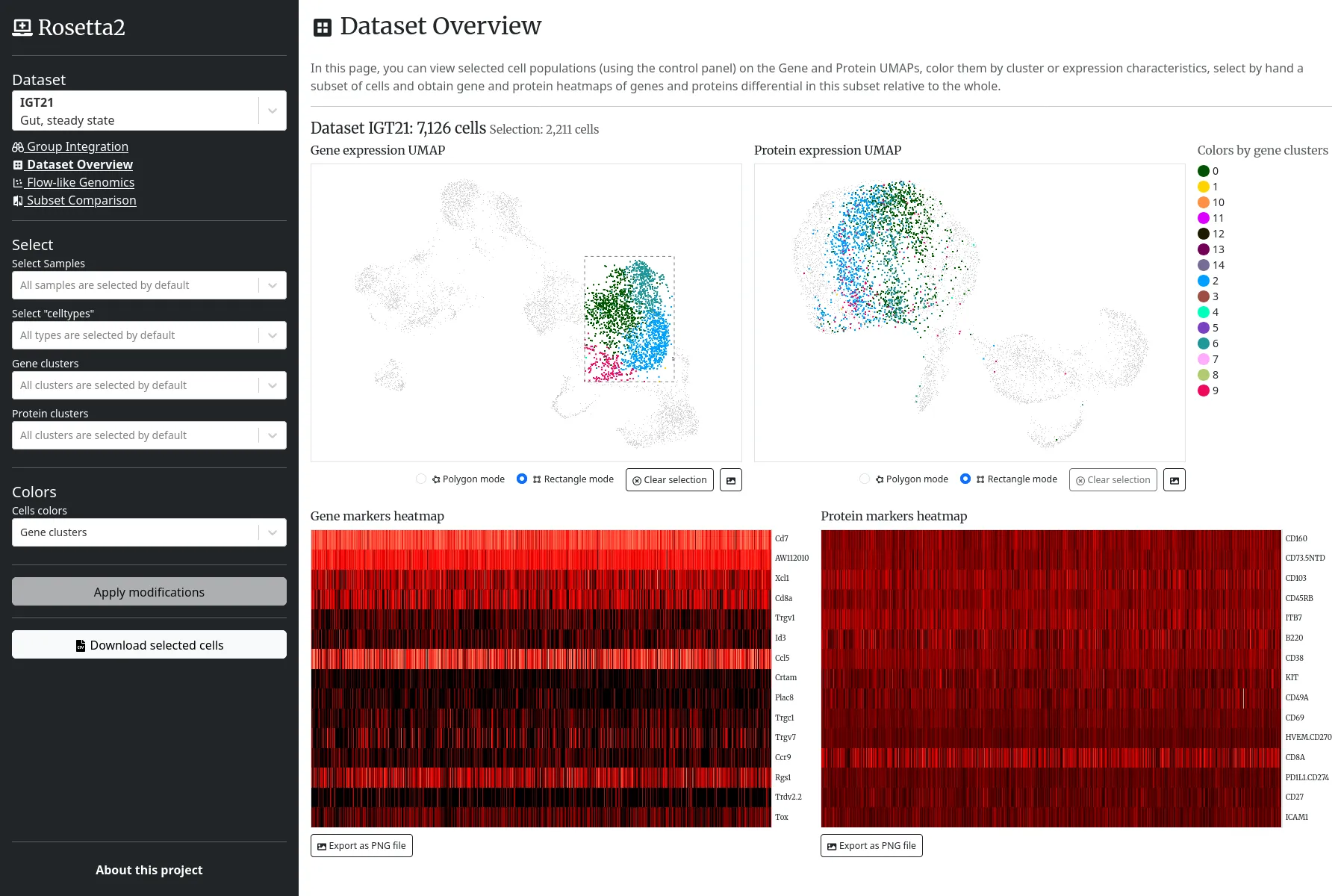
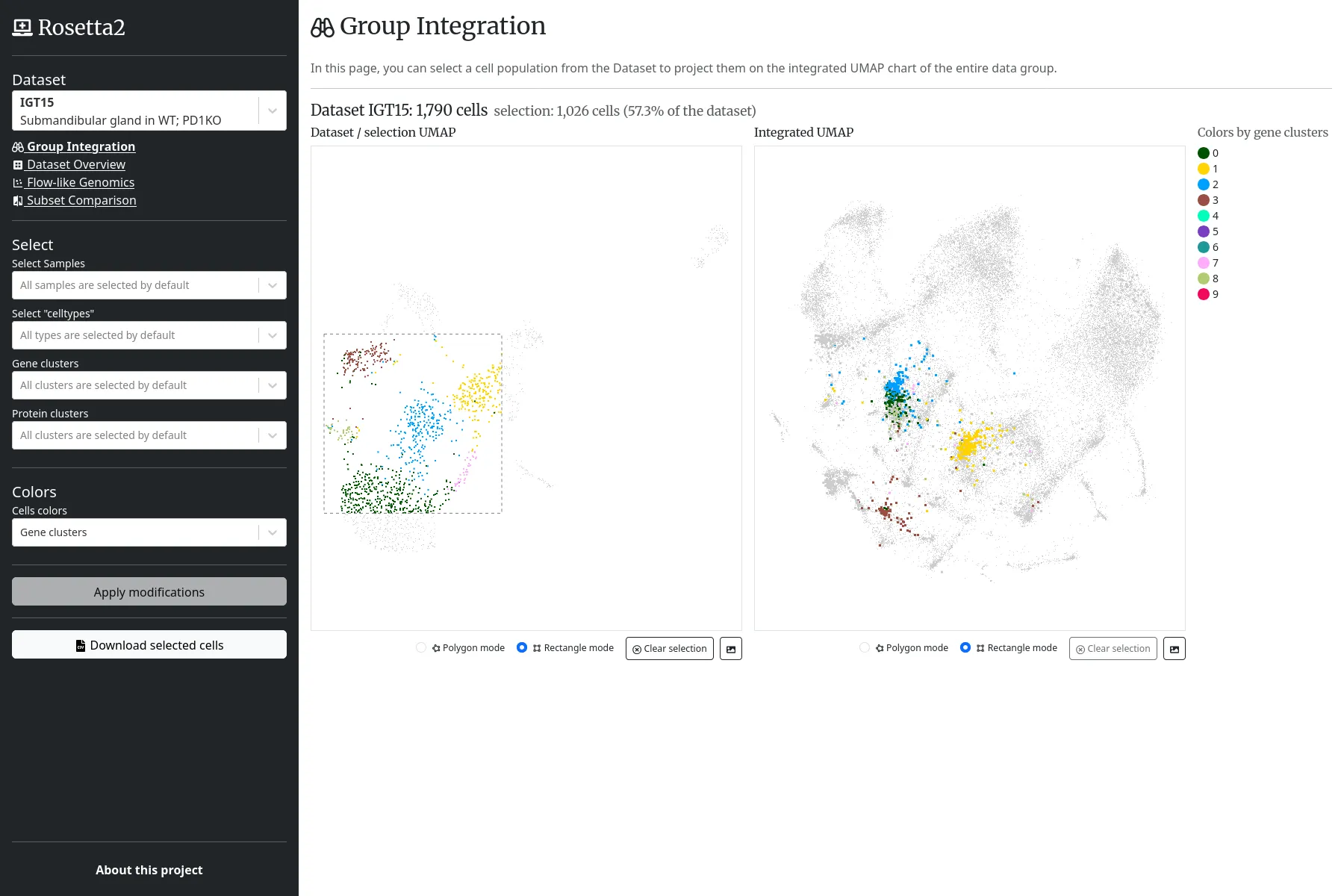
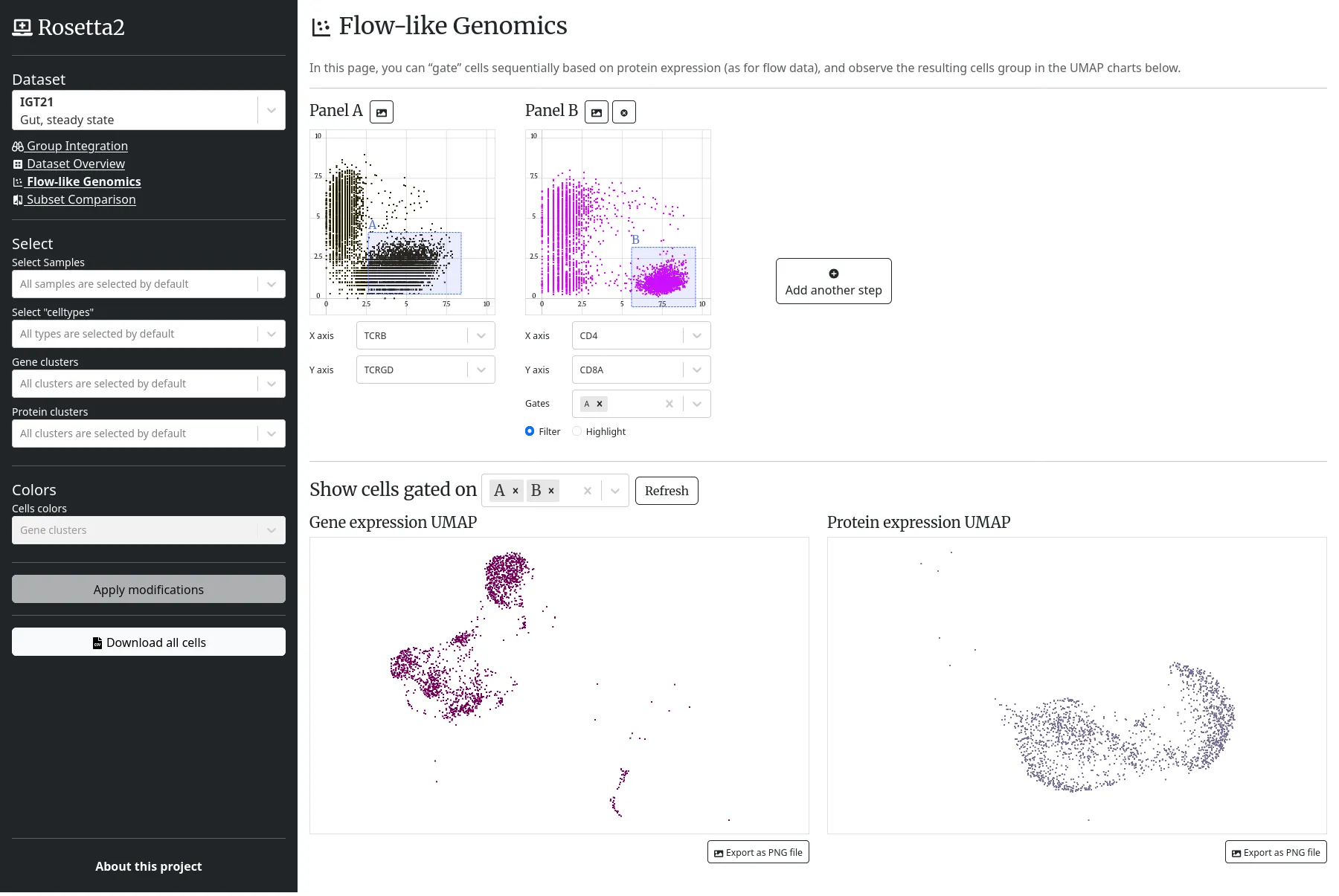

Le projet Immunological Genome (ImmGen) entretient divers outils web d'immunologie et de biologie computationnelle.
Nous accompagnons la Harvard Medical School (HMS) en redéveloppant complétement l'une des applications web du projet ImmGen, Rosetta, anciennement basée sur R Shiny, dédiée à l'exploration de jeux de cellules, suivant leurs expressions géniques et protéiques.
L'application intègre de multiples nuages de points, projections UMAP et cartes de chaleur basés sur canvas. Côté serveur, les cellules et leurs expressions sont indexées dans une base Elasticsearch, et les calculs métiers sont exécutés en Python avec la bibliothèque ScanPy.
Un projet de Développement sur-mesure
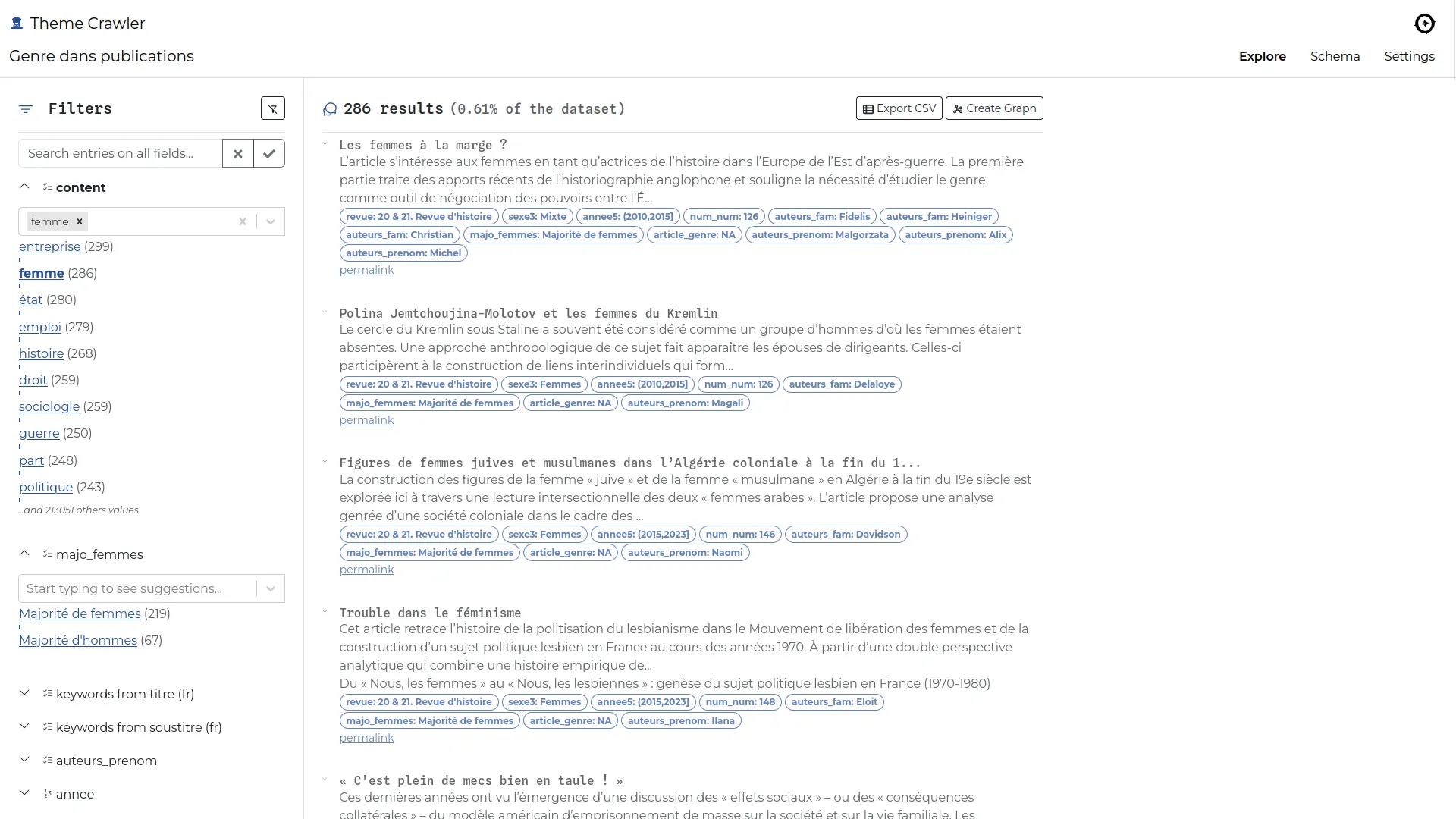
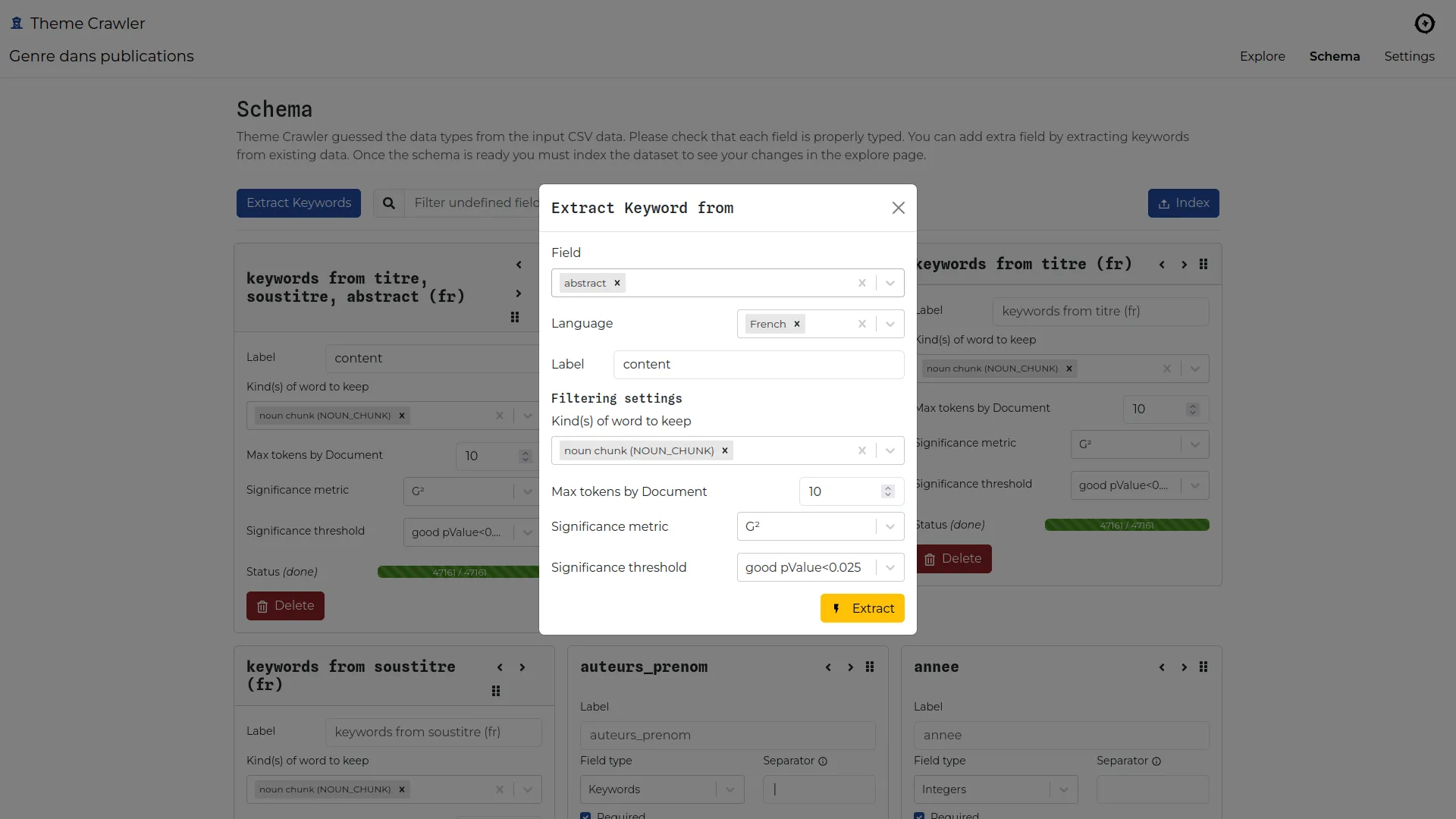
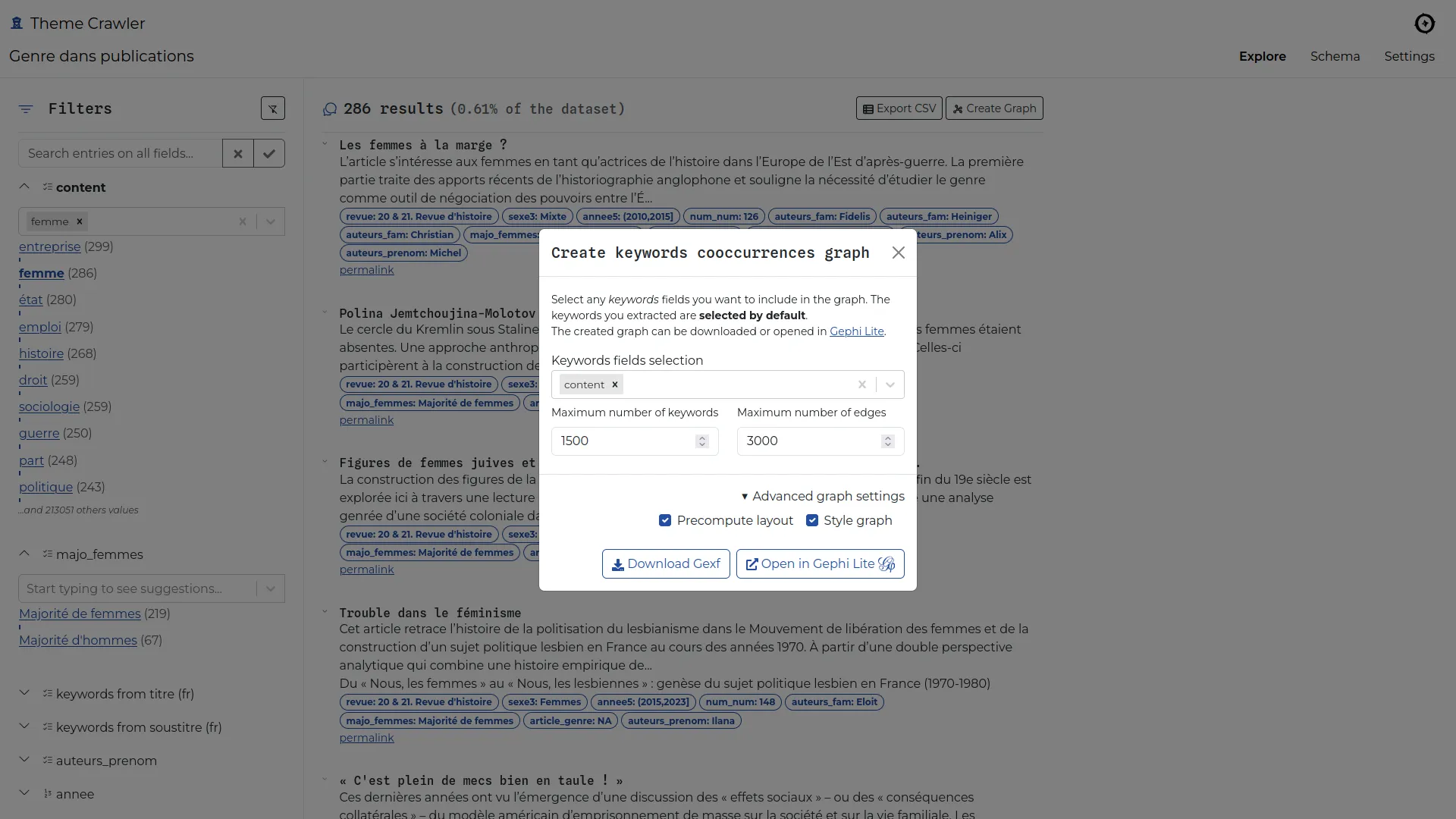
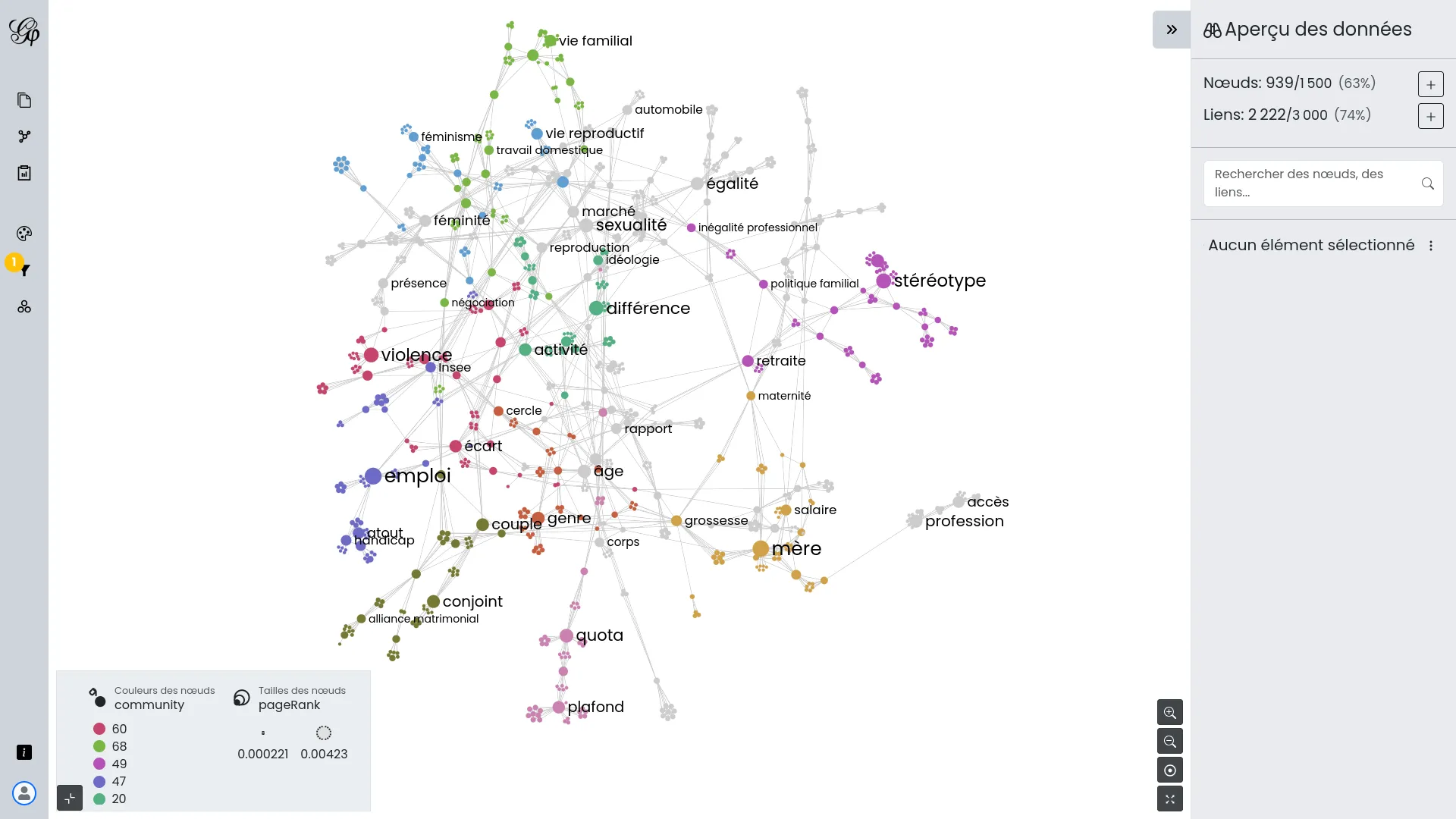
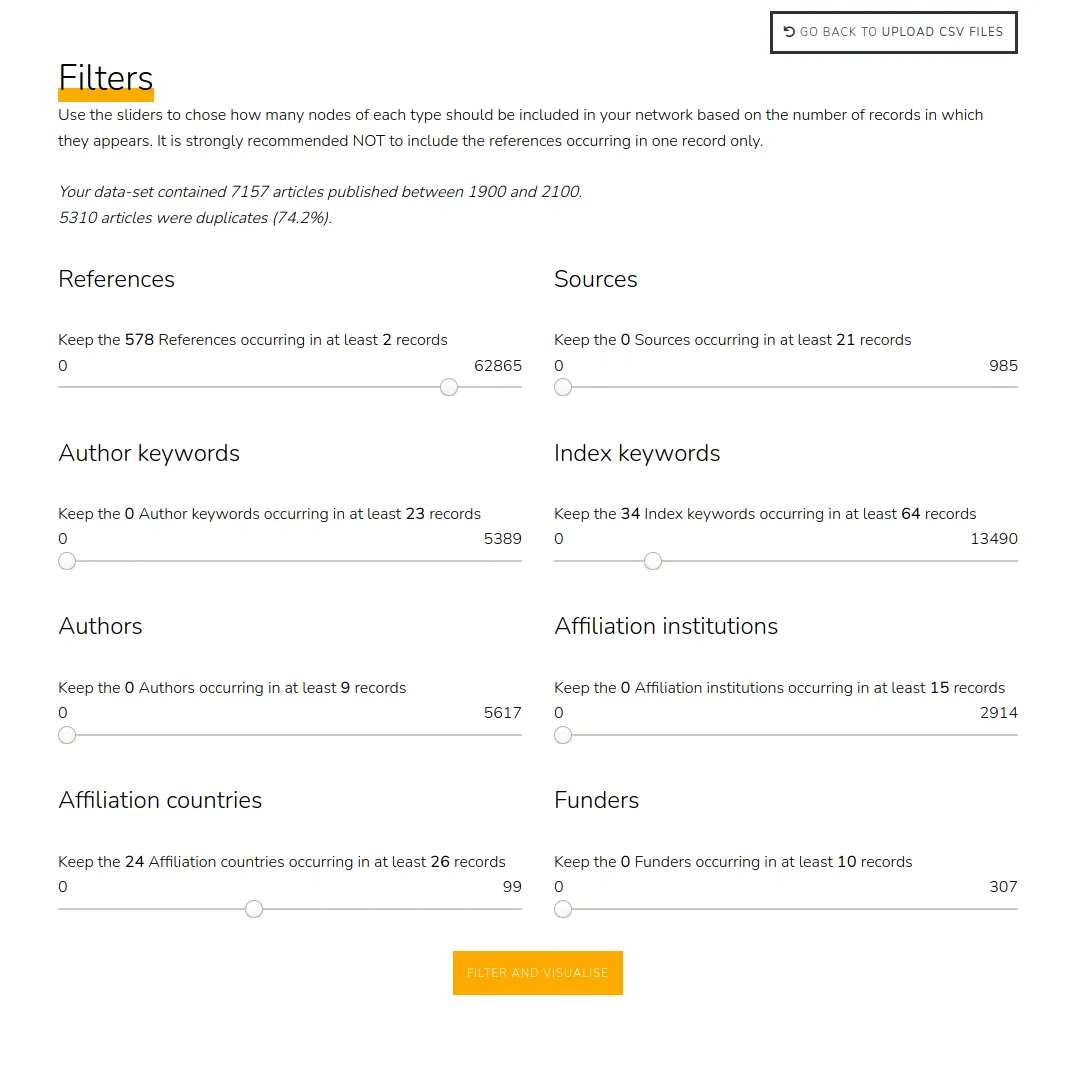
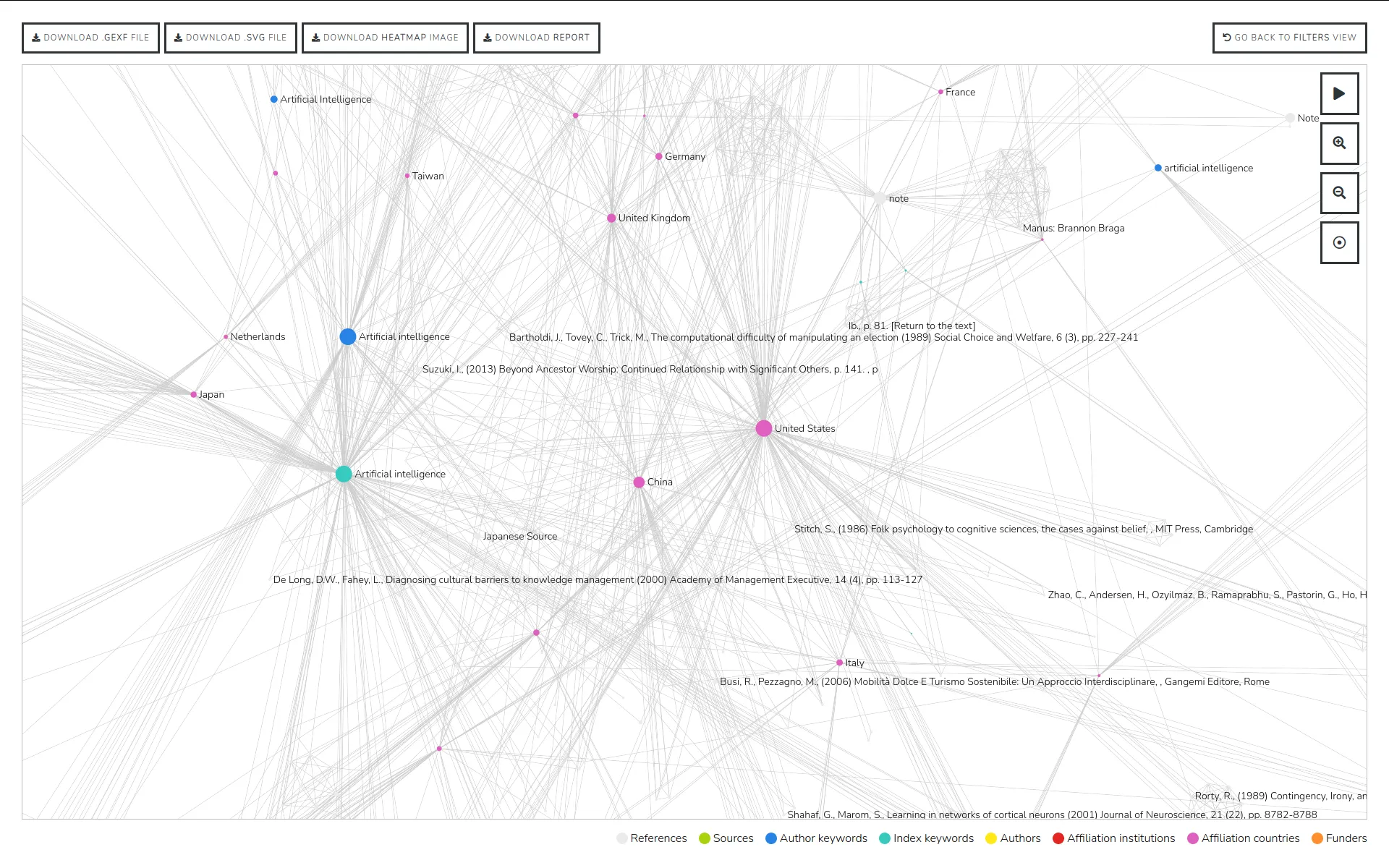
Theme Crawler est un outil d'analyse de co-occurrence de termes développé par Will&Agency pour accompagner leurs consultants dans leurs projets d'analyse des réseaux sociaux. Nous avons collaboré avec eux pour concevoir une nouvelle version, axée sur trois améliorations majeures : une plus grande flexibilité dans l'import des données, une exploration enrichie des métadonnées et de meilleures visualisations de réseaux de co-occurrences.
Notre objectif principal était de permettre l'analyse à partir de toute source de données tabulaires contenant du texte et des métadonnées. Les fournisseurs de données pouvant changer, l'outil devait rester adaptable et compatible avec différents formats.
Une fois un fichier CSV importé, l'outil construit automatiquement un moteur de recherche à facettes à partir des données ingérées. Cela permet aux analystes d'explorer le jeu de données et de lire le contenu de manière plus efficace.
Tous les fournisseurs n'incluent pas d'analyse sémantique dans leurs exports, et lorsqu'ils le font, les résultats manquent souvent de précision. Pour répondre à ce besoin, nous avons ajouté une fonctionnalité d'extraction de mots-clés, permettant aux analystes de générer des extractions sémantiques à partir de n'importe quelle colonne de texte en utilisant spaCy.
Les réseaux de co-occurrences peuvent désormais être construits à partir de n'importe quelle colonne de mots-clés et ouverts dans Gephi Lite via son API broadcast. Cette intégration offre un accès à une plateforme complète de visualisation de réseaux, sans nécessiter de développement supplémentaire.
Un projet de Développement sur-mesure
La première rencontre publique de la communauté OpenRail Association, dont fait parti le projet OSRD.
Paris, France
Un événement interne à la SNCF présente les différents outils métier d'OSRD aux premiers utilisateurs.
Paris, France
Un événement organisé par l'équipe d'OSRD pour annoncer les premiers utilisateurs industriels du projet.
Paris, France
Alexis Jacomy
Bruxelles, Belgique
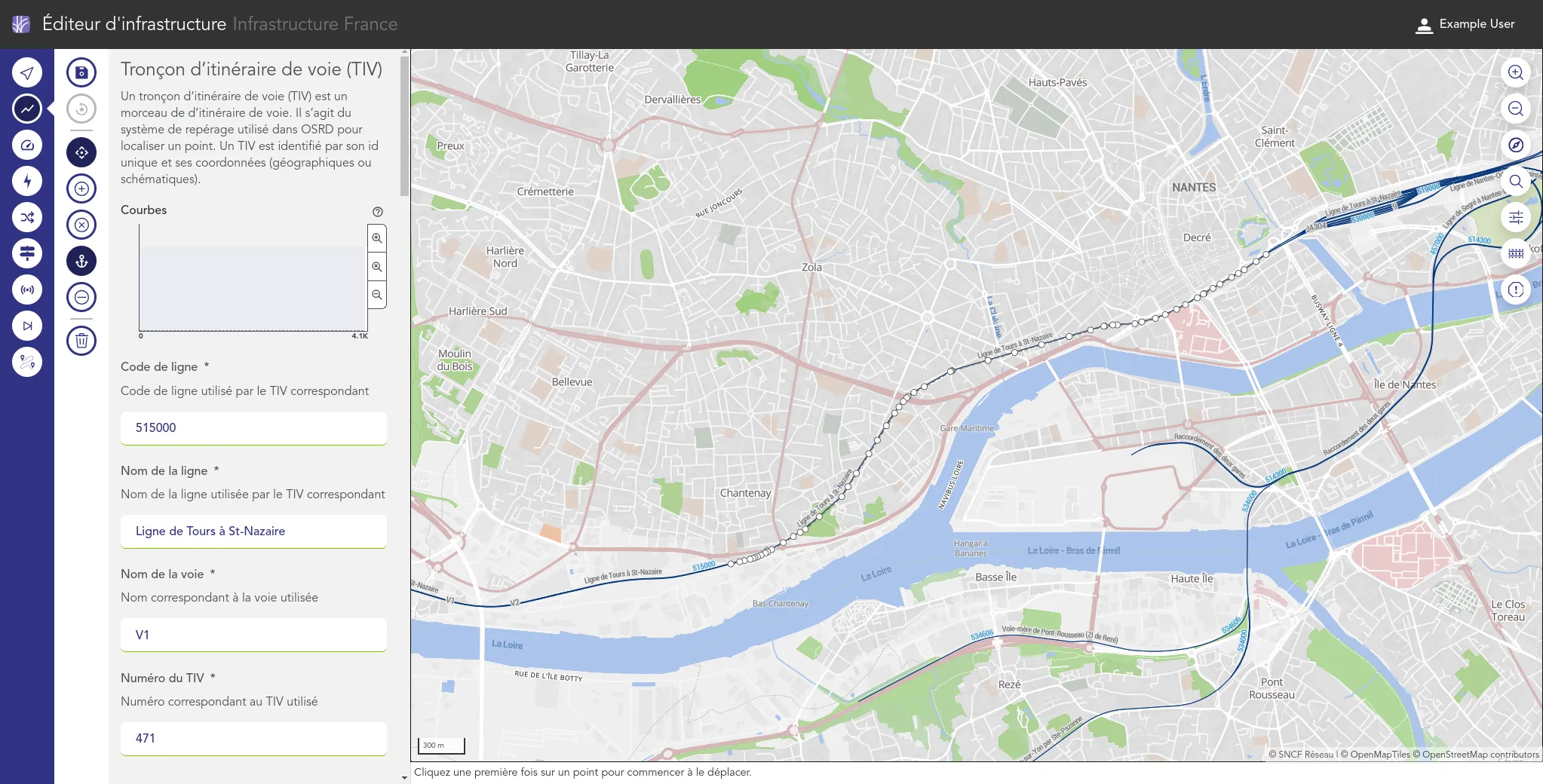
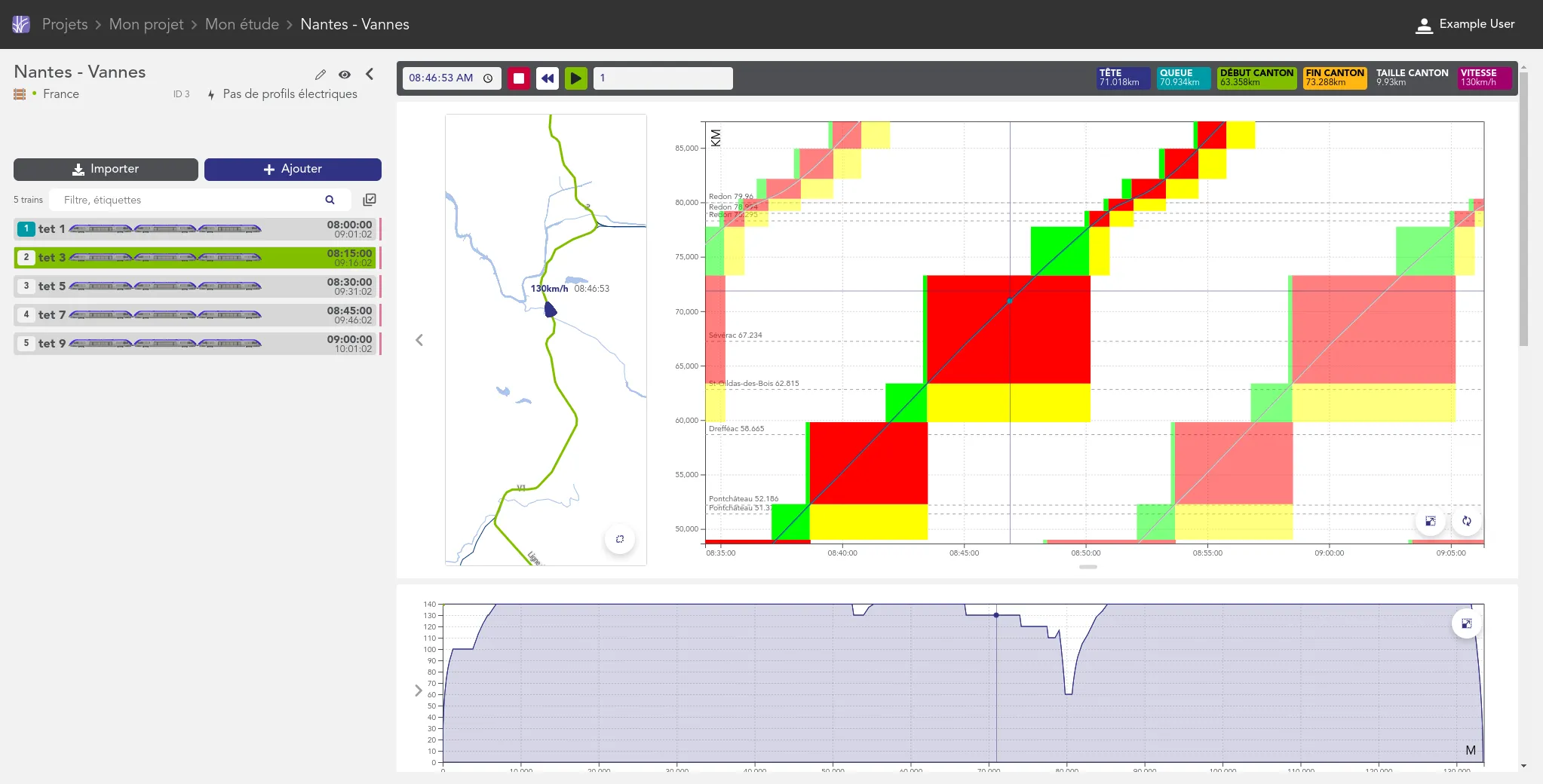
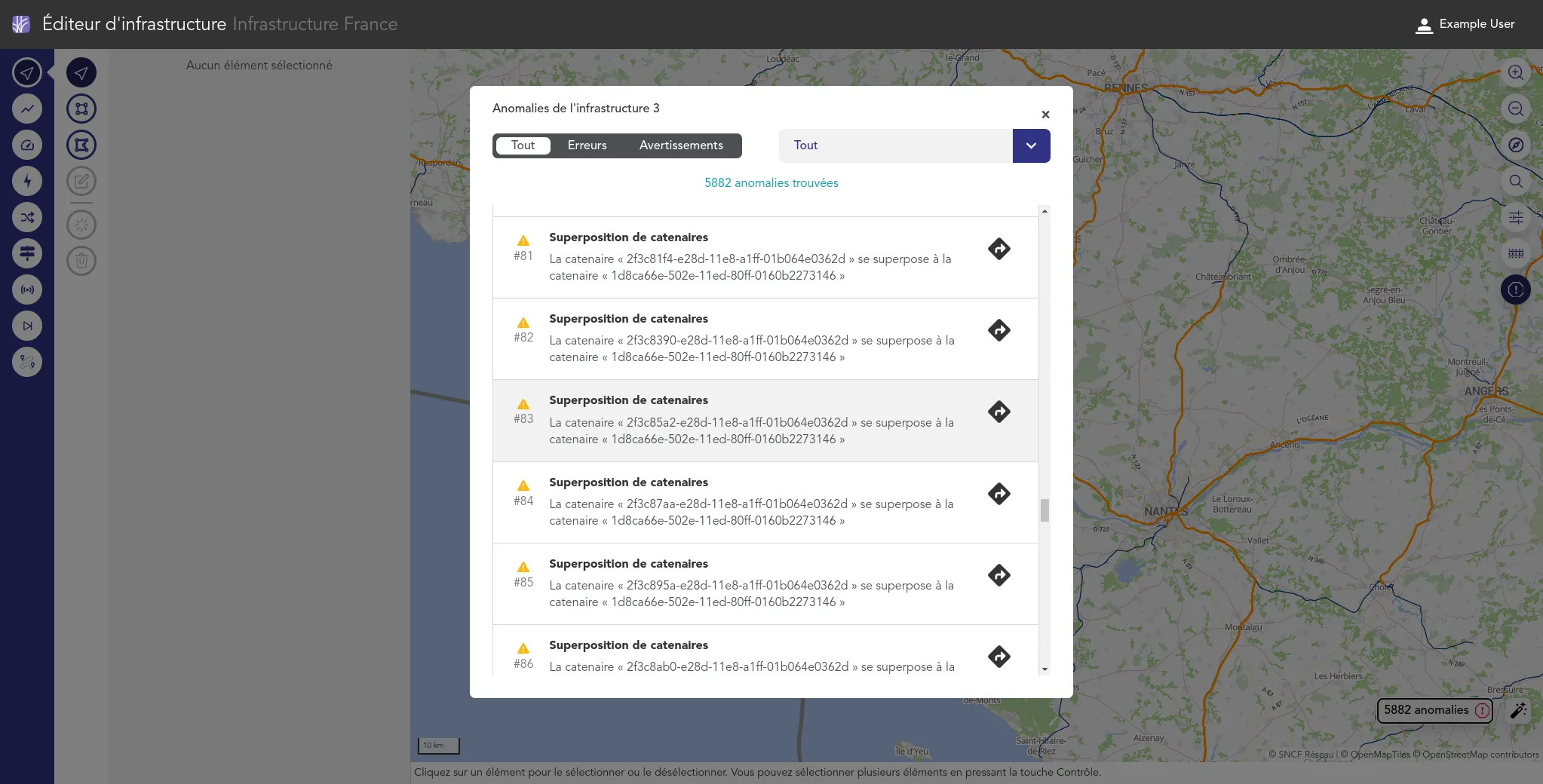

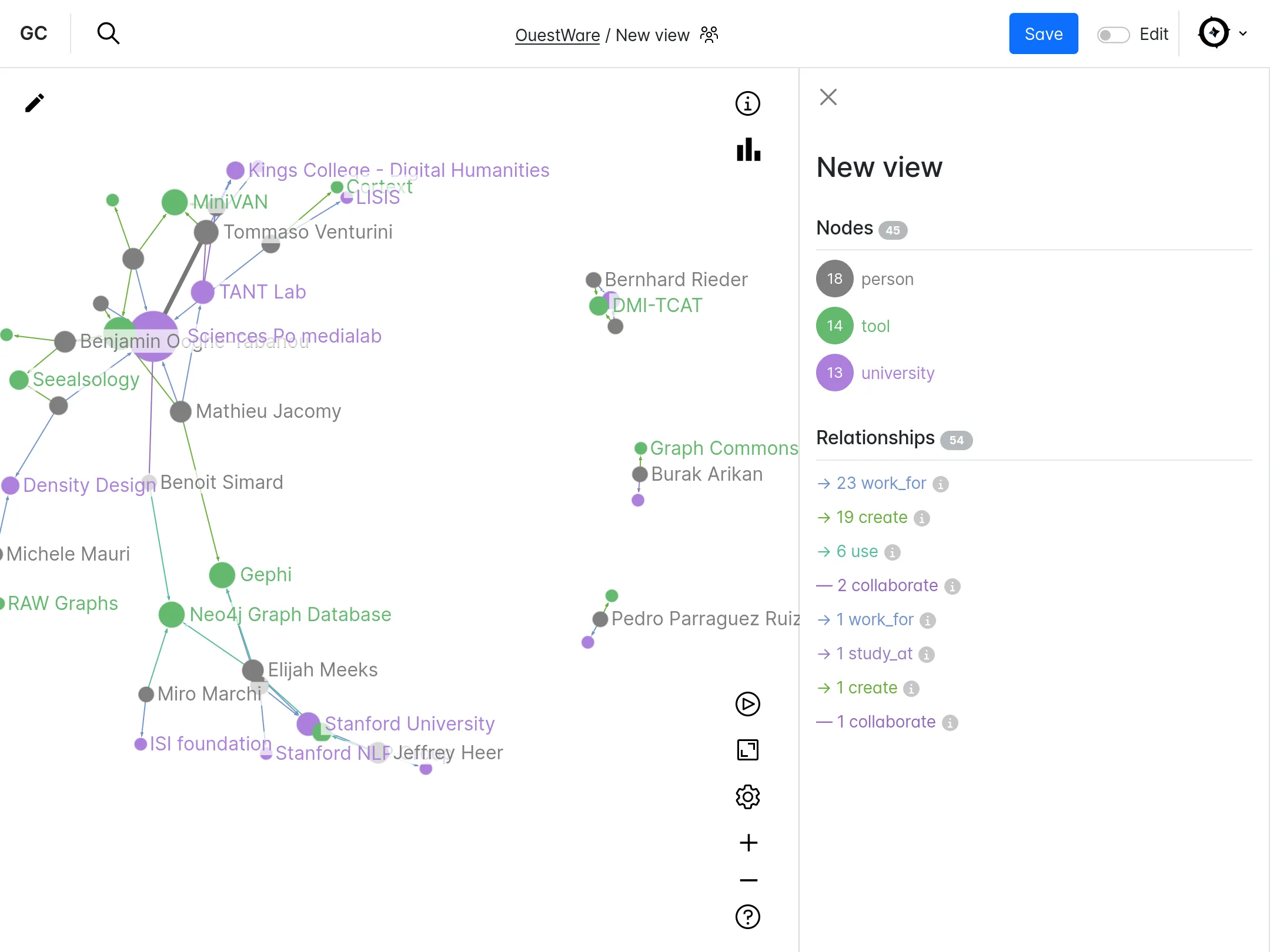
Nous accompagnons les équipes du projet OSRD en participant au développement d'une application web Open Source rassemblant divers outils d'édition et de gestion d'une infrastructure ferroviaire. Nous intervenons plus particulièrement sur les interfaces web permettant l'édition de l'infrastructure dans un outil cartographique avancé. Nous intervenons également sur certaines briques de visualisation comme le graphique espace-temps.
Si ce projet est centré pour le moment sur l'infrastructure française il a pour vocation à terme à être utilisable dans d'autres contextes. Il fait à ce titre partie de la OpenRail Association qui coordonne les efforts transnationaux de convergence des outils open source ferroviaires.
Un projet de Code et Données ouvertes
On se rencontre avec la communauté Gephi. Benoit aide à mettre à jour le connecteur Neo4J, Alexis aide à développer un plugin pour l'export Retina, et Paul aide à faire avancer les spécifications du format GEXF. Aussi, on commence à imaginer Gephi Lite.
Paris, France
On accueille la communauté Gephi dans les locaux de UmaniT. On en profite pour redévelopper le site web de Gephi, pendant que Benoît travaille avec Matthieu Totet sur Gephipy, un wrapper Python autour du Gephi Toolkit.
Nantes, France
On se rencontre avec les développeurs de Gephi. On intègre la métrique connected-closeness dans Gephi Lite. On planifie tous ensemble la mise à jour du site web de Gephi, et on debug Gephi Lite.
Copenhague, Danemark
On se rencontre avec Mathieu Jacomy, Guillaume Plique, Benjamin Ooghe-Tabanou, Andrea Benedetti et Tommaso Elli pour travailler ensemble sur des méthodes d'évaluation de l'incertitude dans les algorithmes de détection de communautés dans les graphes.
Paris, France
Paul Girard, Alexis Jacomy et Benoit Simard
Bruxelles, Belgique
Alexis Jacomy et Arthur Desaintjan
Bruxelles, Belgique
OuestWare et Public Data Lab
Paul Girard, Alexis Jacomy, Benoit Simard et Mathieu Jacomy
Lisbonne, Portugal
Mathieu Jacomy, Tommaso Elli, Andrea Benedetti, Guillaume Plique, Benjamin Ooghe-Tabanou, Paul Girard et Alexis Jacomy
Belval, Luxembourg
C'est surtout de la maintenance, mais aussi on peut afficher des images dans les noeuds.
Cette version introduit principalement la recherche dans le graphe ainsi que la légende. Plus d'info dans ce fil Twitter.
Première sortie "publique" après un sprint dédié à rendre cette première version aussi utilisable que possible.
Le premier prototype de Gephi Lite qui fonctionne. Sortie plutôt confidentielle.
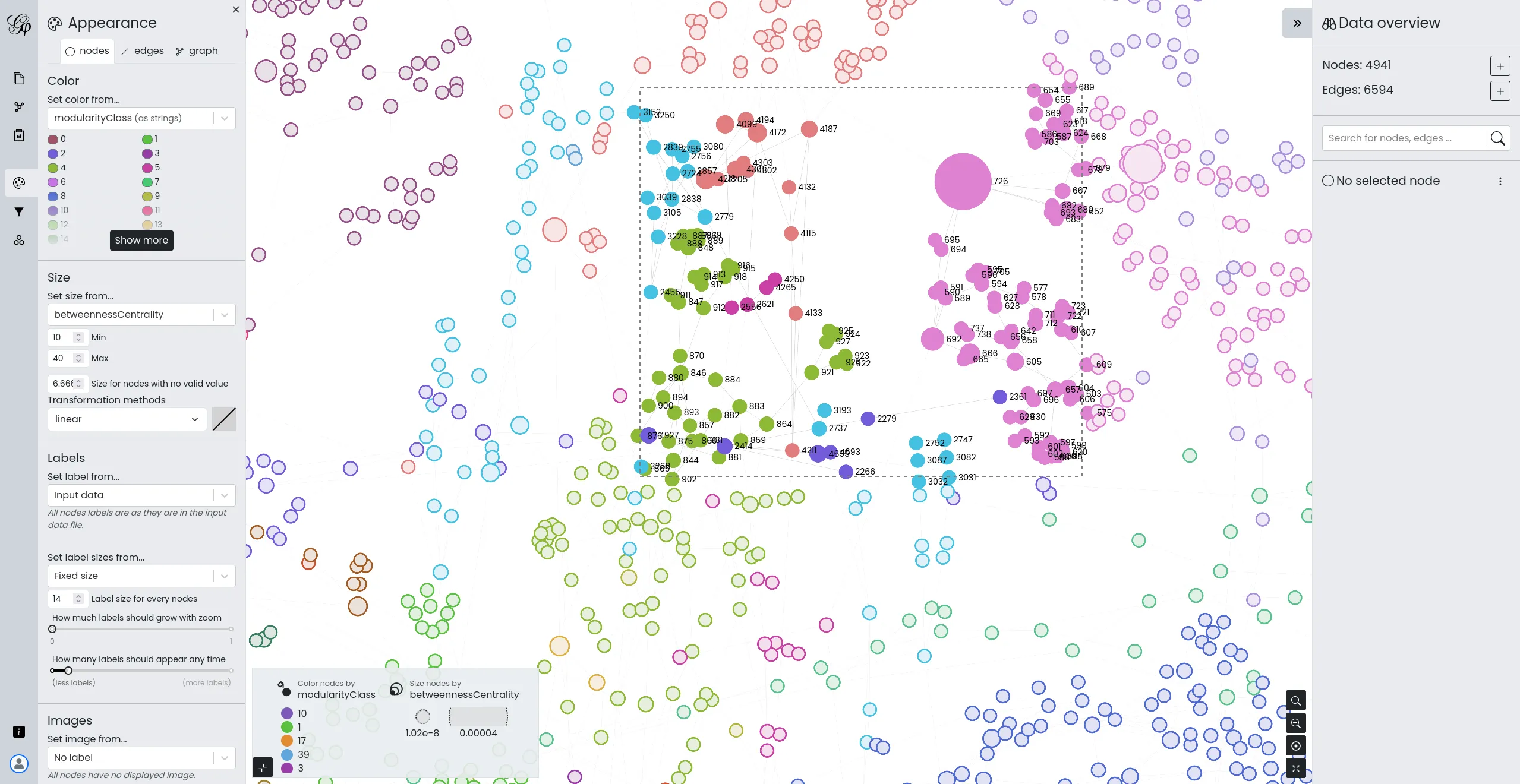
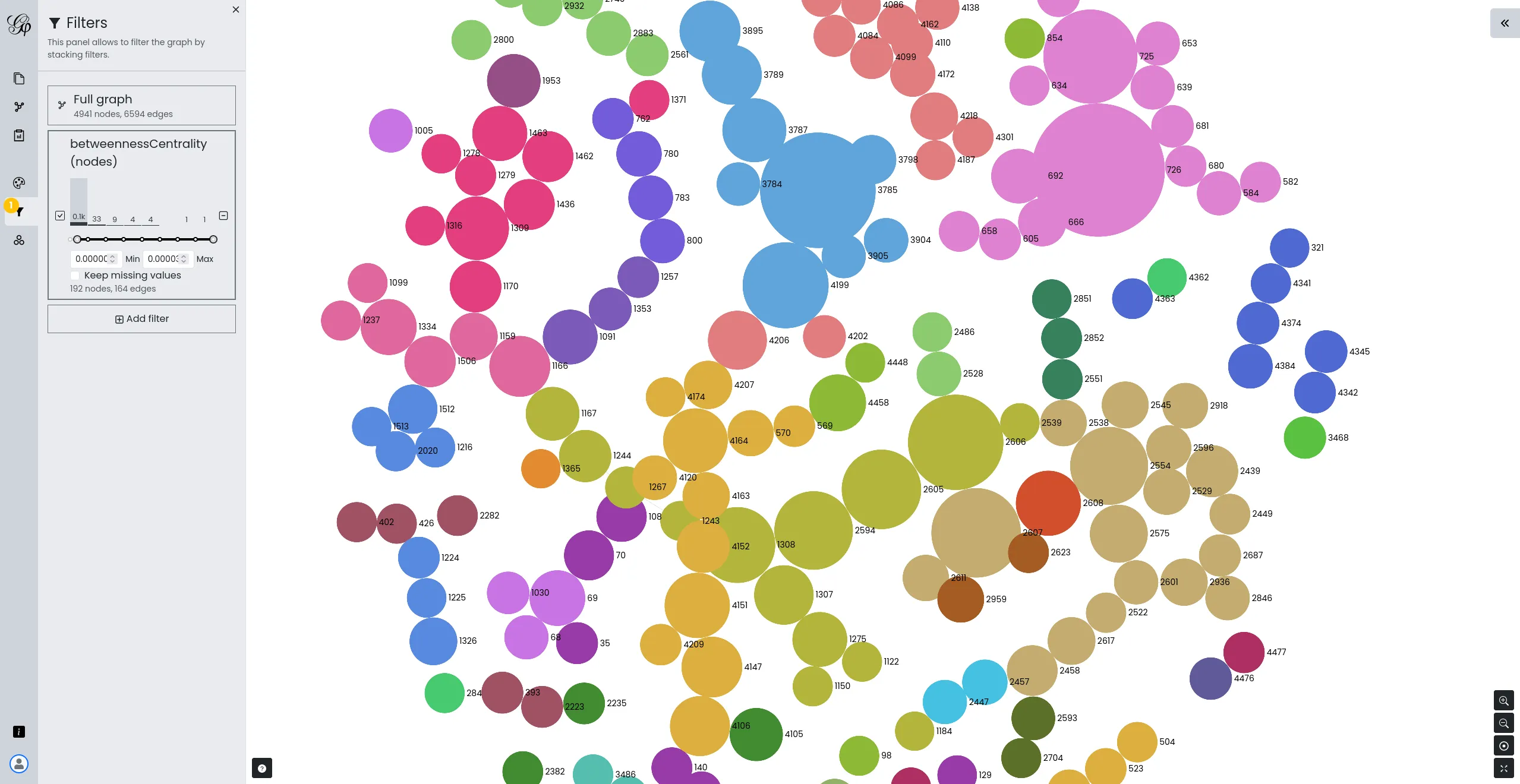
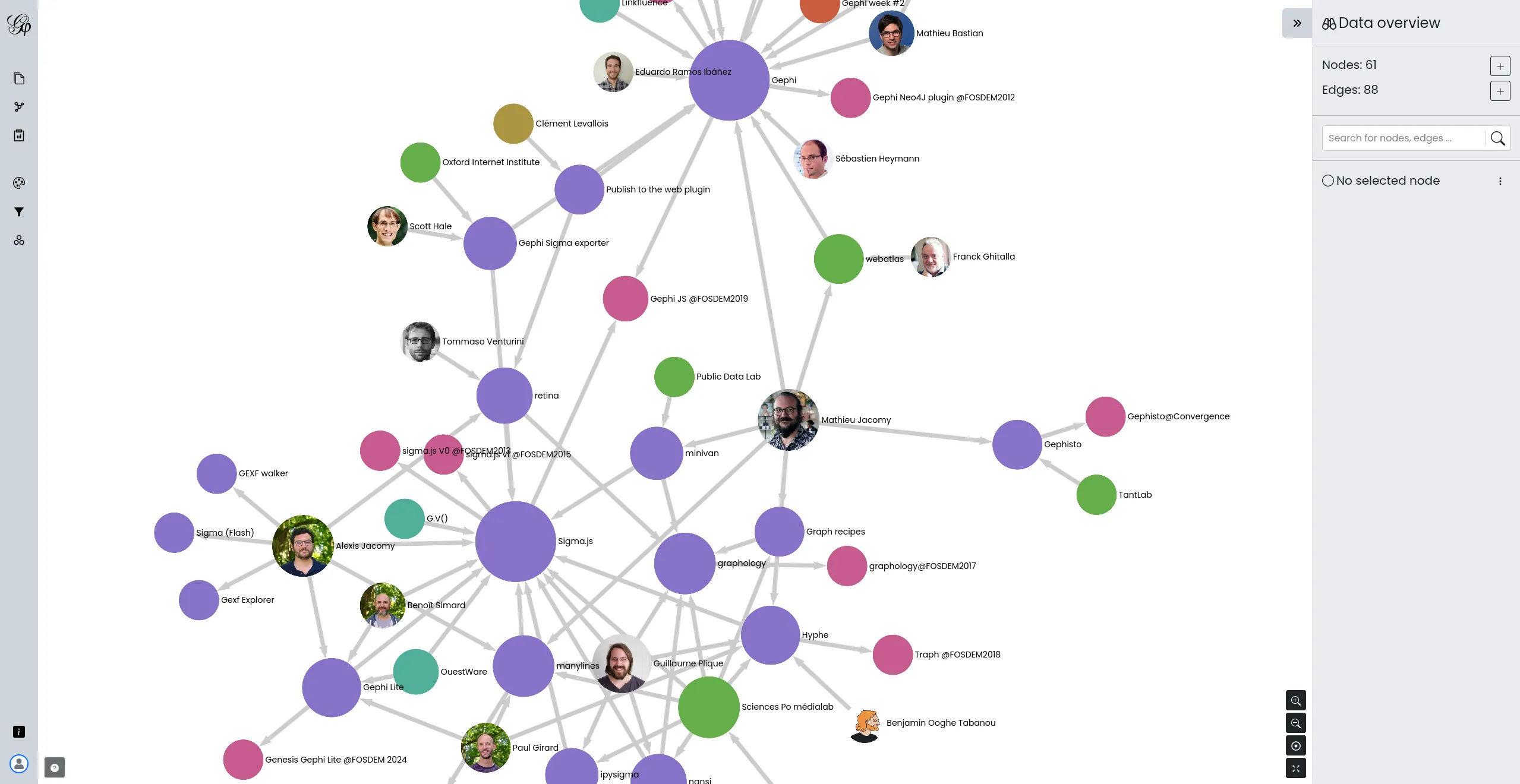

Développer une version web et allégée de Gephi
Nous avons pris en charge le développement de Gephi Lite, une initiative visant à créer une version allégée et plus accessible du célèbre outil d'analyse de réseaux, Gephi. Notre équipe a conçu et développé Gephi Lite pour répondre à une demande croissante d'outils d'analyse de réseaux sociaux simples d'utilisation, sans sacrifier la profondeur des analyses.
Ce projet, réalisé grâce à notre expertise approfondie en matière de visualisation de données et de développement d'applications web de cartographies de réseaux, souligne notre engagement envers le développement open-source et le soutien aux communautés académiques et de recherche.
Un projet de Code et Données ouvertes
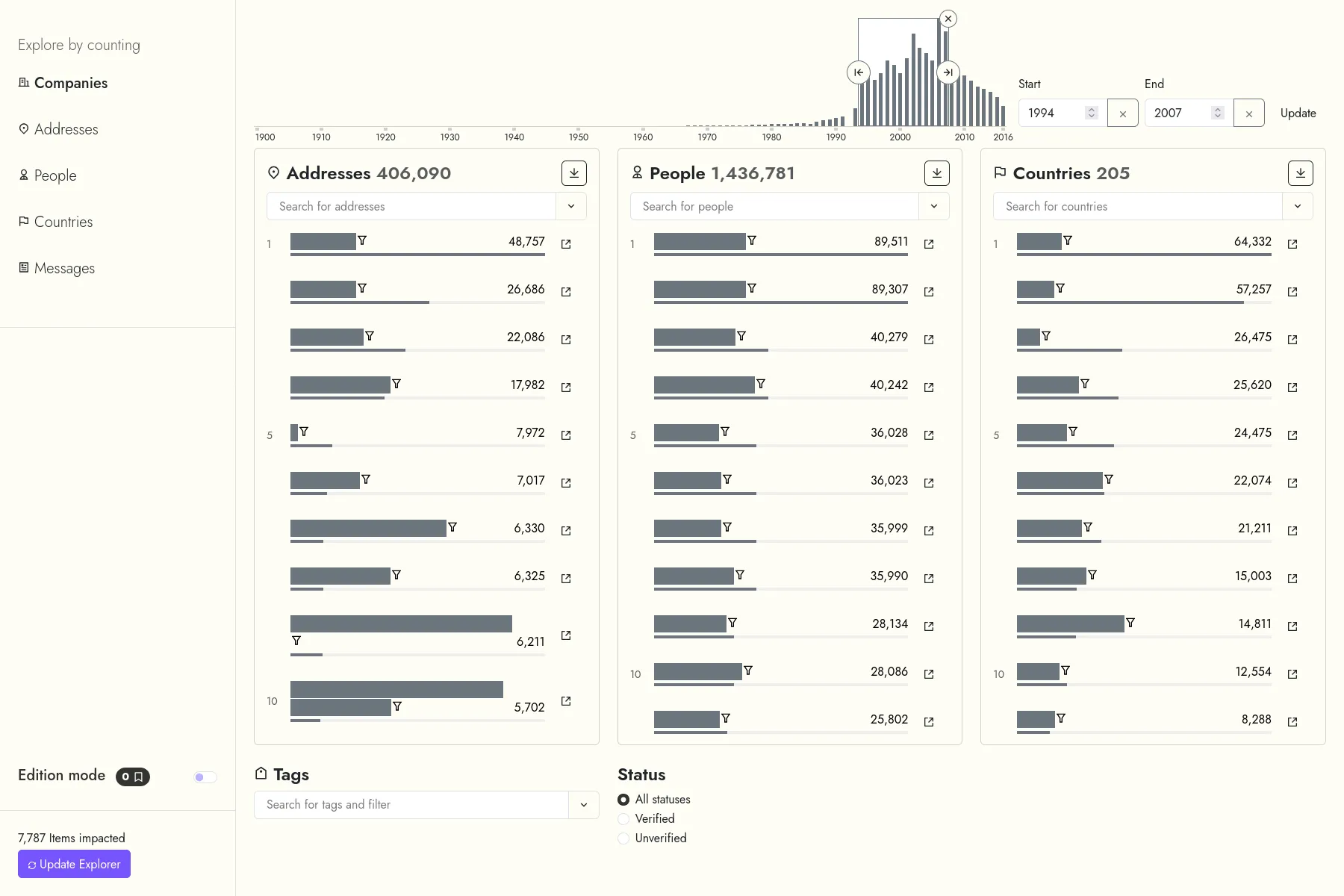
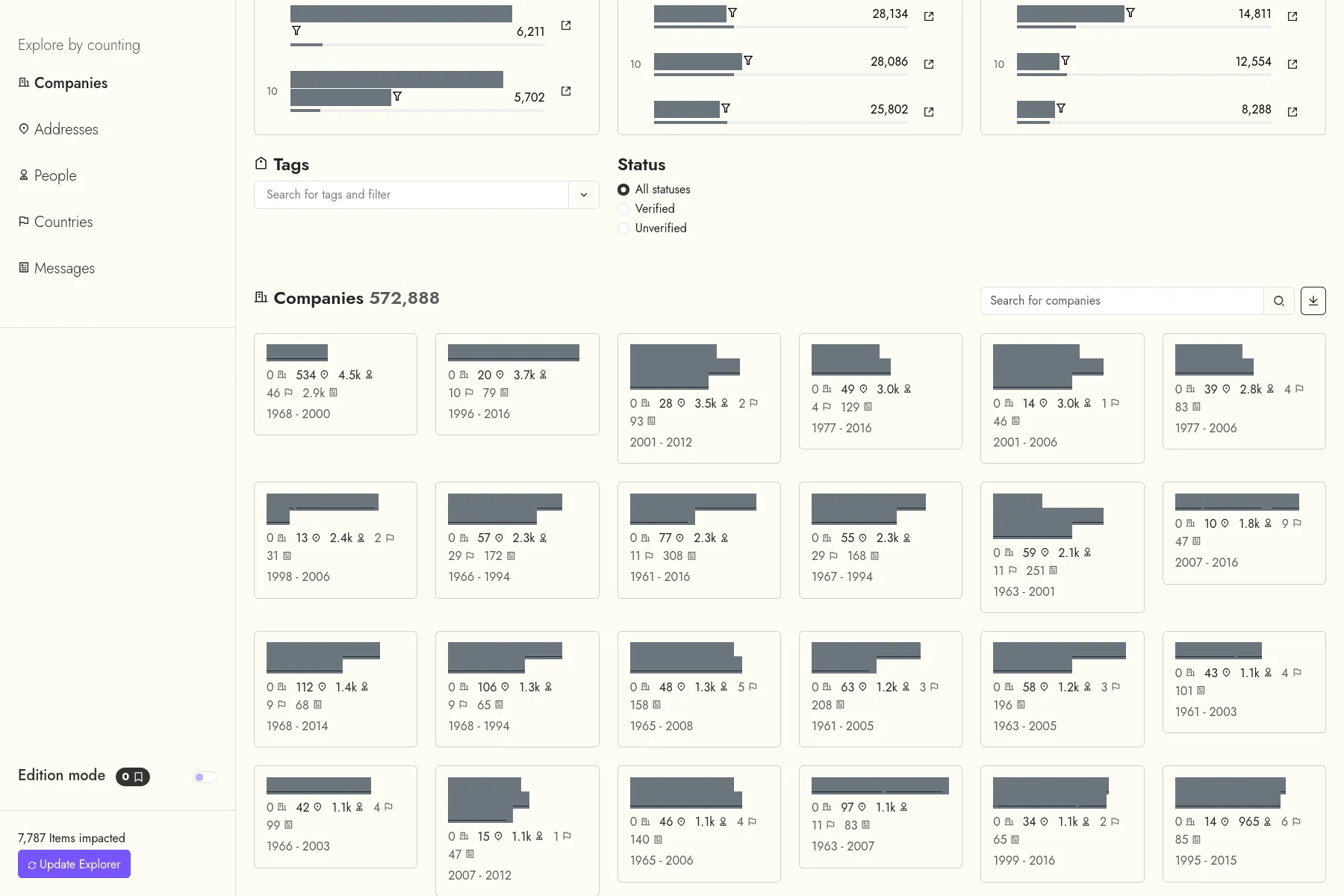
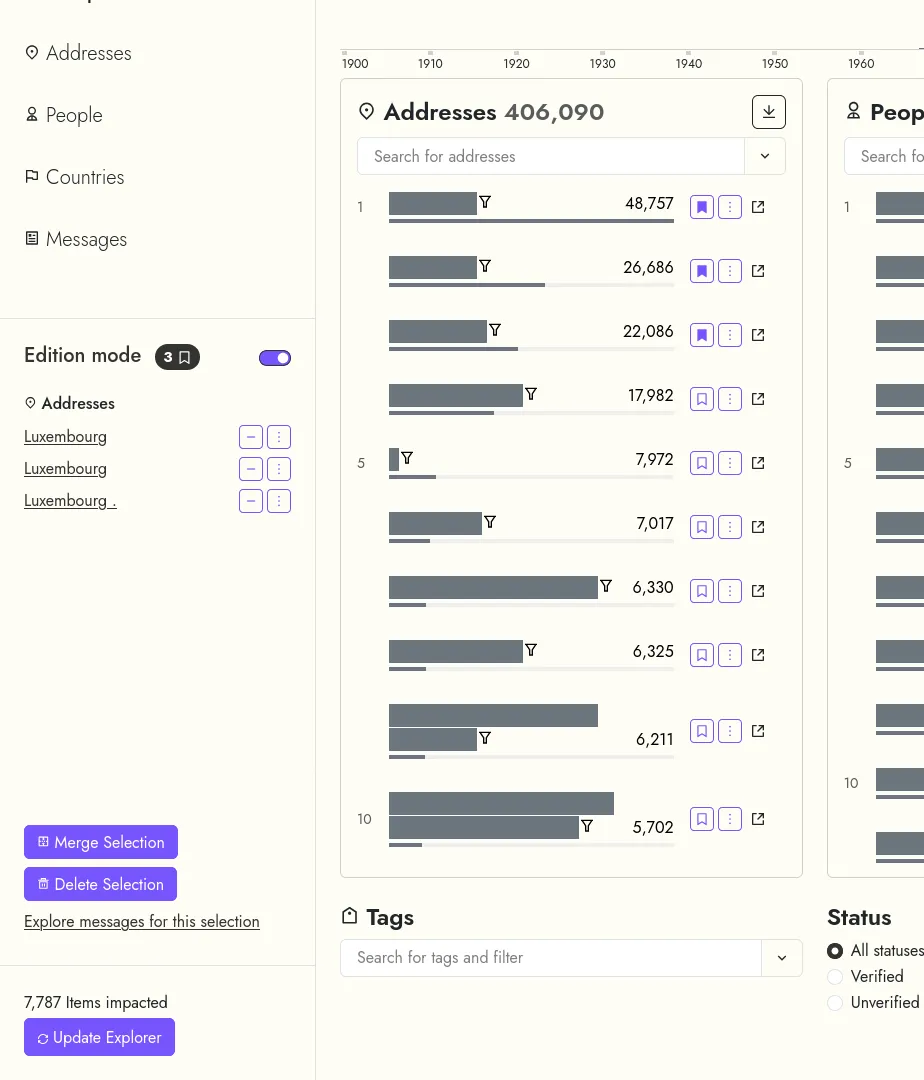

Le projet LETTERBOX, porté par l'Université du Luxembourg, vise à exposer l'infrastructure des sociétés écrans au Luxembourg, en utilisant des méthodes numériques normalement utilisées par des historiens.
Dans ce cadre, nous avons développé une application Web pour aider les chercheurs du projet. L'application permet d'une part d'explorer un corpus de données extraites du journal officiel du Luxembourg, et formé de compagnies, de personnes, d'adresses et de pays. D'autre part, elle permet aux chercheurs à modifier les données extraites, par exemple en réunissant deux entités nommées différemment mais qui représentent en fait la même compagnie, ou encore en corrigeant des erreurs d'extraction des données.
Les données sont indexées à la fois dans une base Elasticsearch - qui permet de la recherche floue dans les extraits textuels originels, et dans une base Neo4j - qui permet d'explorer le réseau des relations entre les compagnies, personnes, adresses, pays...
Un projet de Développement sur-mesure
Mathieu Jacomy, Matilde Ficozzi, Anders K. Munk, Dario Rodighiero, Johan I. Søltoft, Sarah Feldes, Ainoa Pubill Unzeta, Barbara N. Carreras et Paul Girard
Lisbonne, Portugal
Ouverture de l'exposition Grounding AI au Danmarks Teknisk Museum.
Helsingør, Danmark

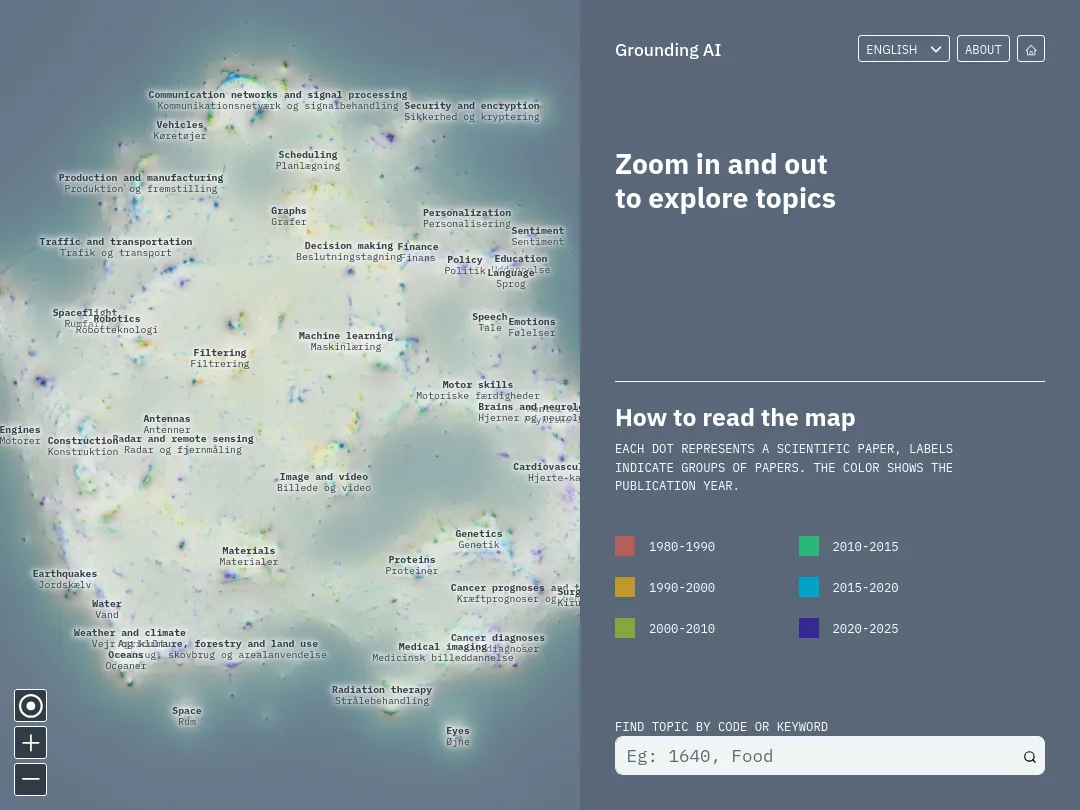
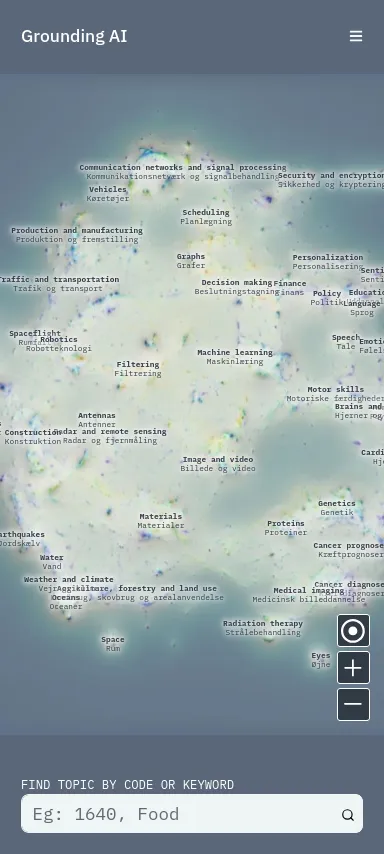



Le projet Grounding AI est un projet de recherche, visant à cartographier comment la littérature scientifique mentionne les algorithmes, l'apprentissage automatique, ou encore l'intelligence artificielle.
Un des volets de ce projet a consisté en la construction d'une cartographie, imprimée sur 100m² de vinyle, et exposée au Musée technique du Danemark. La carte a été construite ainsi :
Notre rôle a été de développer une application web mobile pour accompagner cette carte physique. Cette application, au design réactif, permet au visiteurs de l'exposition :
Techniquement, l'application est développée en TypeScript avec React, avec des indexes montés dans le navigateur directement pour la recherche. Les données étant assez compactes, l'application est entièrement servie par GitHub Pages comme un site statique, et son processus de build est entièrement intégré dans les GitHub Actions.
Un projet de Valorisation de données
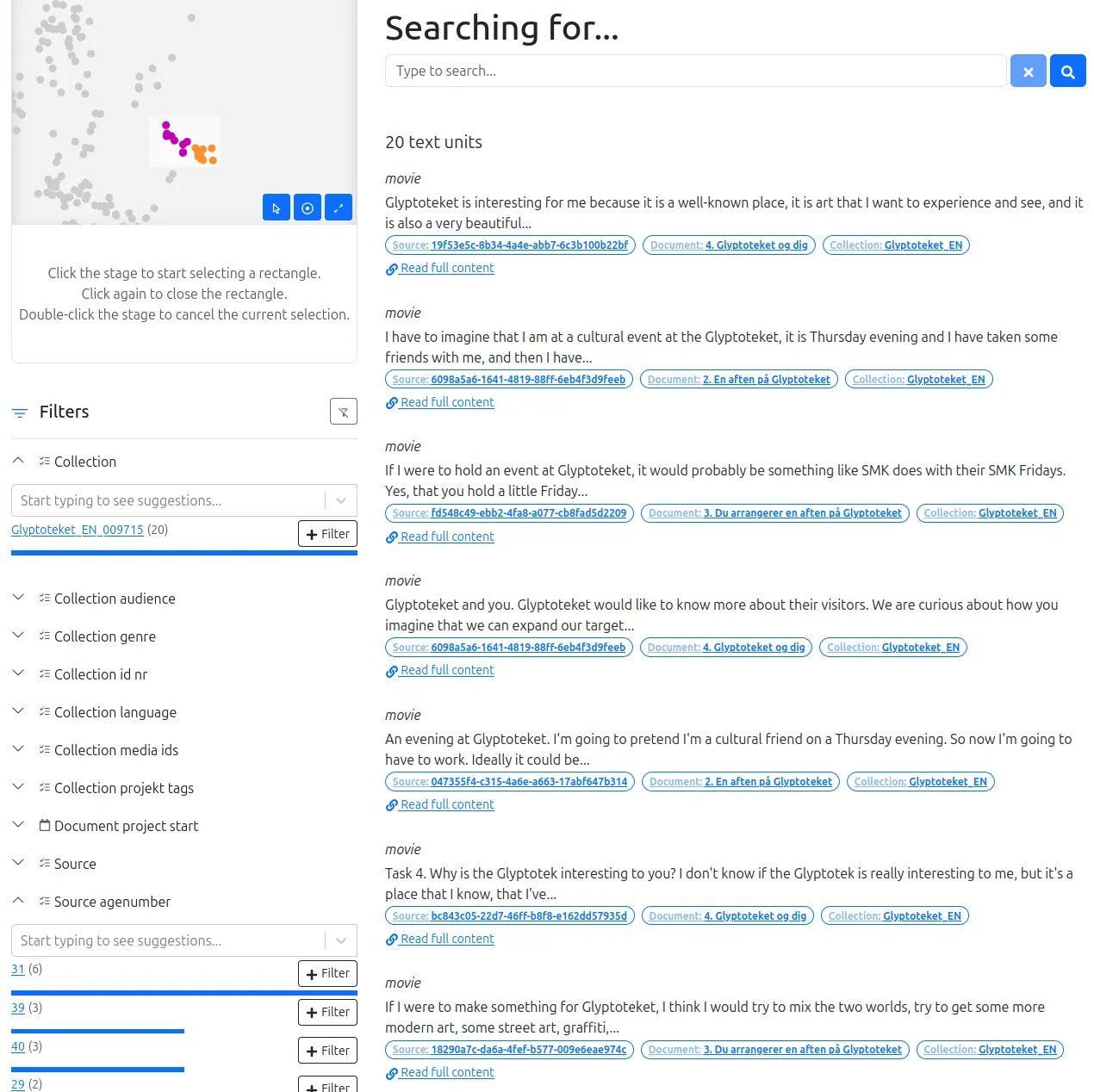
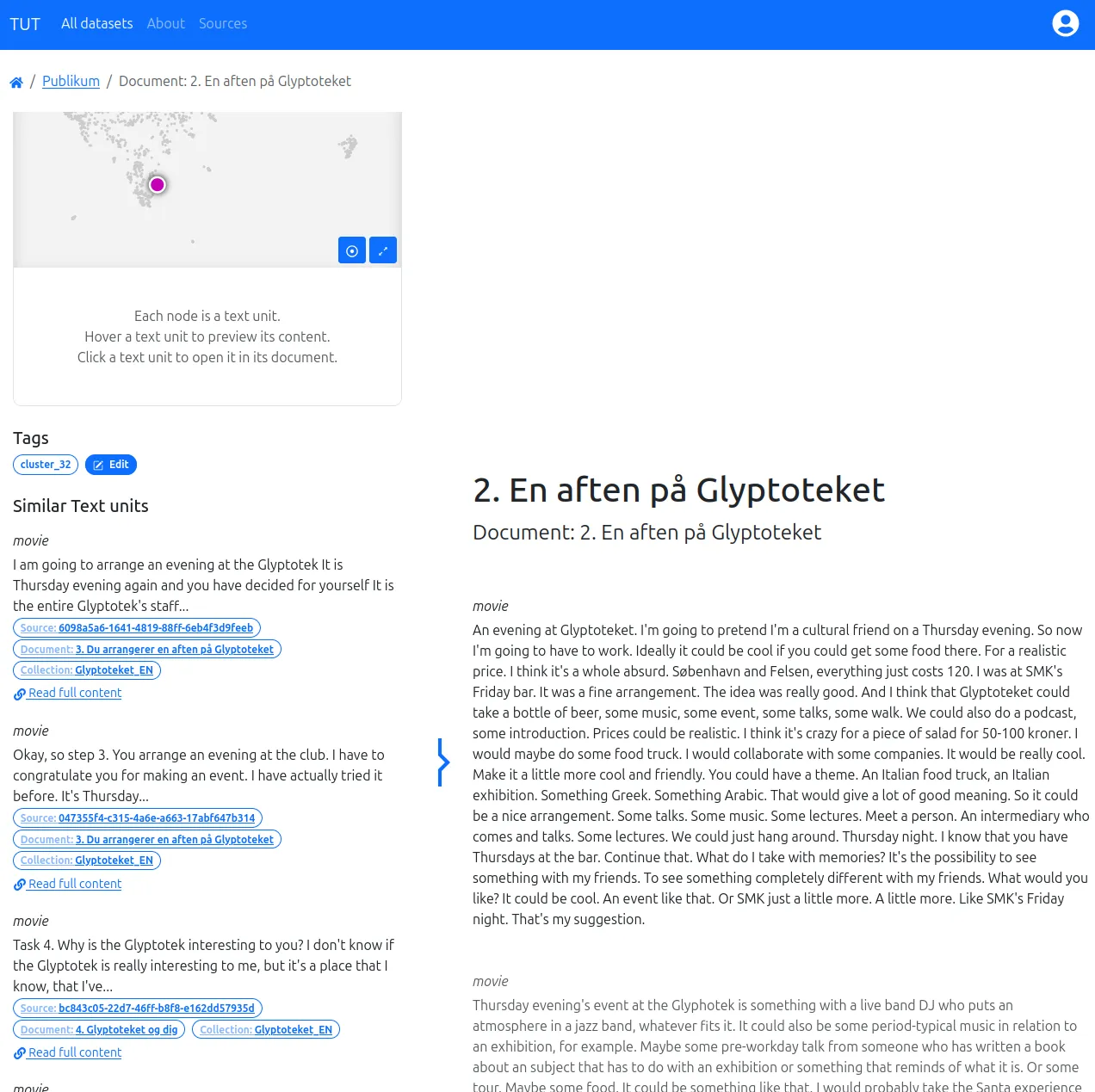

Text Unit Tool (TUT), développé avec des laboratoires et entreprises danois, est un outil d’exploration de grands corpus textuels. Il combine approches qualitative et quantitative en associant filtrage par métadonnées et analyse par plongement de mots.
Cette application web permet de créer un moteur de recherche à facettes à partir d’archives de courts textes (idéalement des paragraphes), structurés en documents, sources et collections. Les textes sont analysés automatiquement par un modèle de plongement, générant une carte de proximité et identifiant les textes similaires.
TUT rend ainsi accessibles à des non-spécialistes des méthodes d’analyse quantitative avancées, facilitant la navigation dans de vastes corpus.
Un projet de Développement sur-mesure
Séminaire Reg⋅Arts sur les visualisations de données.
INHA, Paris
Paul Girard
Lisbonne, Portugal
Soirée de lancement de la base de données Reg⋅Arts
Palais des Beaux-Arts, Paris
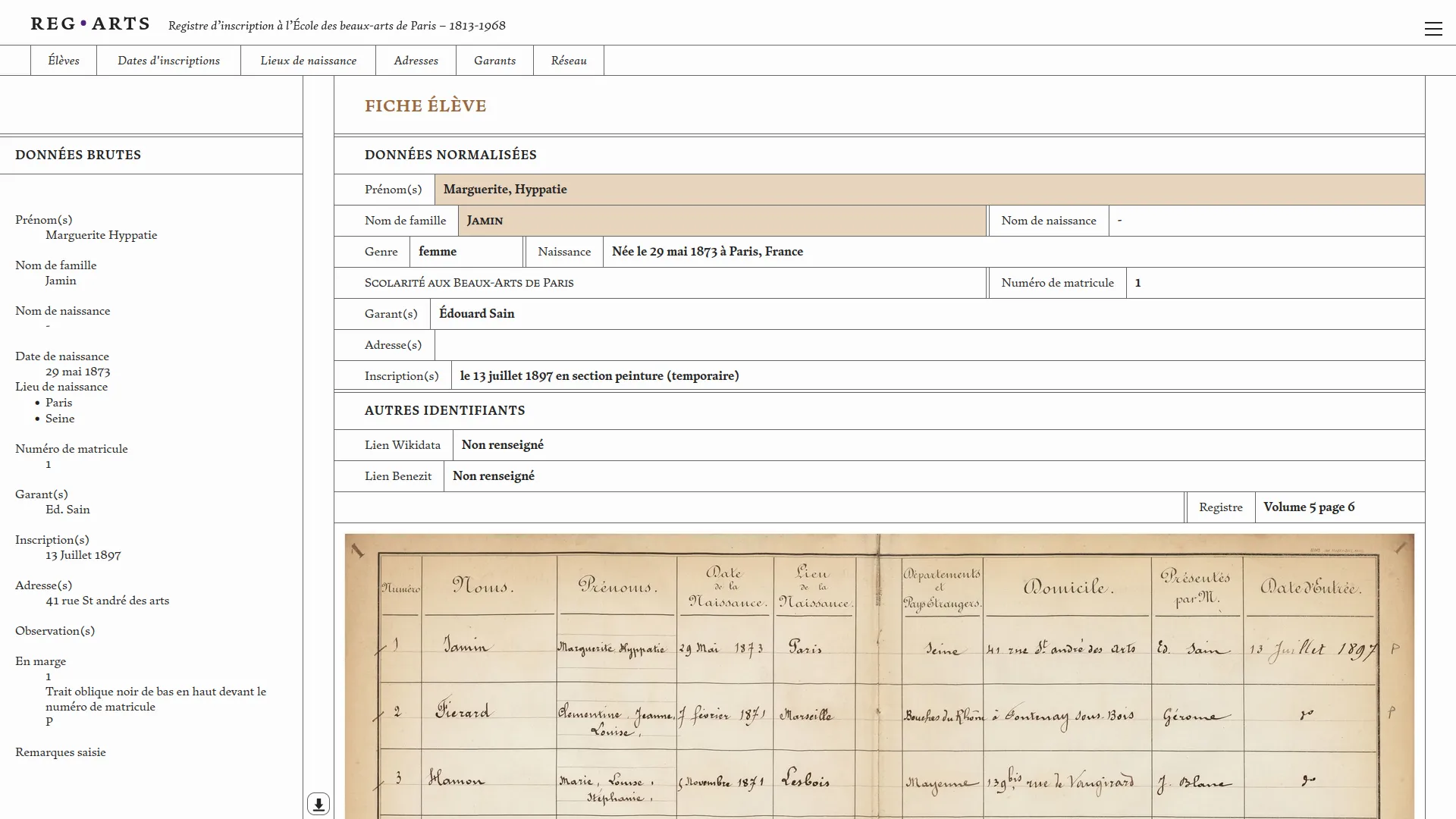
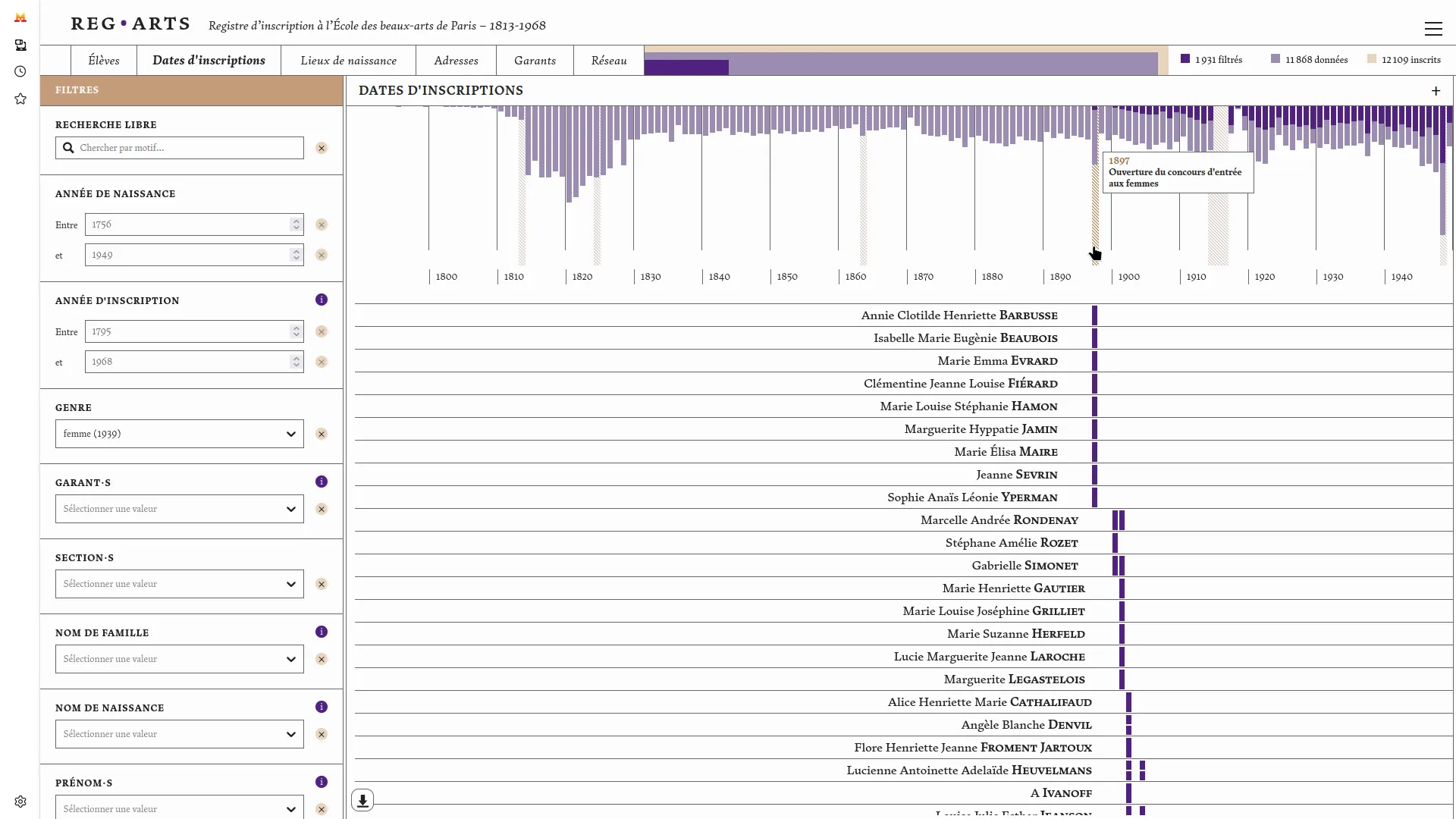
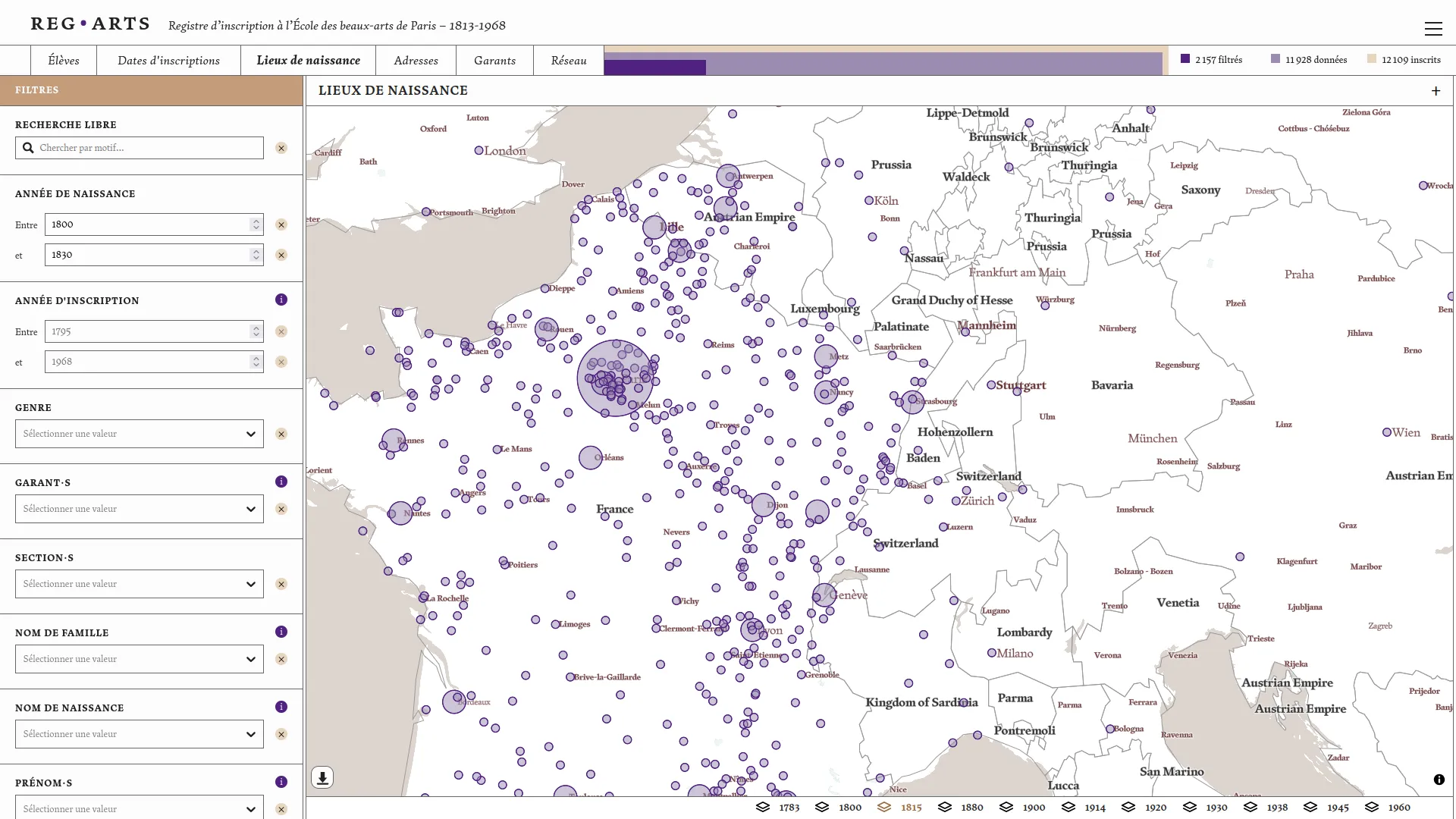
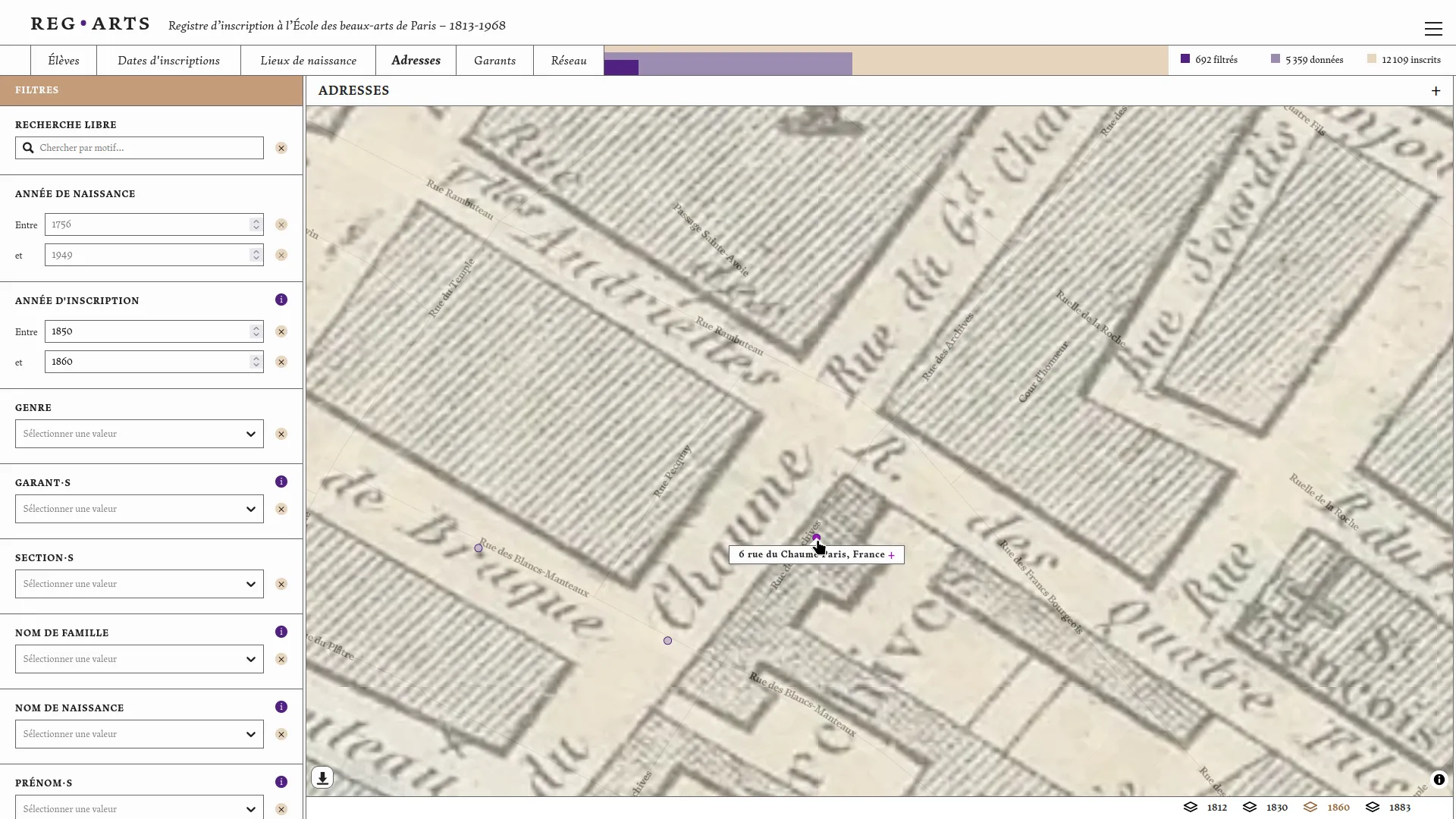



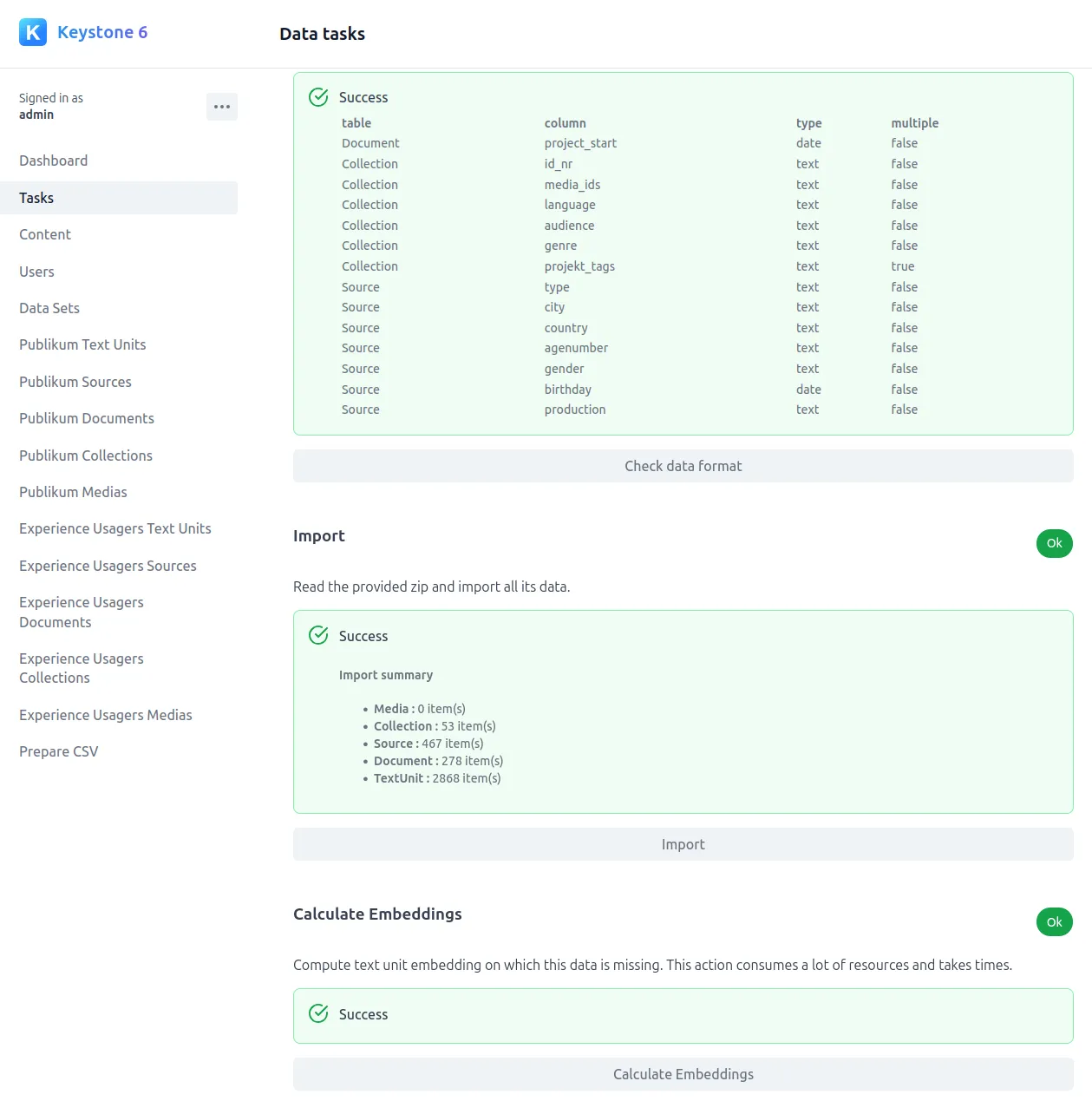
Le registre d’inscription de l’École des beaux-arts 1813-1968 est composé de six volumes conservés aux Archives Nationales et à l'École des beaux-arts. Le projet Reg⋅Arts propose une publication numérique de ce corpus souvent mobilisé par la recherche en histoire de l'art. Cette publication comporte un jeu de données en accès ouvert et une application web d'exploration visuelle associée. Cette dernière permet d’effectuer des recherches libres sur les élèves, les lieux de naissance, les adresses à Paris (1813-1892), les garants, mais aussi de systématiser l’interrogation de la source grâce aux filtres de recherche et leur croisement. Il est possible désormais d’interroger le registre pour en extraire, par exemple, tous les élèves nés à Dijon ayant étudié à l’École entre 1813 et 1840, ou de voir des clusters s’agréger autour de figures comme Jean-Léon Gérôme.
Nous avons accompagné l'équipe de recherche du projet sur plusieurs années. Le premier volet de notre intervention a consisté à créer un jeu de données structuré à partir des transcriptions. Ensuite nous avons conseillé et outillé le travail de normalisation et d'alignement des données. Nous avons veillé à bien conserver les données sources, pour autoriser la vérification de cette mise à distance des sources. Enfin nous avons créé un export du jeu de données au format sémantique linked-art.
Nous avons ensuite co-conçu et développé la publication web de ce jeu de données en collaboration avec Julie Blanc et Lola Duval. Cette application propose d'explorer les inscriptions dans le temps, les lieux de naissance et de domicile des élèves et les liens garants-élèves. Ces différentes modalités visuelles sont reliées par un système de filtres communs qui permet d'étudier un périmètre précis du corpus. Enfin, pour chaque élève, une page dédiée regroupe les informations liées à son ou ses inscriptions à l'école.
Conscient de la difficulté d'analyser des données de registres sur le temps long, nous avons veillé à bien contextualiser les visualisations et données présentées. La page `élèves` présente les différentes étapes ayant abouti aux données normalisées: la photo de la source et la données telle que transcrite avant normalisation. Les visualisations montrent systématiquement le nombre de données non représentées pour cause de données manquantes. Enfin les fonds de cartes géographiques ont été spécialement travaillé pour éviter un maximum d'anachronisme (Girard 2025). Cette application fonctionne totalement dans le navigateur, ce qui simplifie grandement sa maintenance.
Un projet de Développement sur-mesure
Paul Girard, Charlotte Ribeyrol, Arnaud Dubois, Julie Blanc et Zoé L'EVEQUE
Lisbonne, Portugal
Lancement publique de la chromobase à l'occasion du colloque Colour matters.
Ajout des cercles chromatiques par luminosité et création du glossaire.
![[object Object]](/_astro/narrative_page.DNVwQoY6_91YVn.webp)
La narrative “Persoz, the birth of heritage sciences and medieval colours” avec le marqueur “Jean-François Persoz” et le lien vers sa notice mise en evidence.
![[object Object]](/_astro/colourwheel.D5HuUlH4_1H4ojx.webp)
L'objet "Register of samples and correspondence, 1850-1930: letter from Camille Koechlin to Horace Koechlin, 4 August 1861" vu dans la roue chromatique.
![[object Object]](/_astro/IIIF_viz.157K4vUZ_FcpKu.webp)
Une image IIIF sur la page de l'objet Azofuchsine 6B Bayer, CNAM Musée des Arts et Métiers, Paris.
![[object Object]](/_astro/editor_notice_link.CSaAjxfG_Z2bKWdK.webp)
![[object Object]](/_astro/editor_wikidata_import.C2CIKpNB_Z223lcc.webp)


Chromobase est une base de données en accès libre produite par CHROMOTOPE, un projet financé par l'ERC et dirigé par Charlotte Ribeyrol. Ce programme de recherche explore ce qu'il est advenu de la couleur dans l'Europe industrielle durant la seconde moitié du XIXe siècle. Chromobase montre comment les nouveaux matériaux et techniques de coloration inventés dans les années 1850 ont engendré de nouvelles façons de penser la couleur dans la littérature, l'art, ainsi que dans l'histoire des sciences et des techniques. L'histoire extraordinaire de cette « Révolution de la couleur » du XIXe siècle est racontée à travers une série de récits interdisciplinaires entrelacés, rédigés par des experts de la couleur du monde entier.
Nous avons développé une méthodologie basée sur des récits, où les textes écrits par les chercheurs servent de source à partir desquelles sont créées des données. Le processus éditorial annote les textes fournis par les chercheurs, en reliant des entités telles que des personnes, des organisations, des objets, des techniques, des événements, des couleurs ou des références. Chaque texte édité ajoute ainsi de nouveaux points de données à la base, formant peu à peu un corpus complet d'acteurs (humains et non humains) ayant joué un rôle dans notre objet d'étude. Chaque auteur décide quels éléments spécifiques mettre en avant en en parlant dans son récit. Ainsi, chaque donnée est, par construction, sélectionnée et contextualisée par des textes auxquels il est possible de se référer pour en apprendre davantage sur leurs rôles et leurs interactions.
Pour alimenter ce processus, nous avons développé un gestionnaire de contenu basé sur Keystone.js, incluant des fonctionnalités dédiées telles que l'édition de lien vers des notices dans l'éditeur de texte, un module d'import de données Wikidata ou encore un format de téléchargement d'images haute définition utilisant le générateur de tuiles IIIF bIIIF. La base de données est ensuite transformée en site web statique à l'aide de Astro. Ce site, designé par Julie Blanc, propose une structure hypertextuelle favorisant la sérendipité, et des interfaces visuelles et interactives mettant en avant la matérialité des couleurs du XIXe siècle.
Un projet de Développement sur-mesure

G.V() est une plateforme d'exploration de bases de données graphes, conçue avec des technologies web, notamment sigma.js.
Nous les accompagnons pour améliorer et optimiser leur intégration optimale de sigma.js. En outre, l'équipe G.V() nous sponsorise régulièrement pour développer de nouvelles fonctionnalités open-source, ou encore déboguer et optimiser la base de code de sigma.js.
Un projet de Conseils et accompagnement
Une nouvelle version qui ajoute la gestion du son et des images dans l'outil d'exploration.
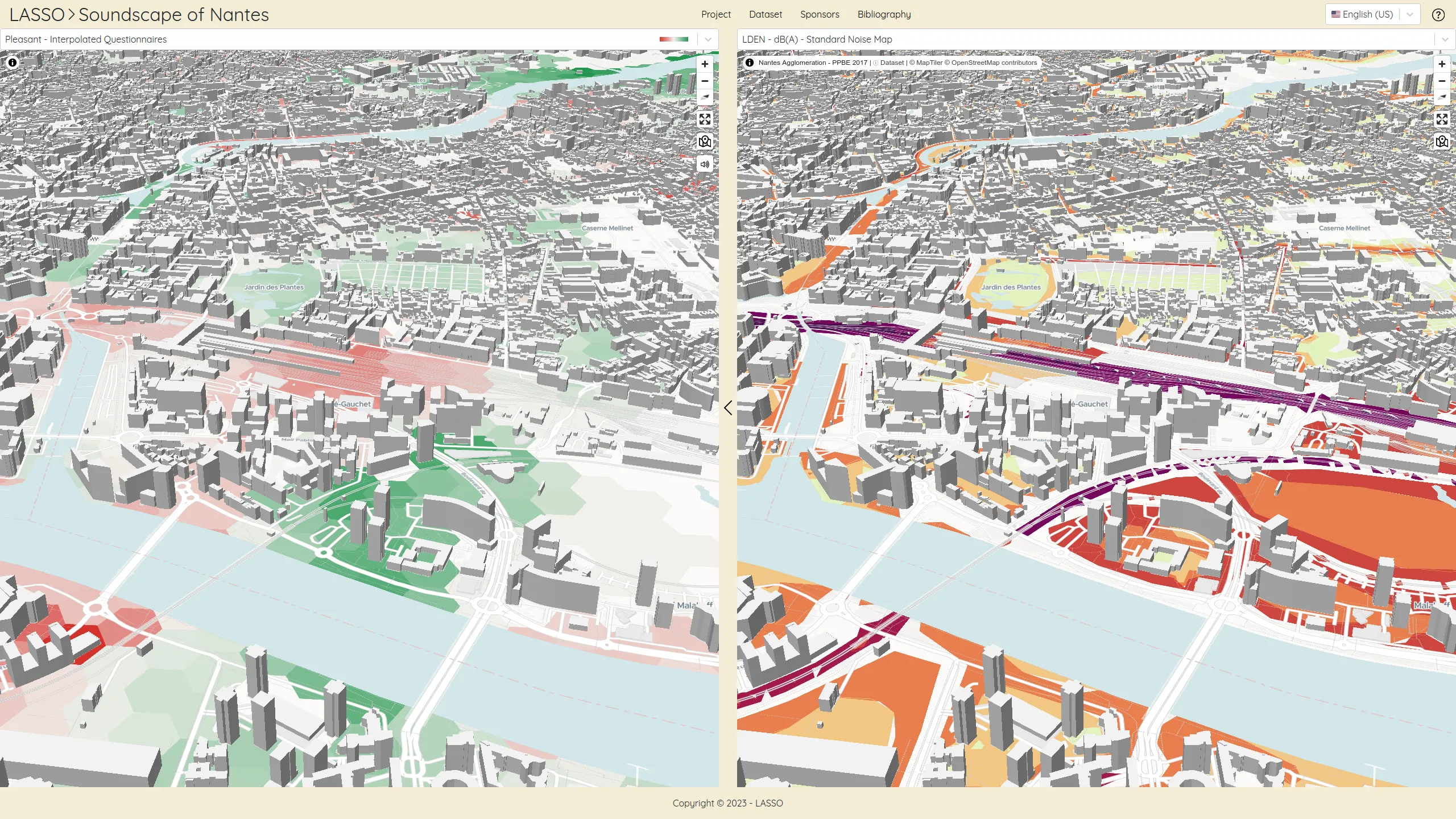
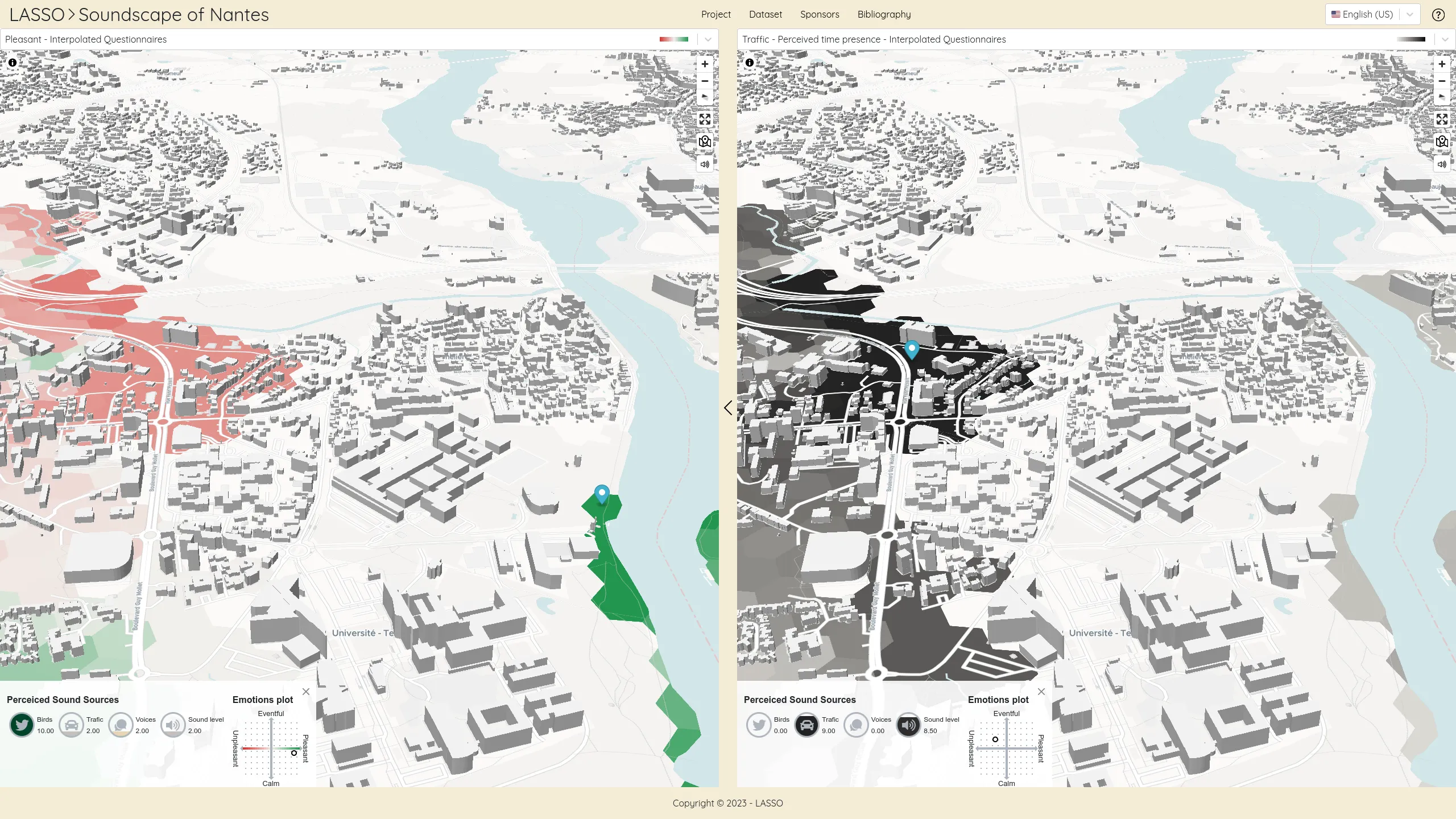


The LASSO platform est une plateforme web publiant des jeux de données spatio-temporel décrivant des paysages sonores. Ces jeux de données ont été produits en collaboration par des équipes de recherche de l'Université de Gustave Eiffel et de l'Université de Cergy-Pontoise. Cette plateforme vise à présenter les avantages de la cartographie des paysages sonores qui propose une approche perceptive beaucoup plus fine que les cartes de bruits standards. Elle fournit aux chercheurs et décideurs des jeux de données exclusifs ainsi qu'un démonstrateur des potentiels d'analyse de cette approche.
Cette plateforme a pour ambition de participer à une meilleure compréhension du rôle que les paysages de données ont à jouer dans la construction des environnements urbains de demain.
Nous avons conçu et développé cette plateforme en une application react sans serveur utilisant la technologie de cartographie vectorielle MapLibre.
Un projet de Valorisation de données
Avec les gens du médialab de Sciences-Po, on se réunit quelques jours à Nantes pour finaliser la version 2.0 de sigma.js. On en profite pour refaire complètement le site, et les exemples de code.
Nantes, France
Alexis Jacomy
Bruxelles, Belgique
Inclut une refonte complète du système de programme, et une réécriture de tout le tooling.
La première version de sigma.js basée sur Graphology.
OuestWare et Sciences-Po médialab
La bibliothèque "officielle" pour utiliser sigma.js dans des applications React.
Benoit Simard
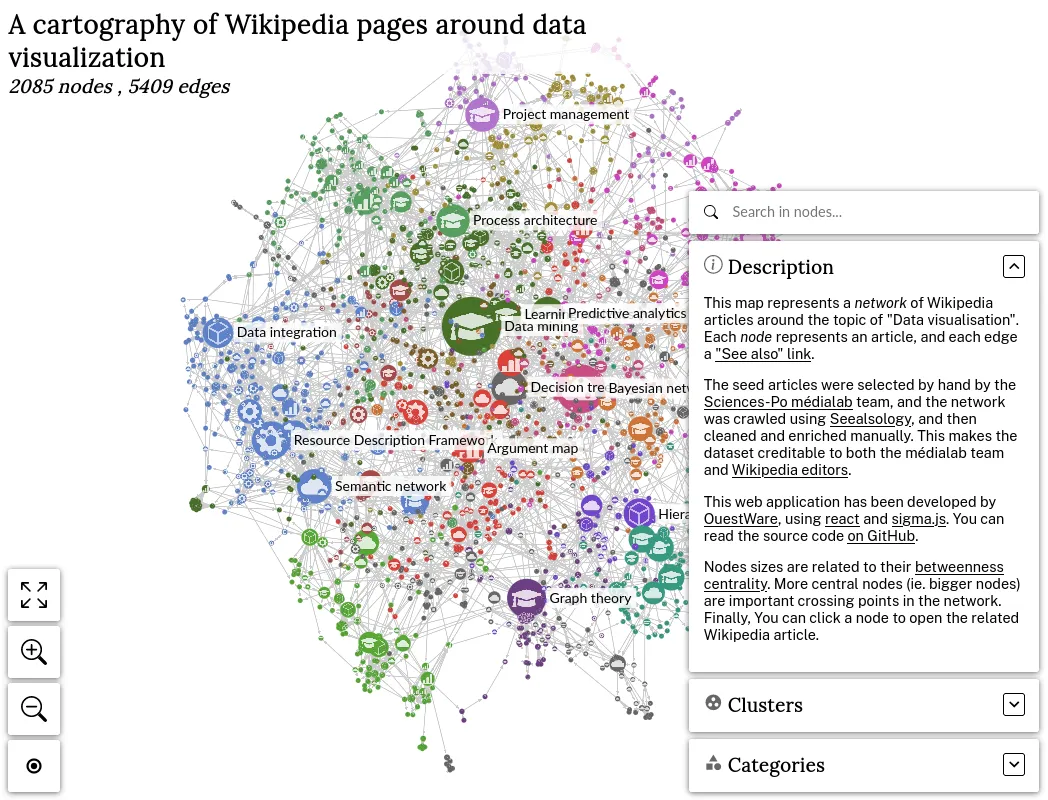

Améliorer et maintenir une bibliothèque JavaScript open source
Nous développons et maintenons sigma.js, une bibliothèque JavaScript open source dédiée à l'affichage de graphes. Nous utilisons cette bibliothèque dans une bonne partie de nos projets.
Nous pouvons développer à la demande des fonctionnalités métier dédiées à nos clients, ou des fonctionnalités plus génériques - open-source autant que possible. Nous maintenons également React Sigma, qui facilite l'utilisation de sigma.js dans des applications basées sur React.
Un projet de Code et Données ouvertes
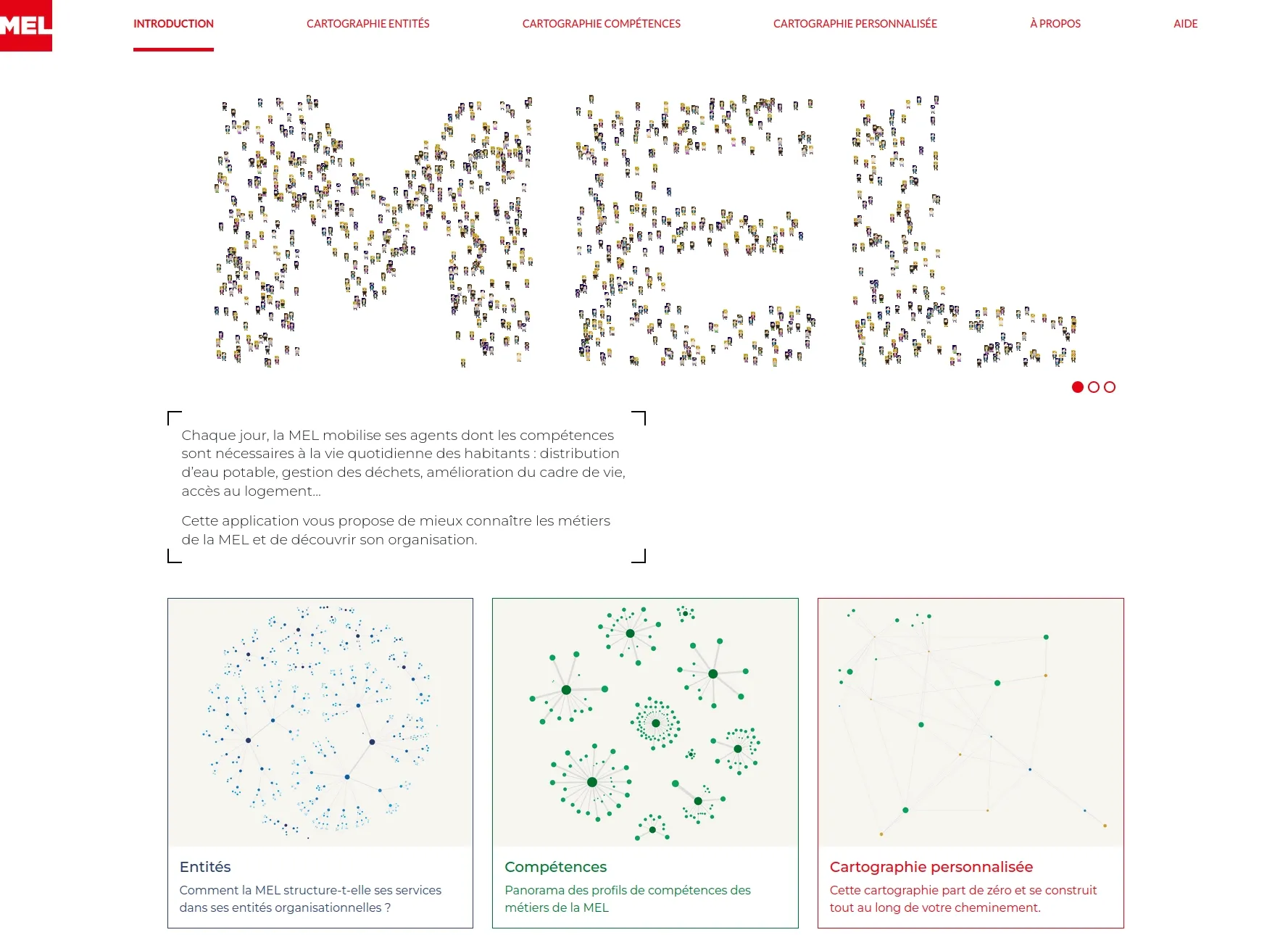
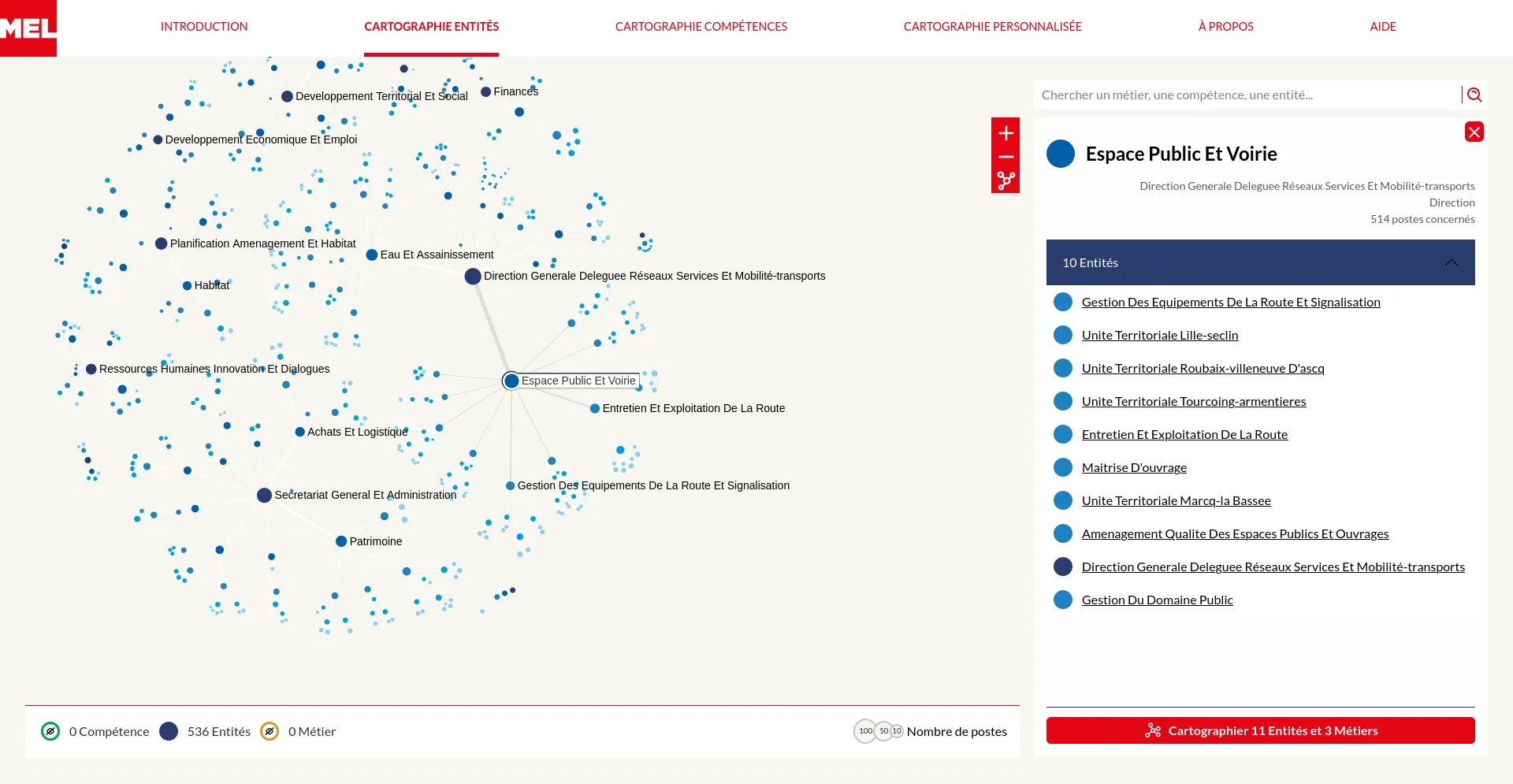
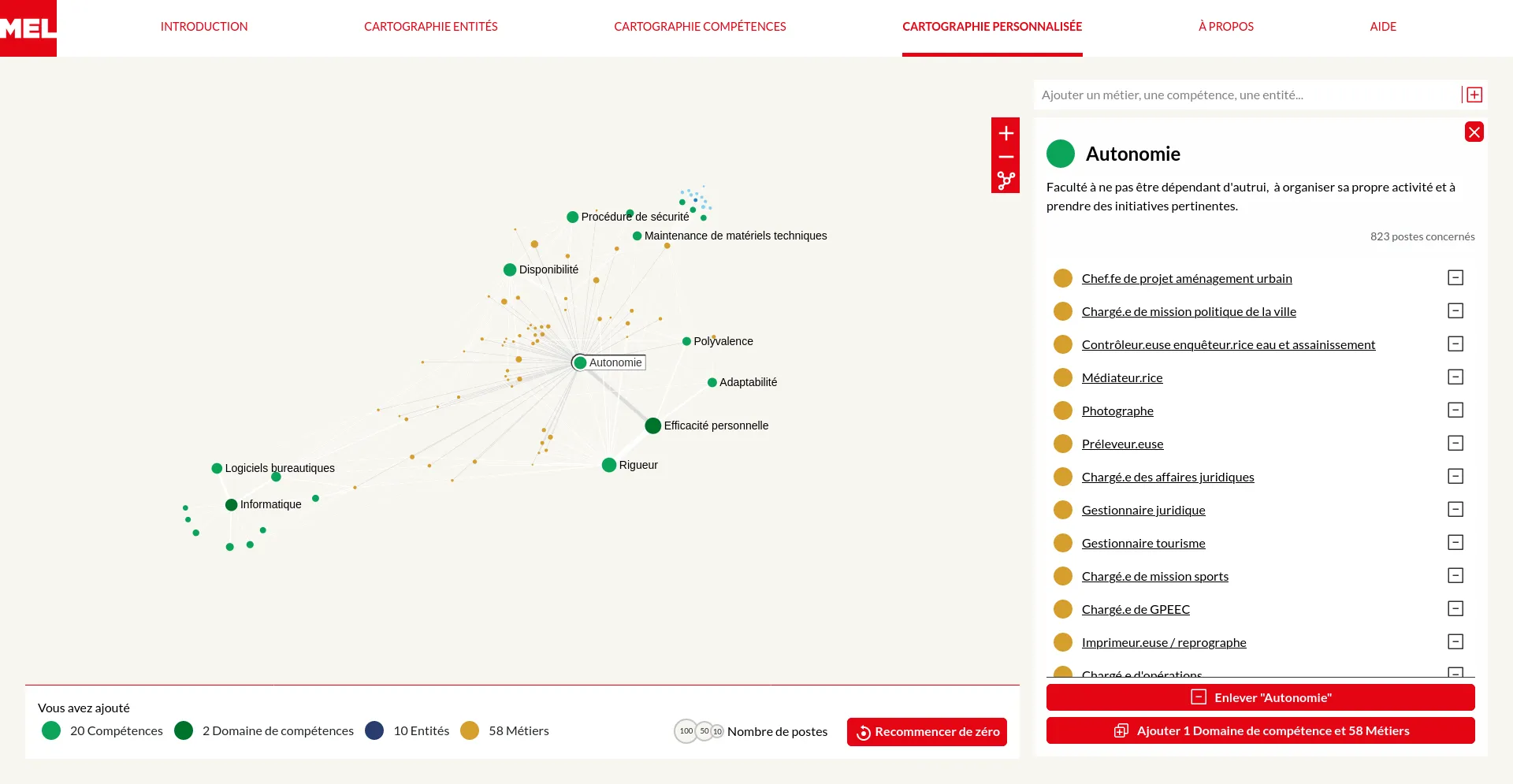
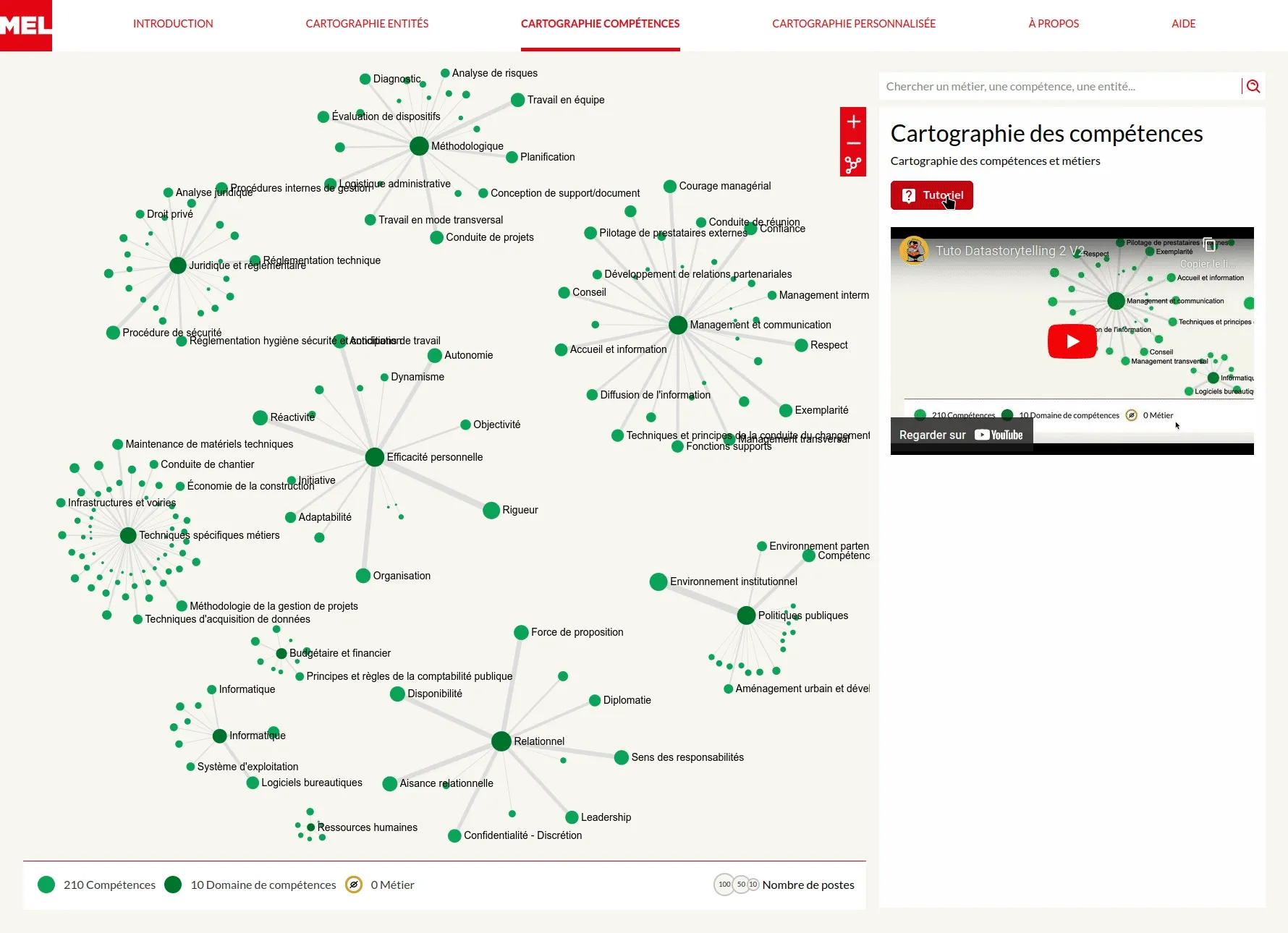


La Métropole Européenne de Lille (MEL) emploie de nombreux collaborateurs pour animer les services qu'elles offrent à ses administrés. De la jardinière au comptable, une très grande diversité de métiers et de compétences sont mobilisés dans cette grande organisation publique. Nous avons travaillé en collaboration avec les équipes de Datactivist à la création d'une série d'outils d'exploration visuelle permettant de se plonger dans l'environnement professionnel de la MEL.
Il s'agit de démystifier cette grande organisation en révélant les détails des services, métiers et compétences qui l'animent. Pour des personnes extérieures à l'organisation qui pourraient par exemple souhaiter rejoindre l'organisation mais aussi pour les agents de la MEL qui souhaitent se situer voire identifier des pistes d'évolutions de carrière.
Pour répondre à ces objectifs nous avons conçus deux modes d'exploration : tout représenter ou construire une représentation de proche en proche en fonction de ces intérêts. Dans les deux cas, un soin particulier a été porté à l'accompagnement des utilisateurs en proposant une navigation par menu contextuel ainsi que des tutoriels interactifs détaillant les modes d'interactions avec les visualisations.
Un projet de Valorisation de données
Cette nouvelle version bêta entièrement refaite de GraphCommons a nécessité plus d'un an de développement.
Une nouvelle version avec du rendu côté serveur, qui améliore entre autres le référencement.
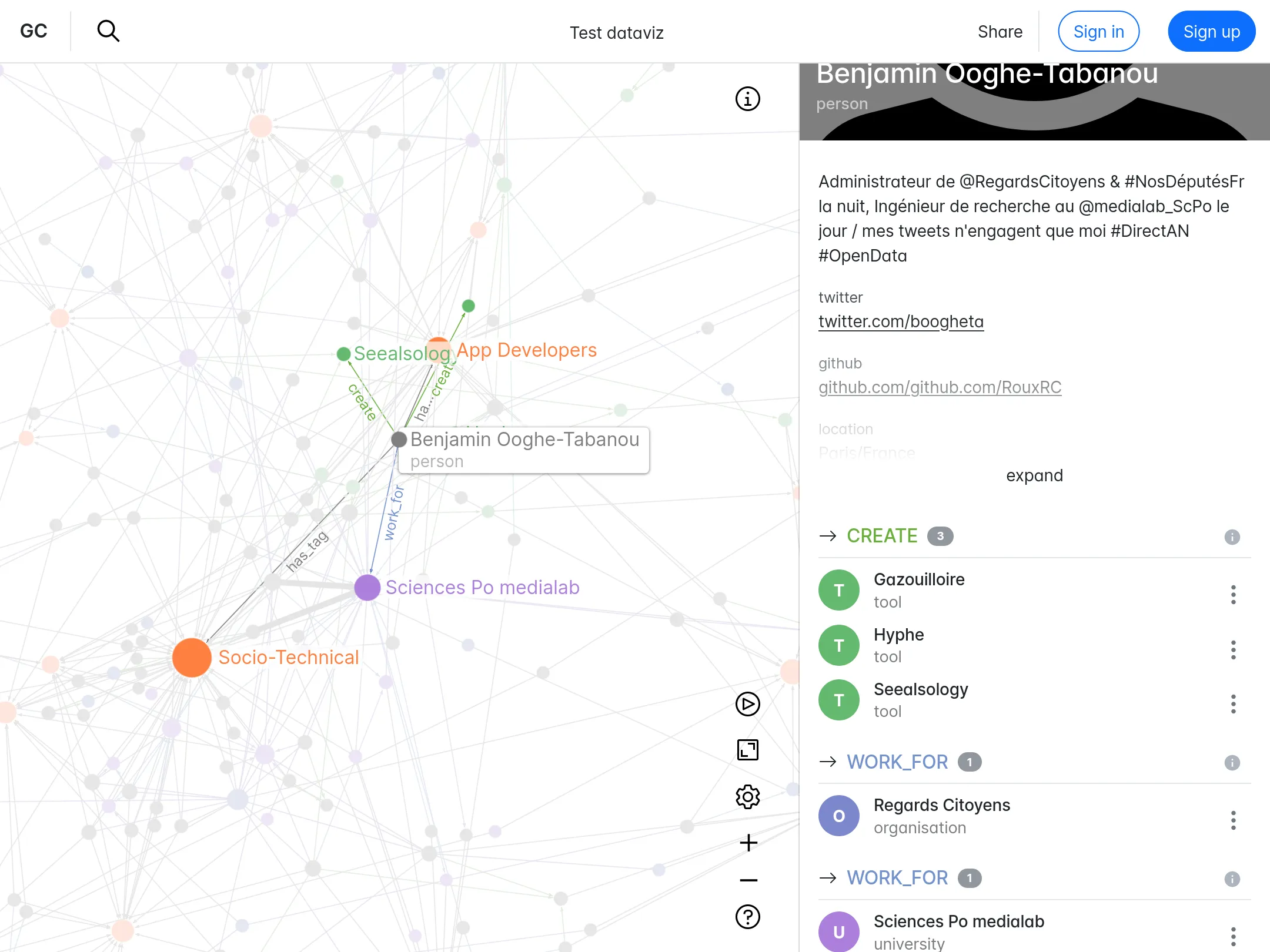

Depuis 2021, nous développons et maintenons pour GraphCommons leur plateforme web de cartographie, d'analyse et de partage de données-réseaux. Ce projet a sollicité toute notre expertise en réseaux - de la modélisation et des bases de données jusqu'à la visualisation, ainsi qu'en développement web. Nous avons ainsi intégré Neo4j côté données, ainsi que sigma.js et graphology côté client. Le site est basé sur Next.js et React. Nous continuons à développer régulièrement de nouvelles fonctionnalités, tout en maintenant l'application.
Un projet de Conseils et accompagnement
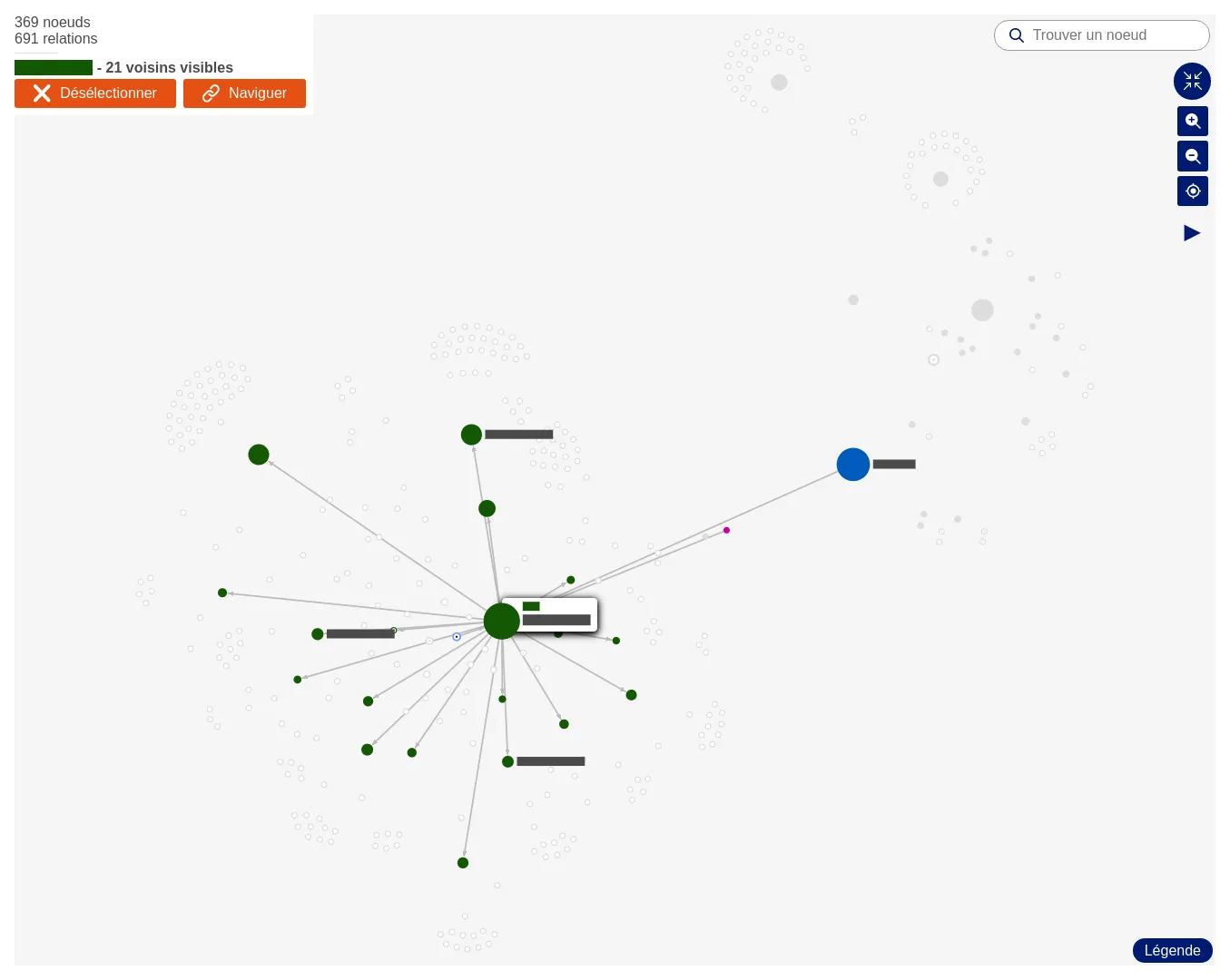
Exploration d'une CMDB à l'aide de réseaux égocentrés
Un des plus grands groupes industriels français possédant l'intégralité de son système informatique (CMDB) dans une base Neo4j, avait besoin d'une interface d'exploration de son infrastructure.
L'application se compose d'un moteur de recherche, et d'une page pour chaque noeud du graphe, présentant son voisinage et ses métadonnées. Pour avoir un moteur de recherche efficace (tolérance d'erreurs, recherche sur différents champs), nous avons indexé les données dans un ElasticSearch.
L'interface est développée avec Angular, et Node pour l'API - le tout avec TypeScript.
Un projet de Développement sur-mesure
La première version comprend le moteur de recherche, ainsi que les pages professions de foi.
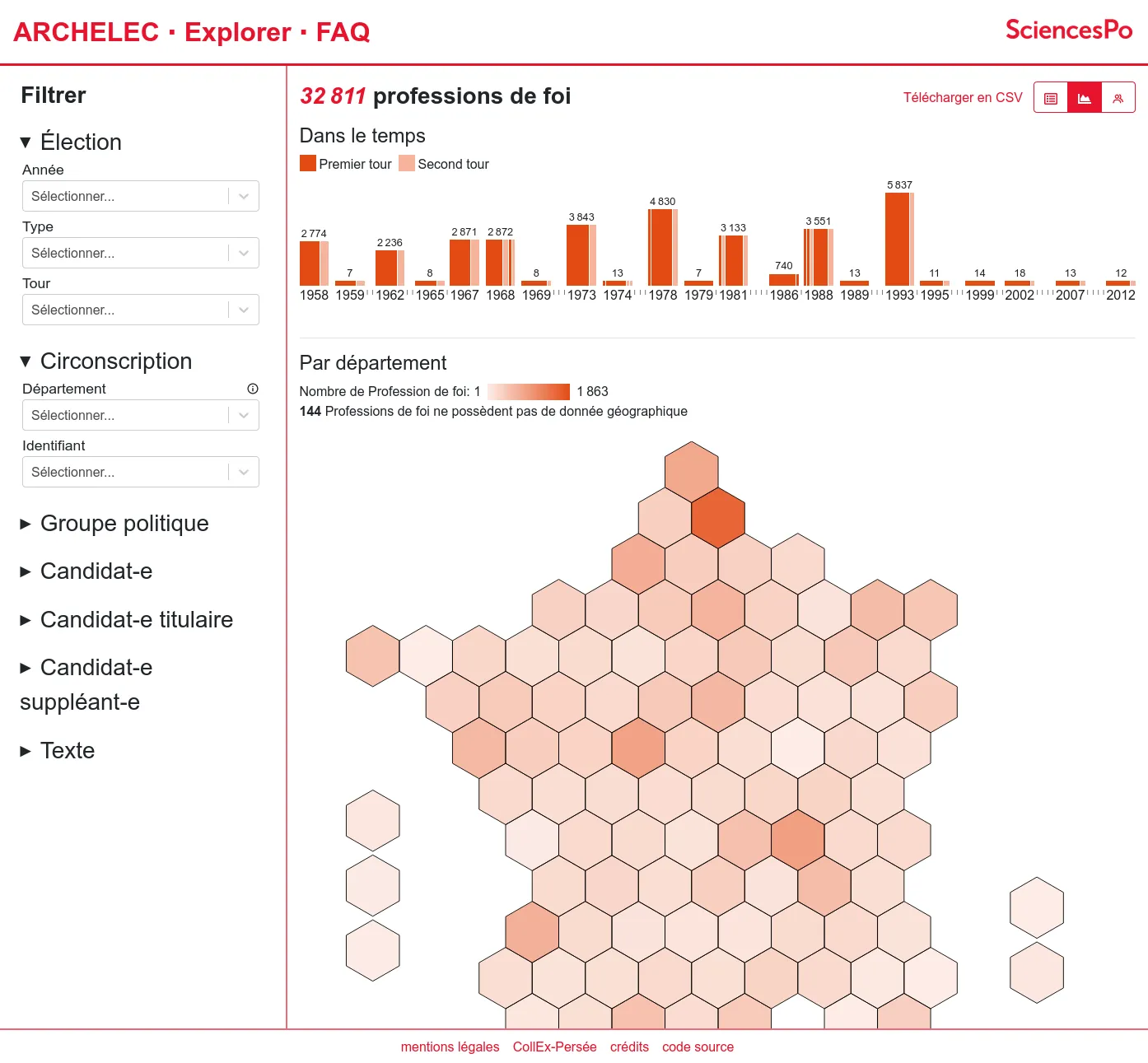
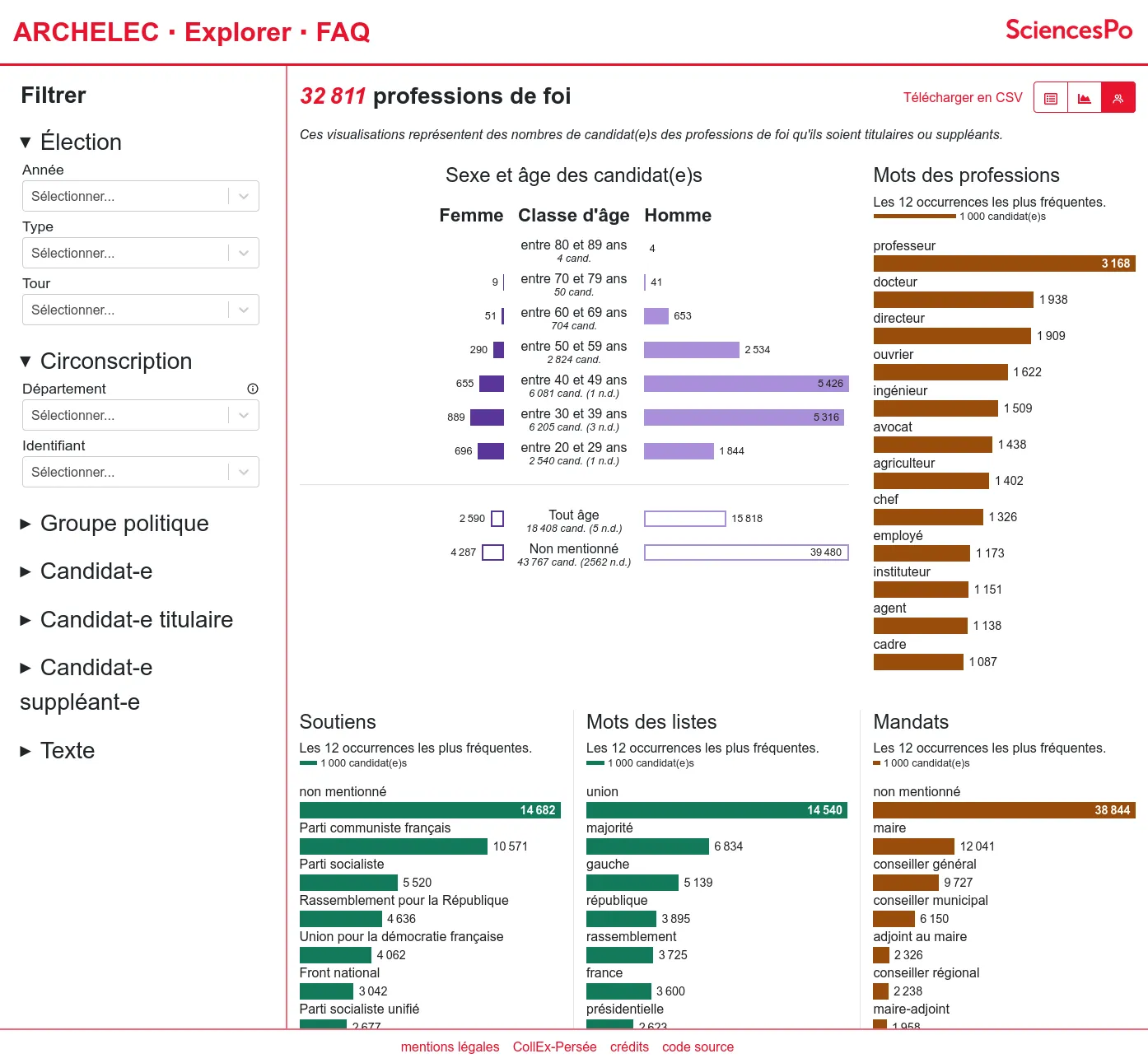
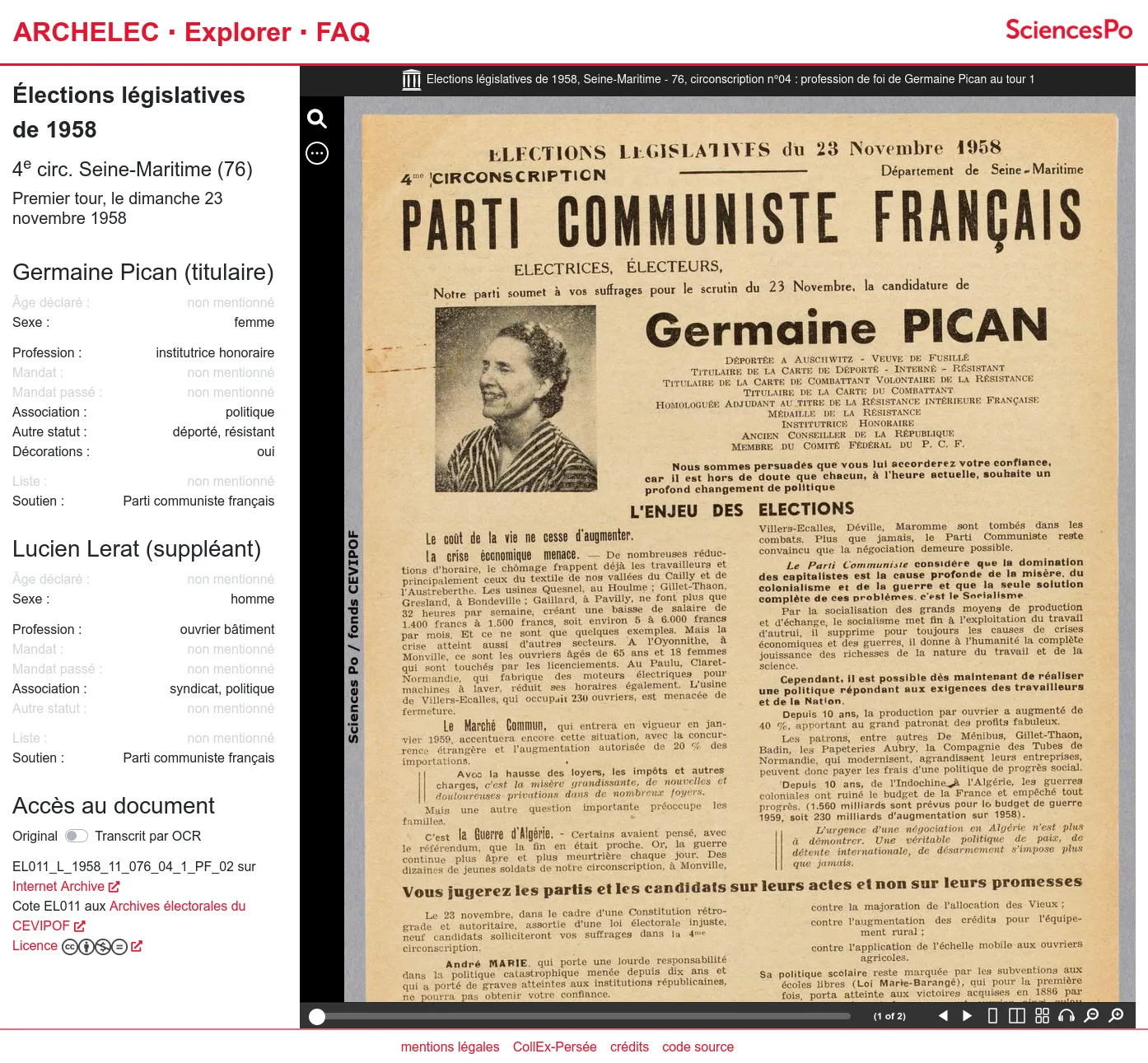
Depuis 2013, la Bibliothèque de Sciences Po pilote la mise en ligne des archives électorales réunies par le Centre de recherches politiques (CEVIPOF) et désormais conservées au Département archives de la Bibliothèque : un fonds unique de professions de foi de candidats aux élections (législatives, mais aussi présidentielles, européennes, etc.) depuis 1958.
Après l'avoir publié sur Internet Archive, la Bibliothèque de Sciences Po nous a confié la conception et le développement sur-mesure d'une application d'exploration du corpus, afin d'exploiter la très riche indexation de plus de trente mille documents. Nous avons développé une application web qui permet de filtrer les professions de foi par élection, circonscription, groupe politique, profil des candidat⋅e⋅s...
Les résultats du filtrage peuvent ensuite être explorés en listes, en visualisations de données ou téléchargeables en CSV. Enfin le document original est consultable grâce au lecteur fourni par Internet Archive. Ainsi les choix d'indexation faits par les bibliothécaires et archivistes du projet peuvent être confrontés au document source.
Un projet de Valorisation de données
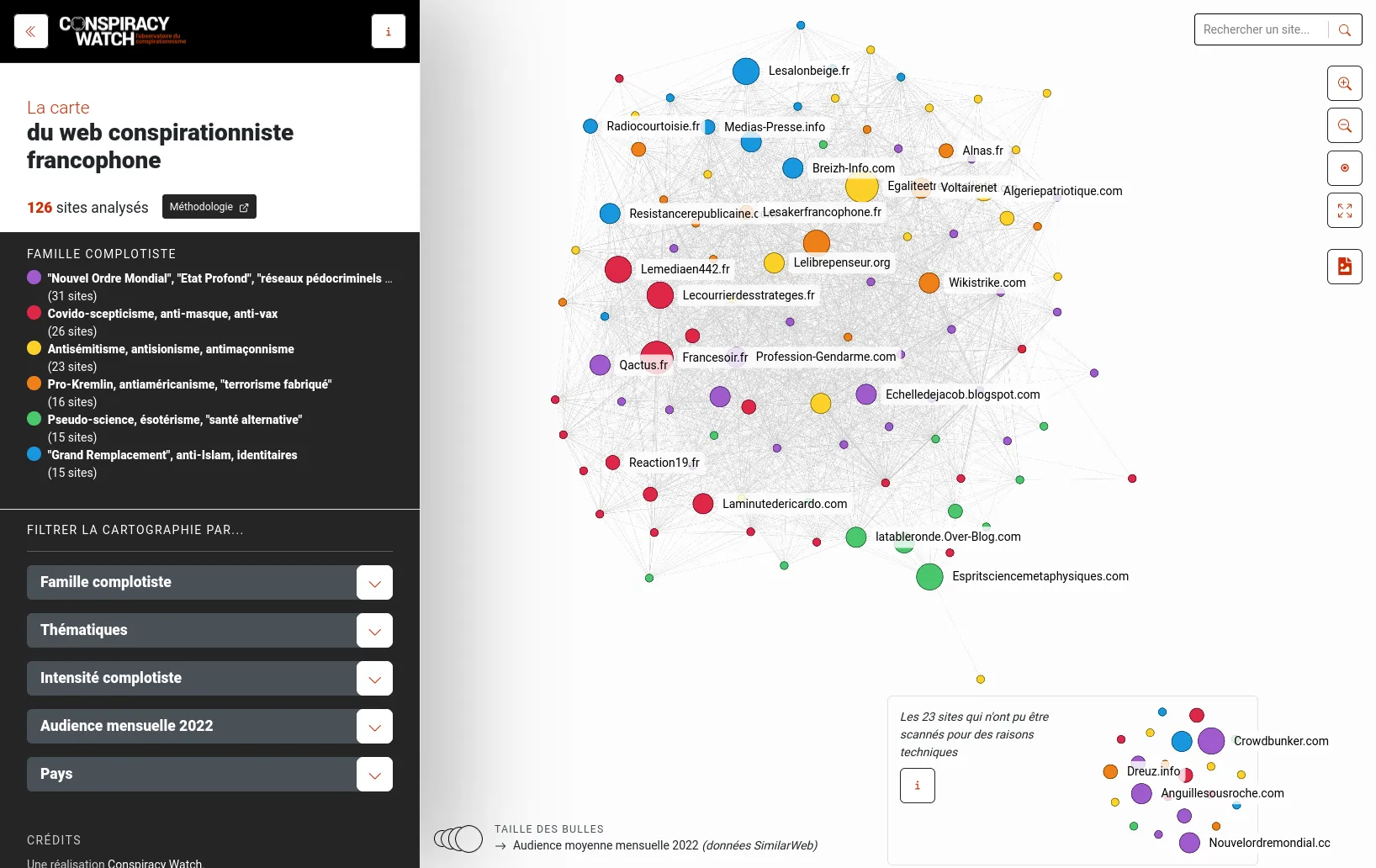
Un outil open-source pour partager des visualisations de réseaux en ligne, financé par le Centre Internet et Société.
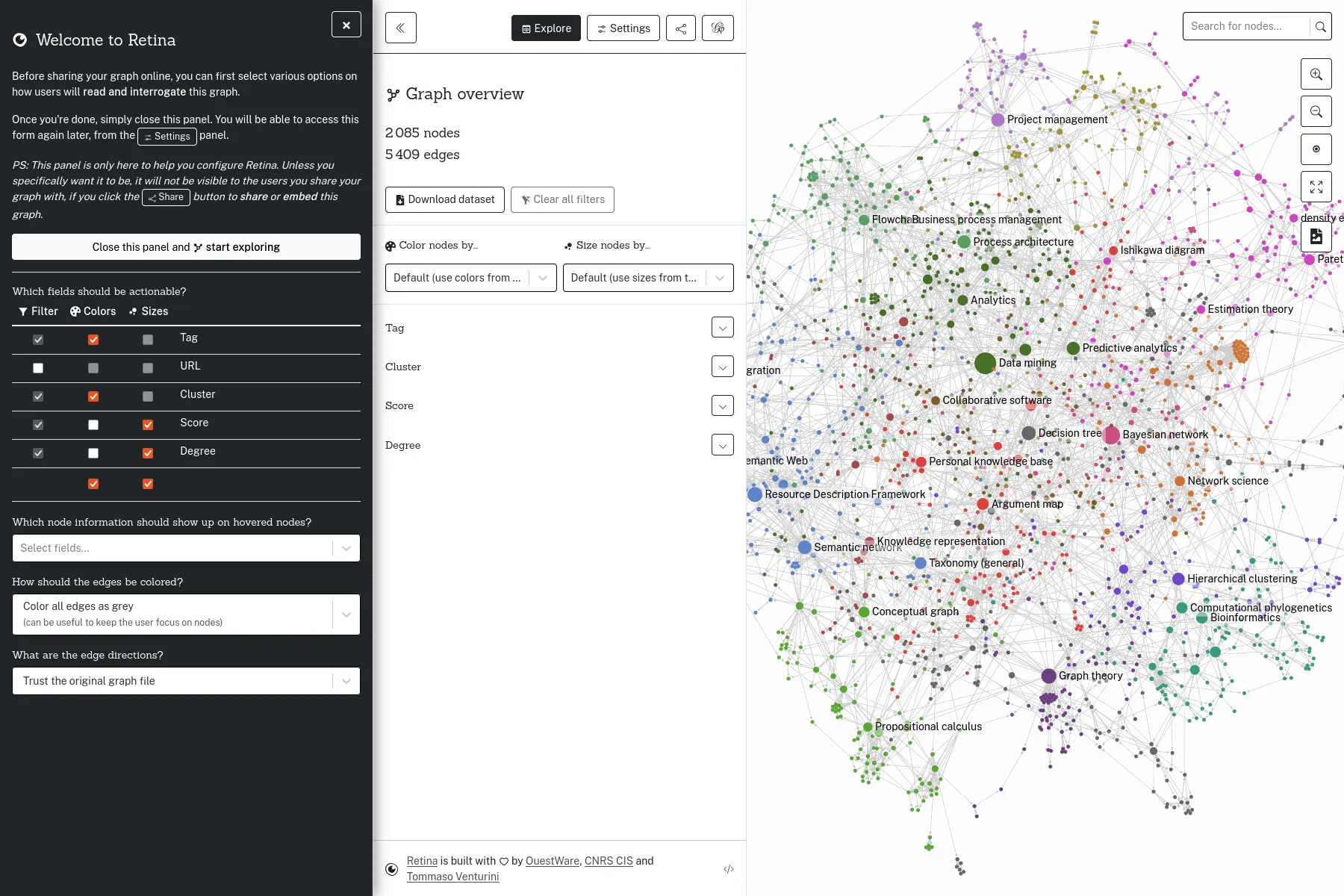
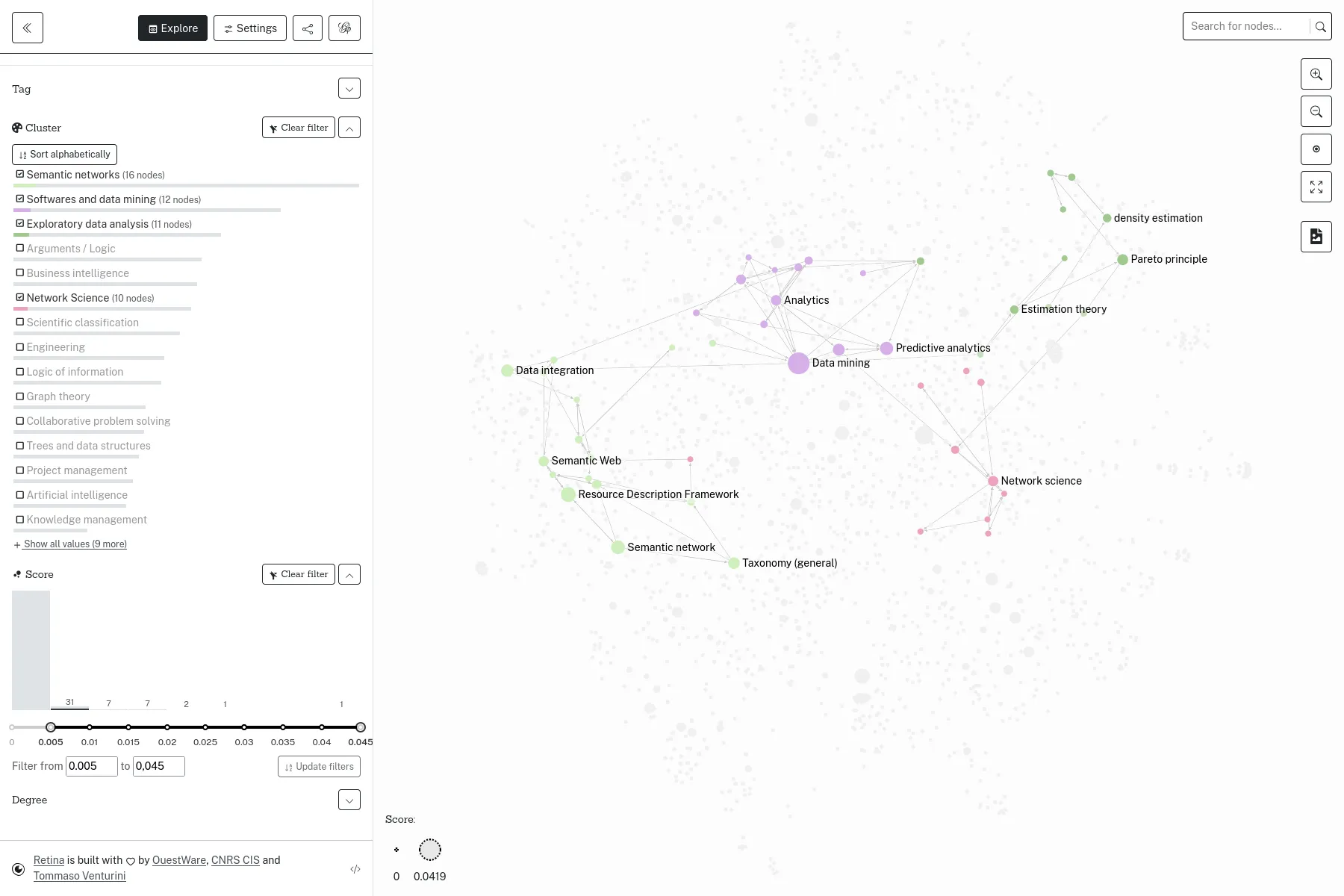
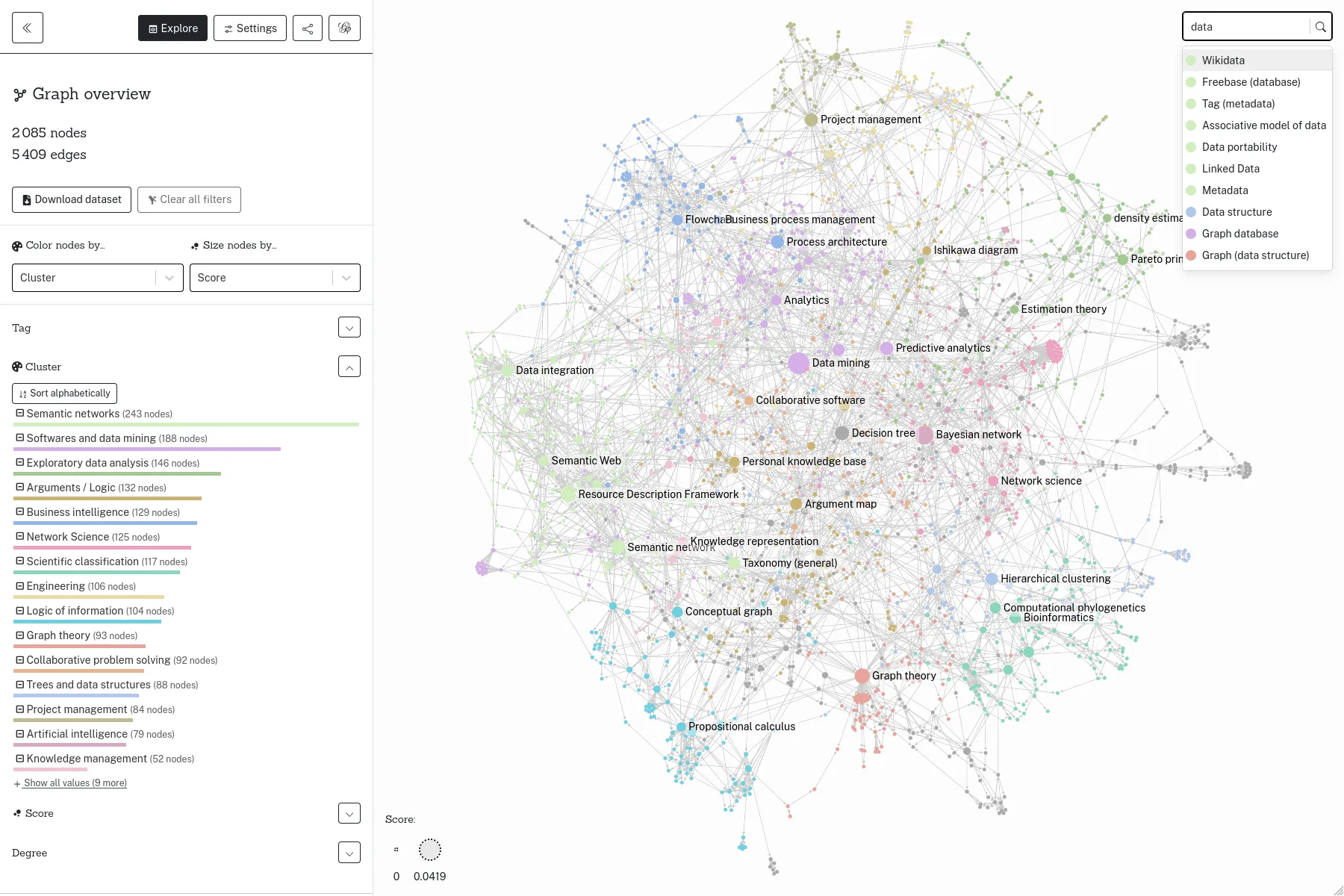

Retina est une application web open-source qui permet de partager en ligne des visualisations de réseaux, sans besoin d'avoir une application serveur à entretenir. Initié par Tommaso Venturini et le Centre Internet et Société du CNRS en 2021, Retina est utilisé par divers acteurs, notamment dans la communauté des utilisateurs de Gephi. Nous l'avons également utilisé comme base pour développer avec WeDoData la cartographie du Web complotiste francophone, pour Conspiracy Watch.
L'interface permet de choisir quels champs de données utiliser pour la taille et la couleur des noeuds, de filtrer les noeuds, ou encore de chercher dans les noeuds. Techniquement, tout se passe dans le navigateur, et tout l'état de l'application est décrit dans l'URL, et les fichiers de données sont chargés depuis n'importe quel serveur qui permet le Cross-origin resource sharing, comme par exemple GitHub Gist.
Un projet de Code et Données ouvertes
Cette nouvelle version embarque la généalogie des éditeurs, et divers bug fixes.
Cette version, dans le cadre de notre contrat de maintenance, ajoute la gestion des collections, et met à jour les dépendances du code.
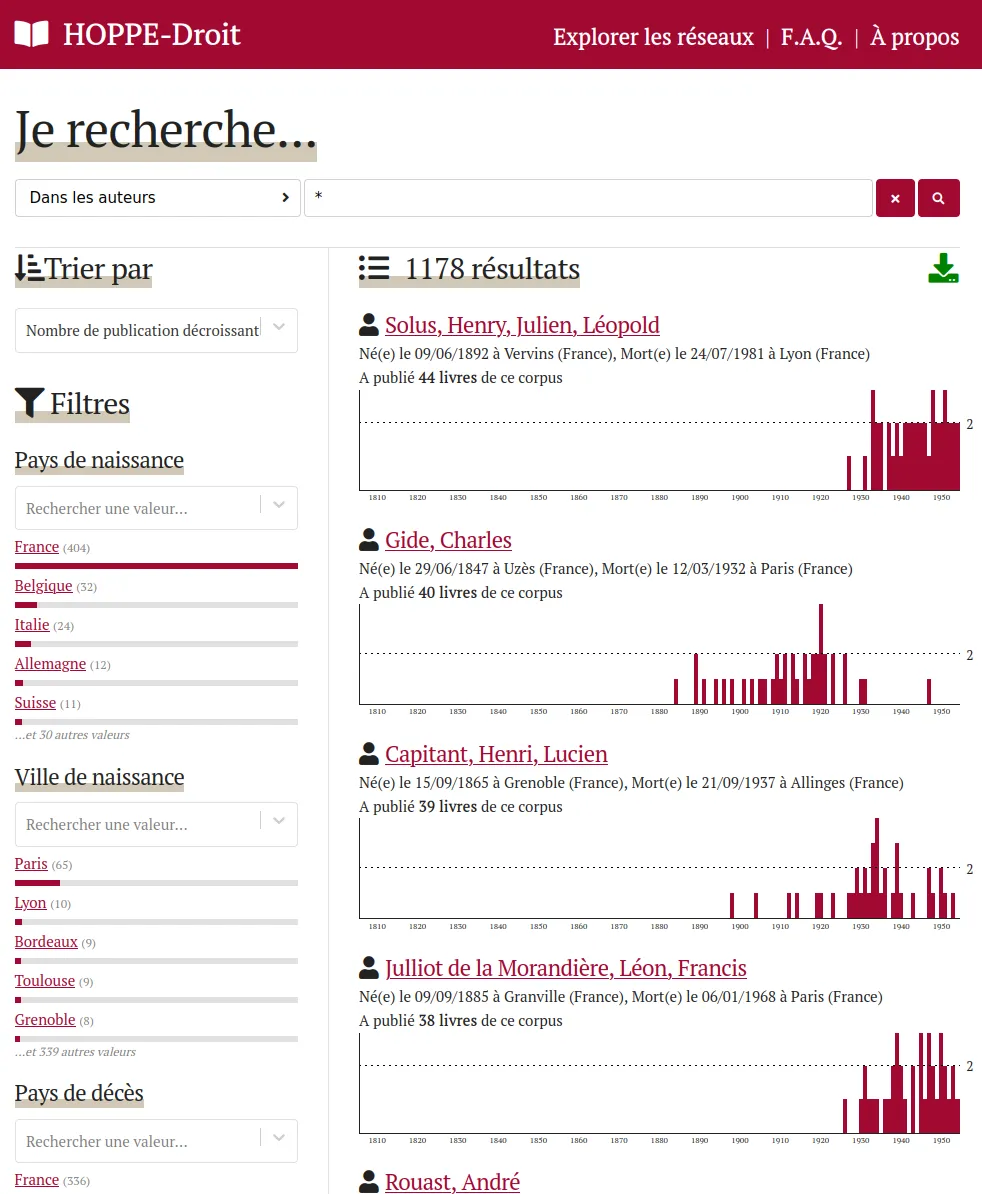
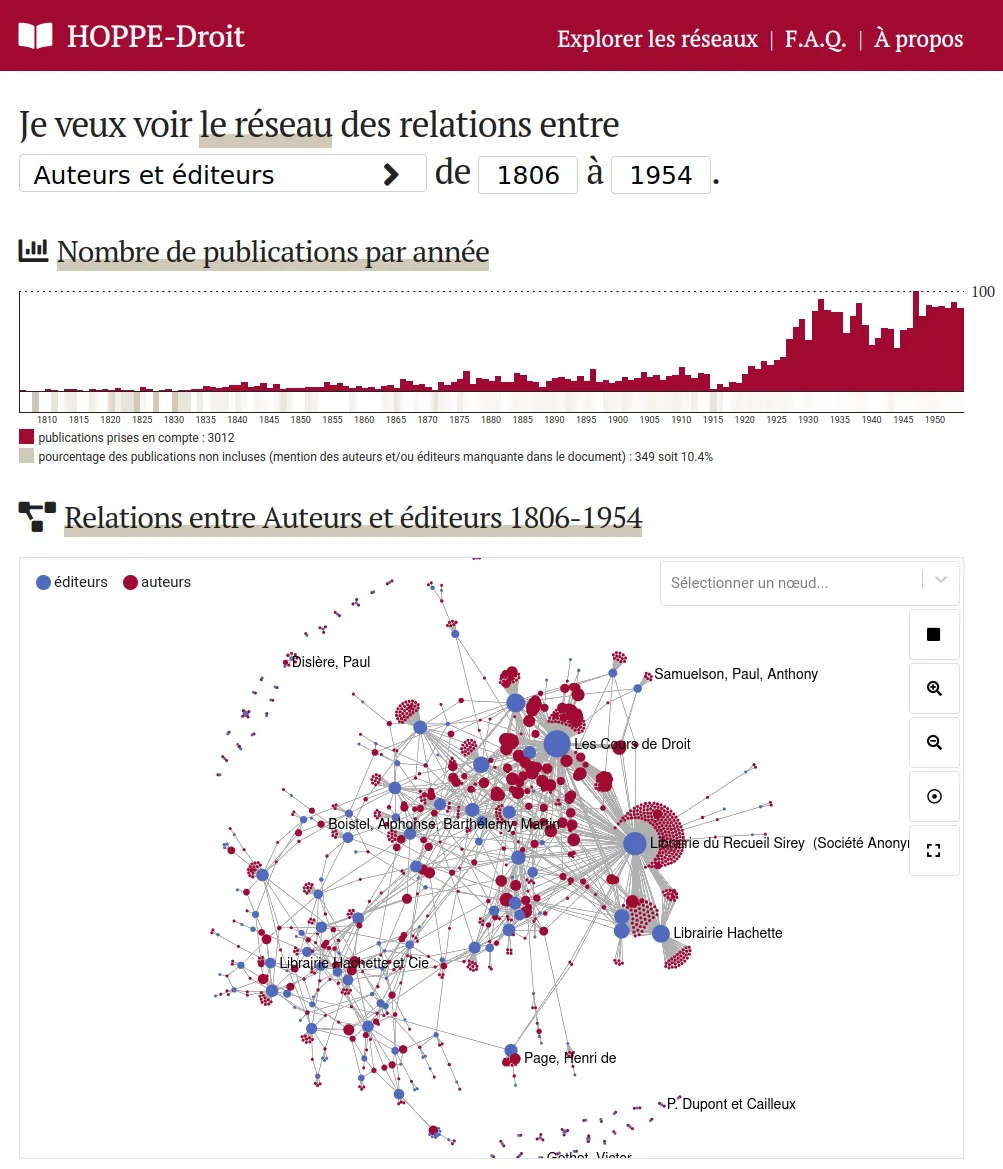
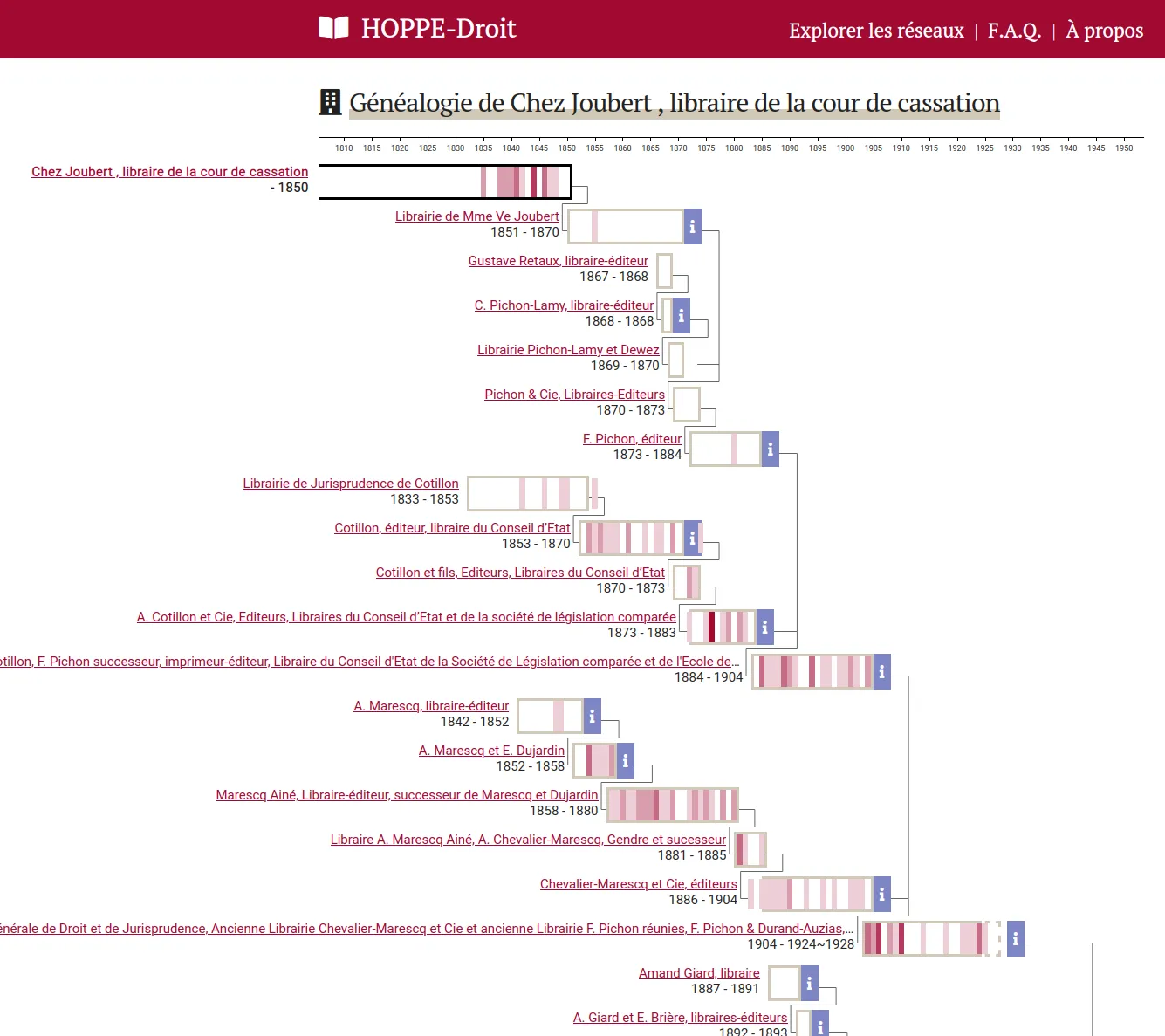

Explorer une collection d'ouvrages pédagogiques en droit français du XIXe-XXe siècles
HOPPE-Droit vise à l’élaboration et la publication d'une collection de notices bibliographiques de productions pédagogiques en droit des XIXe et XXe siècles. Nous avons conçu et développé un outil d’exploration qui permet d’étudier les évolutions du droit français à travers les manuels utilisés pour son enseignement depuis le XIXe siècle.
Le corpus est édité par l'équipe CUJAS dans la base de données Heurist. Ces données sont exportées par l'API et indexées dans un ElasticSearch en prenant soin de conserver la complexité des dates aux différents niveau de précision (date annuelle, au jour près) et d'incertitude. Une application web permet d'explorer et visualiser le corpus sous différents angles: productions, auteurs, éditeurs, réseaux de co-publication, généalogies...
Un projet de Développement sur-mesure
David F. Johnson, Paul Girard et Benoit Simard
Digital Humanities 2022, Tokyo, Japon
![[object Object]](/_astro/schema_creation.CZxo5Nmu_ZPV9IT.webp)
![[object Object]](/_astro/upload_files.DnXWHWRm_1jYw0K.webp)
![[object Object]](/_astro/collection_overview.CTVsJE-q_187O5M.webp)

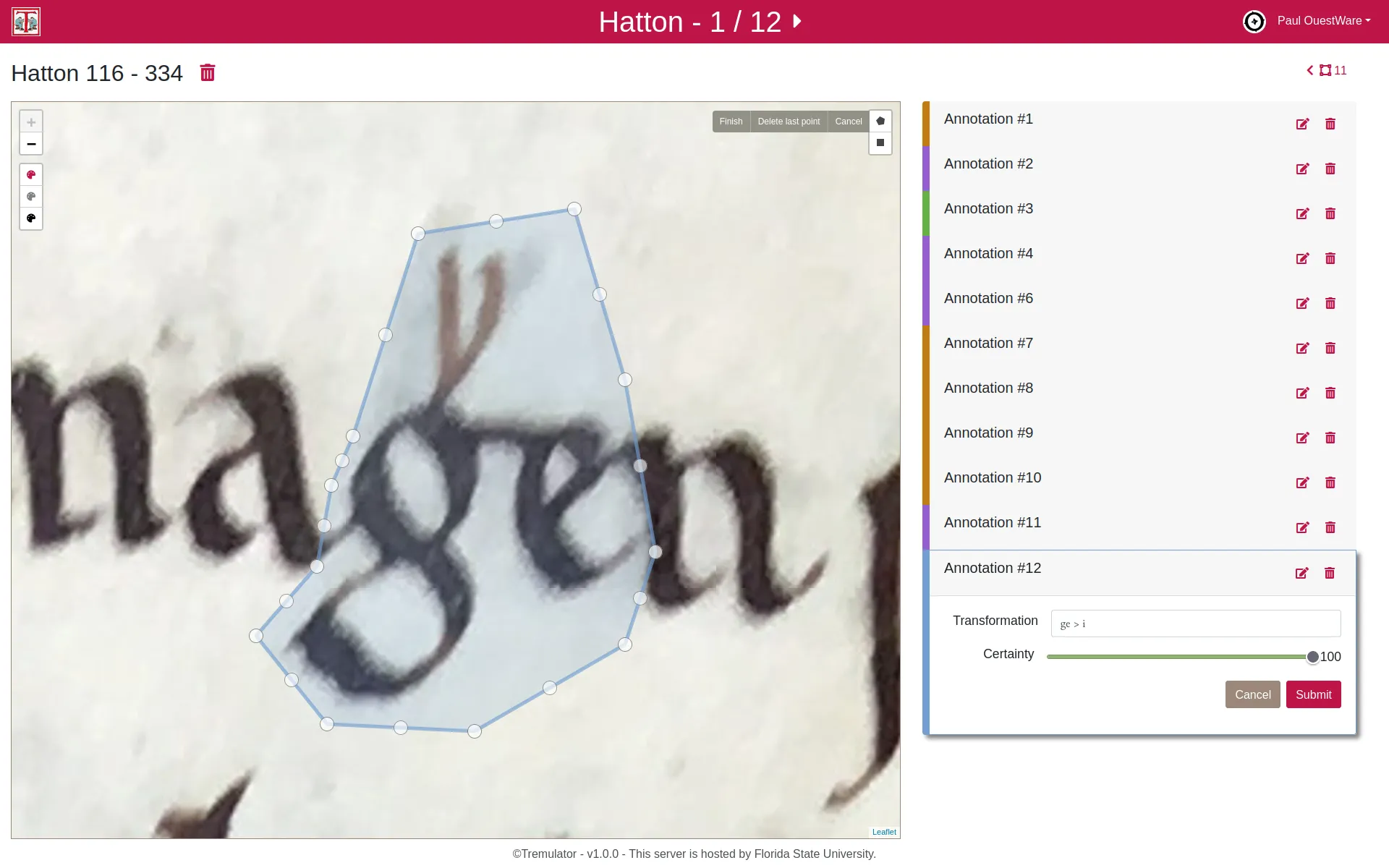
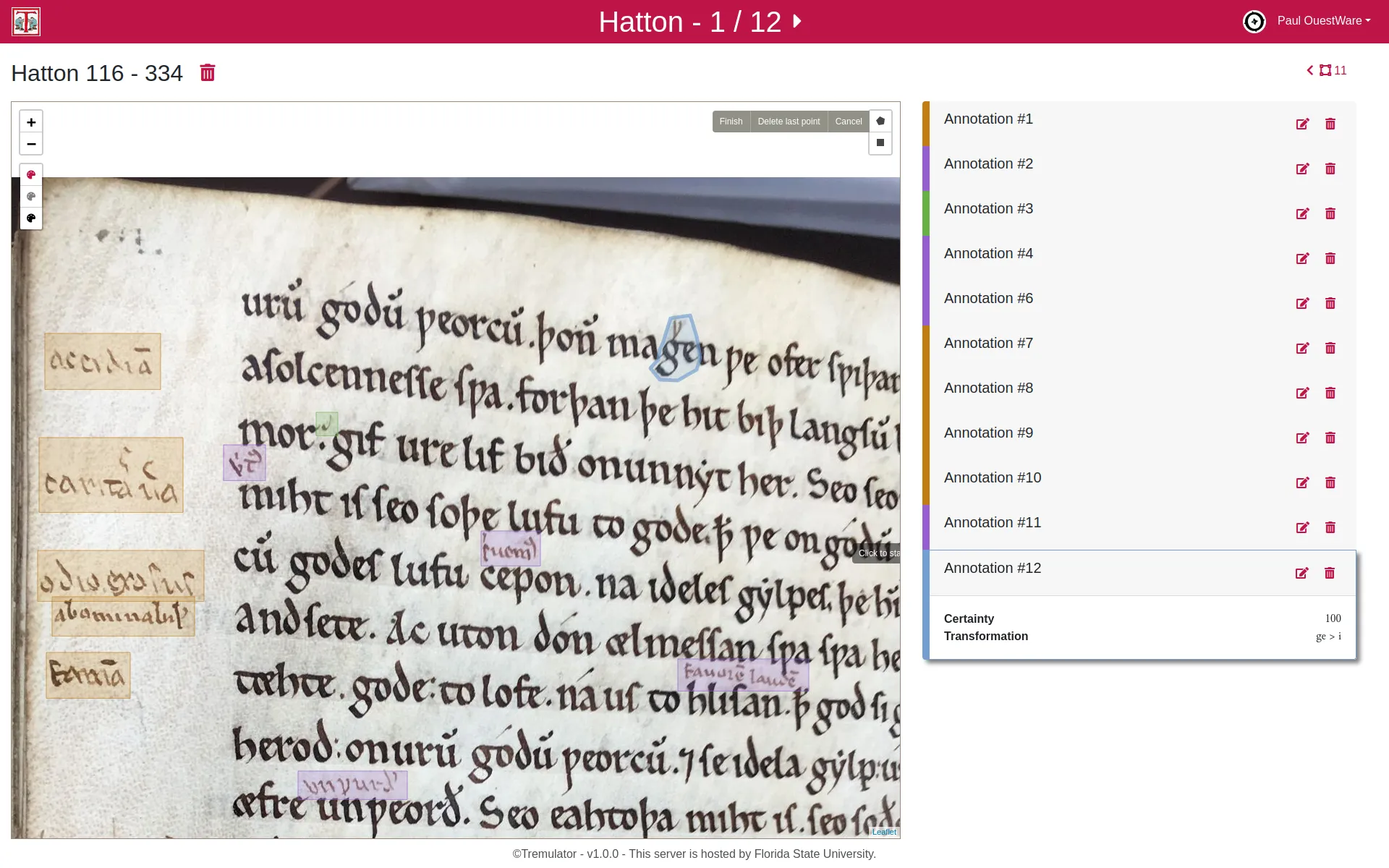
Les manuscrits médiévaux portent rarement de marques directes de propriété, mais les chercheurs peuvent repérer des signes d’usage — annotations, ponctuation ou notes marginales — pour comprendre comment ces livres étaient lus et étudiés. Un exemple célèbre est celui de la « Main tremblante de Worcester », un moine du XIIIe siècle qui a annoté des textes en vieux anglais, utilisant une ponctuation originale pour déchiffrer et interpréter cette langue ancienne. Ses interventions révèlent à la fois sa méthode d’apprentissage et les passages qui retenaient particulièrement son attention, offrant un éclairage unique sur les pratiques de lecture médiévales.
Pour analyser ces traces de manière systématique, Prof. David Johnson utilise des annotations numériques afin de capturer et d’indexer les interventions des lecteurs sur les images des manuscrits. Contrairement à la transcription classique, cette méthode se concentre uniquement sur les marques laissées par les lecteurs, créant ainsi une base de données exploitable pour des analyses quantitatives. En combinant une lecture attentive des annotations individuelles avec des techniques d’analyse à grande échelle, les chercheurs peuvent dégager des tendances et des motifs sur l’ensemble des collections, reliant ainsi l’étude détaillée à l’analyse globale.
L’application Tremulator 2.0 a été conçue pour soutenir cette démarche, en utilisant les standards IIIF pour accéder à des images haute résolution et en permettant la création de schémas d’annotation personnalisés pour divers besoins de recherche. Elle offre la possibilité de collecter, explorer et exporter des données. Cet outil s’avère précieux non seulement pour l’étude des manuscrits, mais aussi pour les humanités numériques, l’histoire de l’art et d’autres domaines nécessitant l’analyse de données visuelles irrégulières.
Un projet de Développement sur-mesure
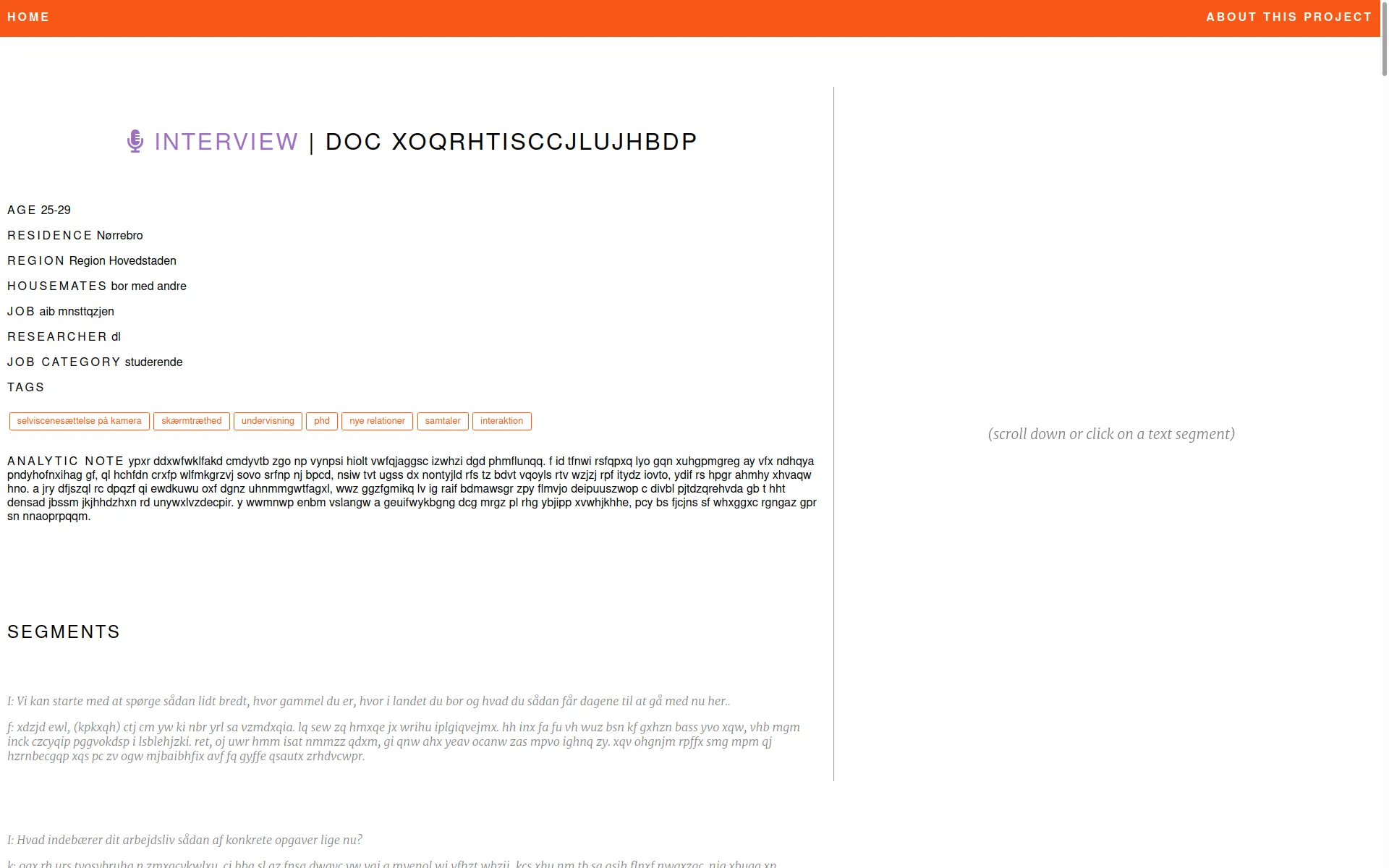

Nous avons développé une application web qui permet à une équipe de recherche d'analyser un corpus d'observations ethnographiques en permettant de naviguer et qualifier le matériel collecté. Ce corpus a été collecté pendant le confinement lié au COVID-19 entre avril et juin 2020 au Danemark. Il contient 222 entretiens, 84 journaux, et 89 observations de terrain.
Cette étude fait partie du projet "The Grammar of Participation: The Digitization of Everyday Life During the Corona Crisis" qui a été mené par des chercheurs du Centre for Digital Welfare de la IT University of Copenhagen et du Techno-Anthropology Lab de la University of Aalborg.
Cet outil n'est pas accessible publiquement. L'accès aux données est réservé à l'équipe de recherche. Les copies d'écran ci-dessous ont été réalisé avec de fausses données.
Un projet de Valorisation de données
Loïc Charles, Guillaume Daudin, Paul Girard et Guillaume Plique
Historical Methods: A Journal of Quantitative and Interdisciplinary History
Paul Girard, Guillaume Daudin, Loïc Charles et Guillaume Plique
Humanistica 2020, Bordeaux, France
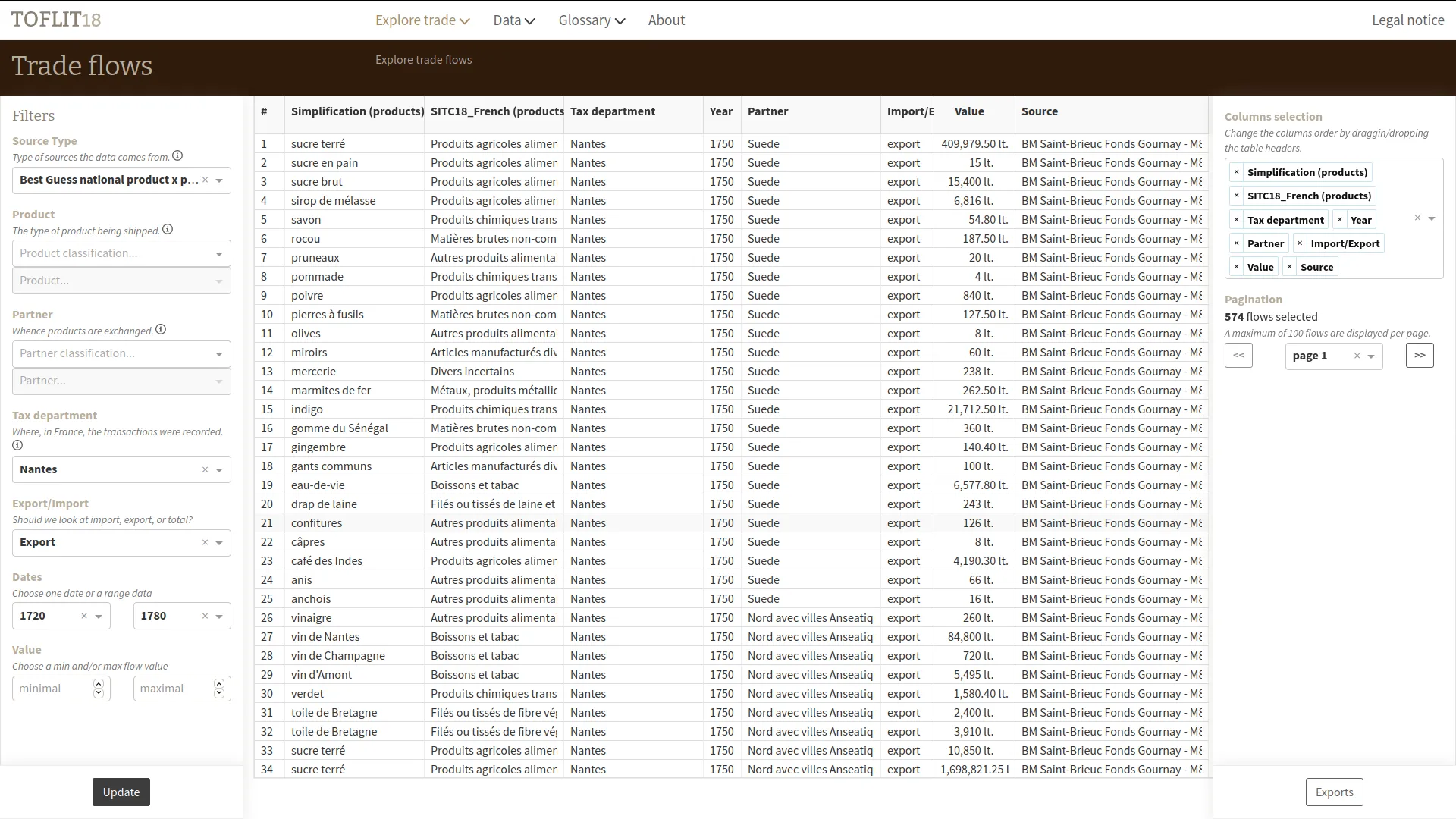
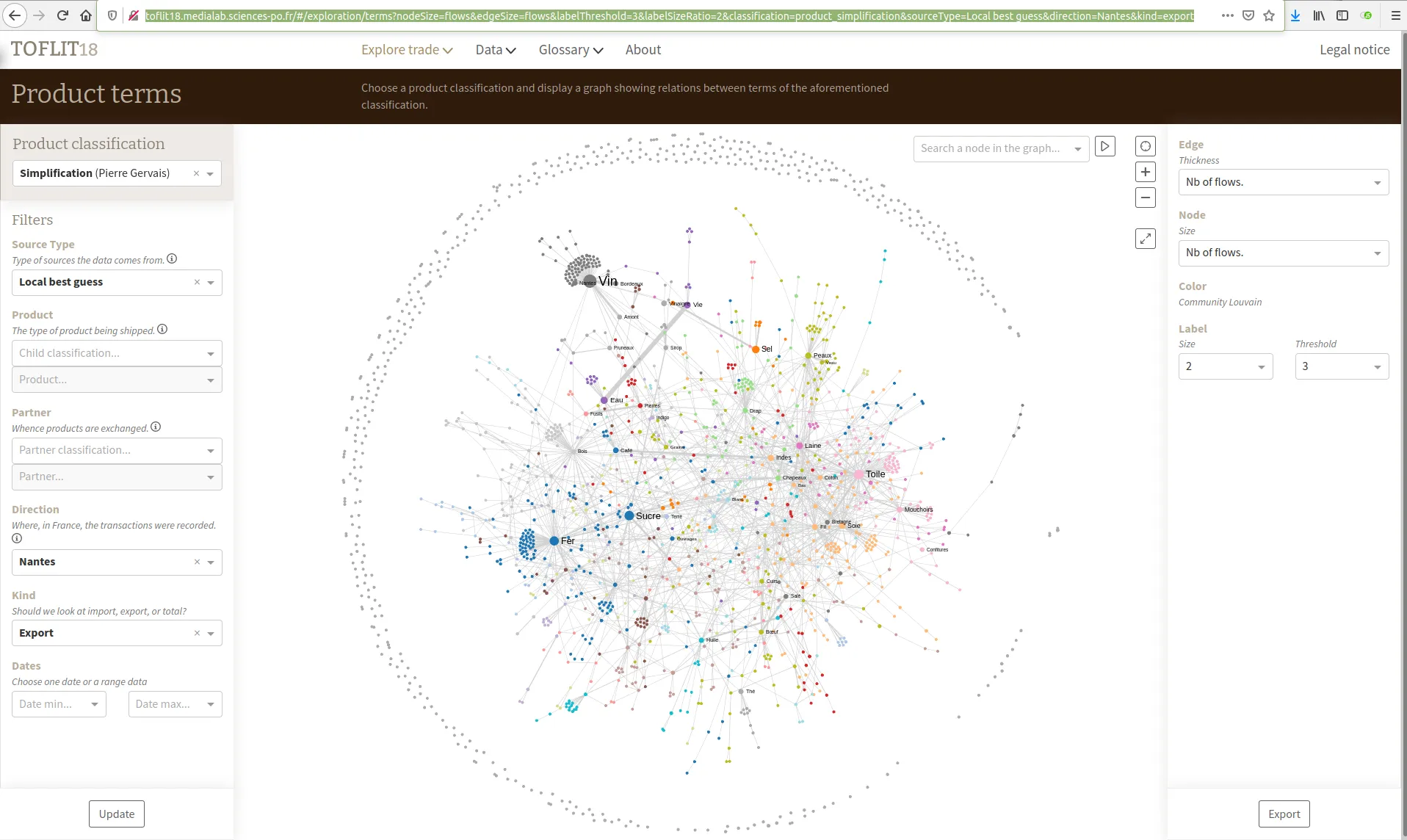

TOFLIT18 est un outil d'exploration visuelle du commerce par marchandise de la France au XVIIIe siècle. Nous avons amélioré cet outil créé par le médialab de Sciences Po en optimisant les requêtes Neo4j et en ajoutant une table de données de flux de commerce ainsi qu'un système de permaliens.
Un projet de Code et Données ouvertes
Cet outil avec un périmètre bien défini est publié après un premier sprint avec le client, puis quelques itérations rapides.

Bibliograph est un outil en ligne que nous avons créé avec et pour Tommaso Venturini dans le but d'équiper ses recherches sur les dynamiques des communautés scientifiques. Notre mission consistait à reproduire une méthode d'analyse par co-références déjà implémentées en python dans un outils en ligne allant jusqu'à l'exploration visuelle des réseaux produits. Une contrainte très forte de temps nous a poussé à choisir de réaliser ce projet en un atelier intensif colocalisé avec le client. En naviguant entre idées et contraintes à l'aide d'une méthode agile nous sommes parvenu à produire un outil simple et efficace de scientométrie conforme au besoin en un temps très court.
Un projet de Valorisation de données
Paul Girard
Bruxelles, Belgique
Béatrice Dedinger et Paul Girard
Historical Methods: A Journal of Quantitative and Interdisciplinary History
Paul Girard et Béatrice Dedinger
Humanistica 2020, Bordeaux, France
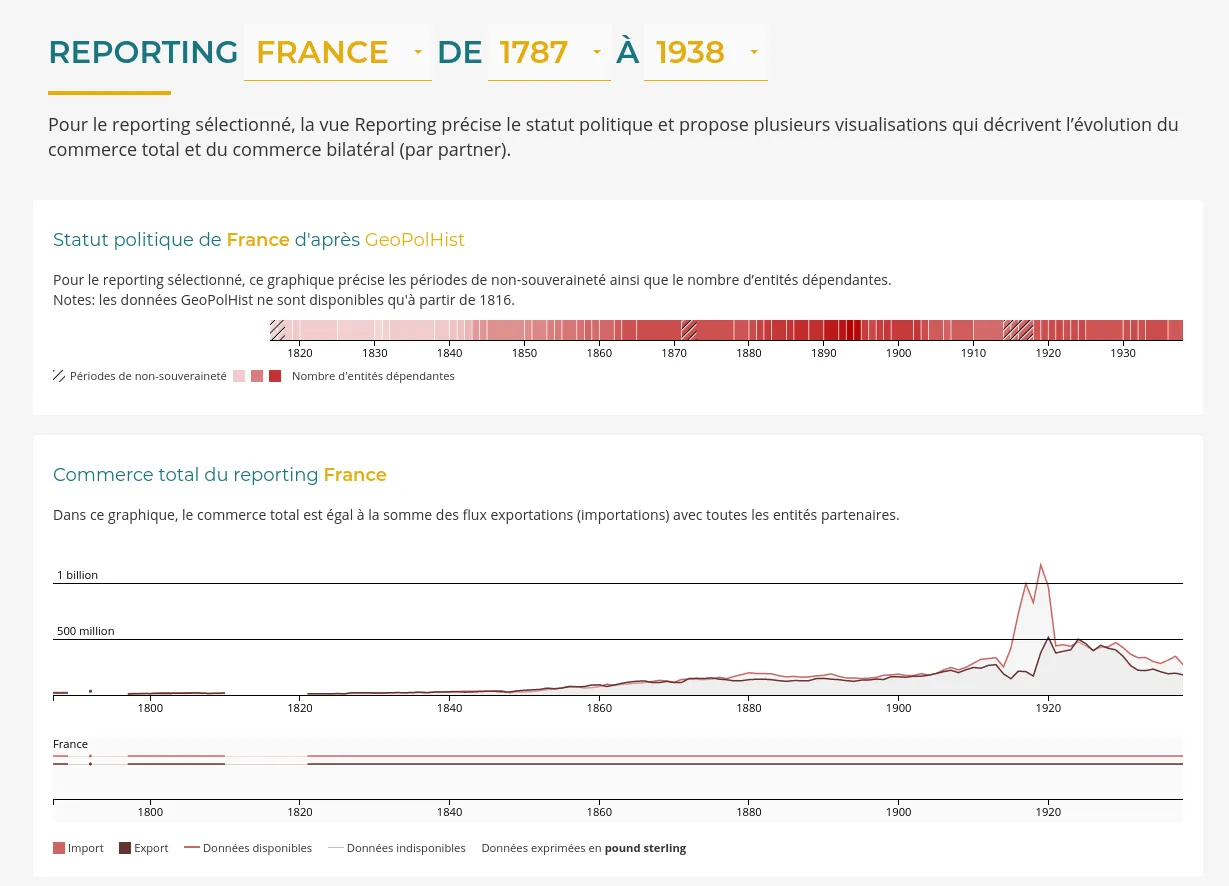
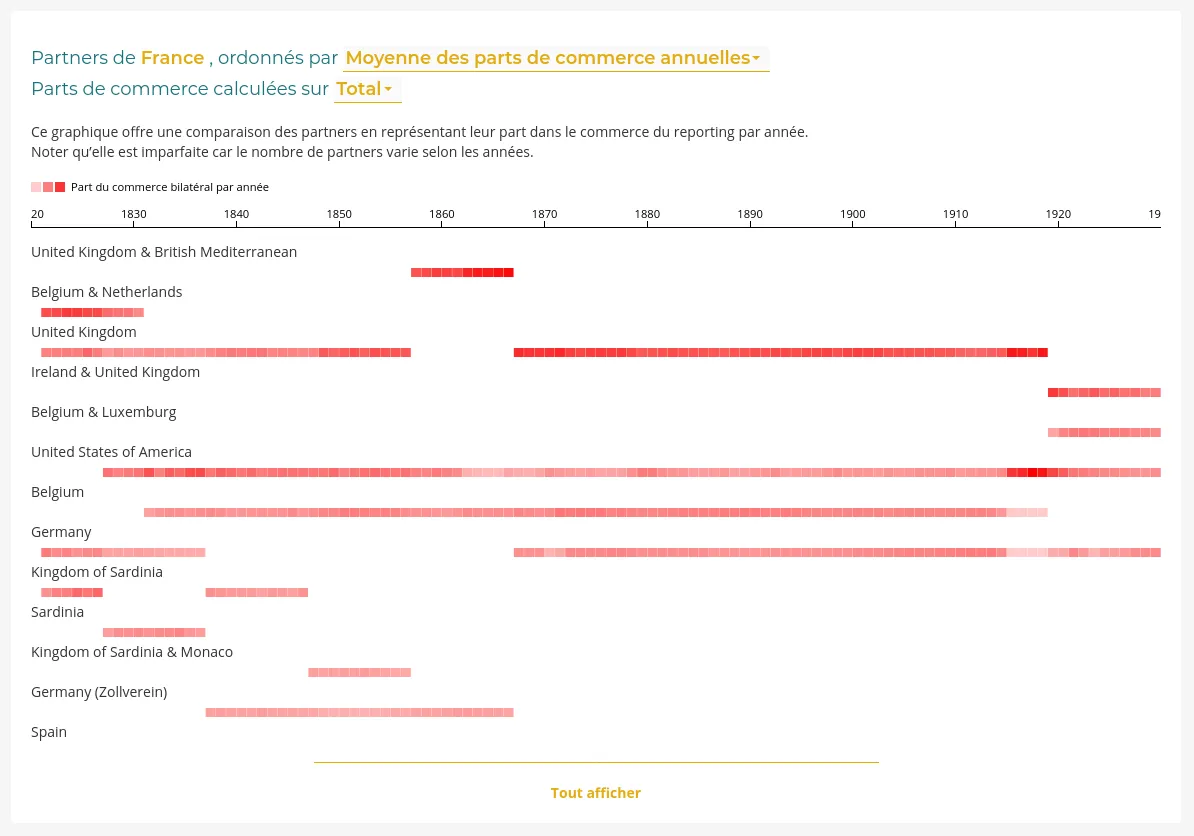
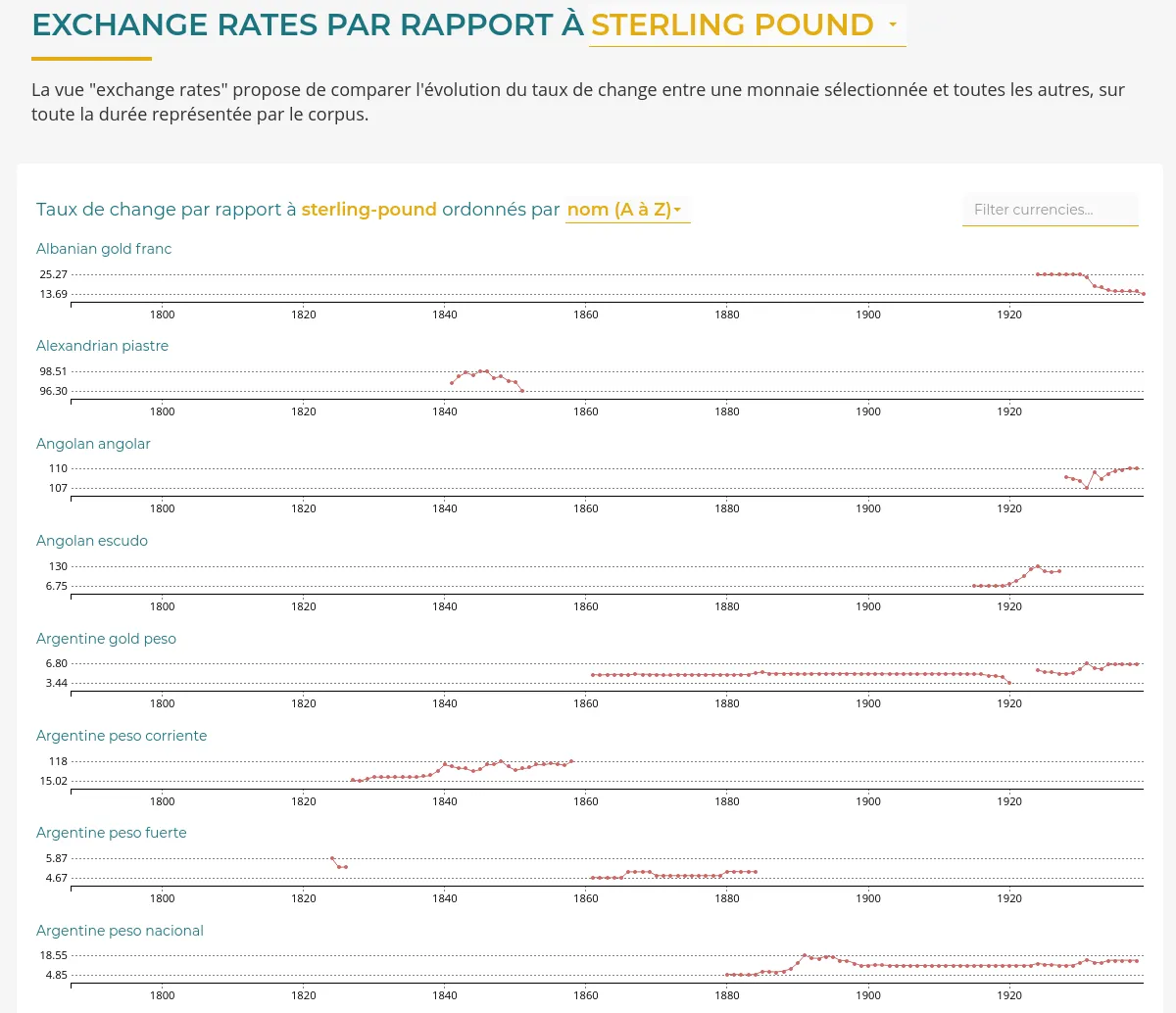

RICardo est un projet de recherche dédié au commerce entre les nations, de la Révolution industrielle à la veille de la Seconde Guerre mondiale.
Nous avons amélioré l'application web existante :
Lire notre post de blog "De nouvelles visualisations pour RICardo" pour découvrir les détails de cette prestation.
Un projet de Valorisation de données
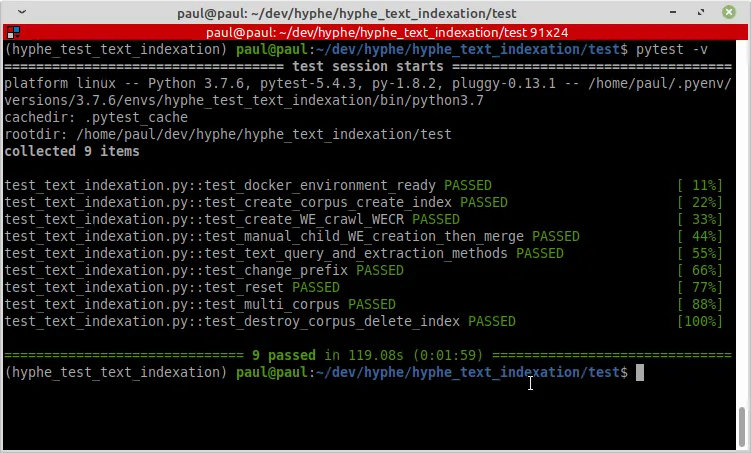

Indexation de contenu web et déploiement automatisé sur OpenStack
Hyphe est un crawler web conçu pour les chercheurs en sciences sociales, et développé par le médialab de Sciences-Po.
Nous y avons ajouté les fonctionnalités suivantes :
Un projet de Code et Données ouvertes
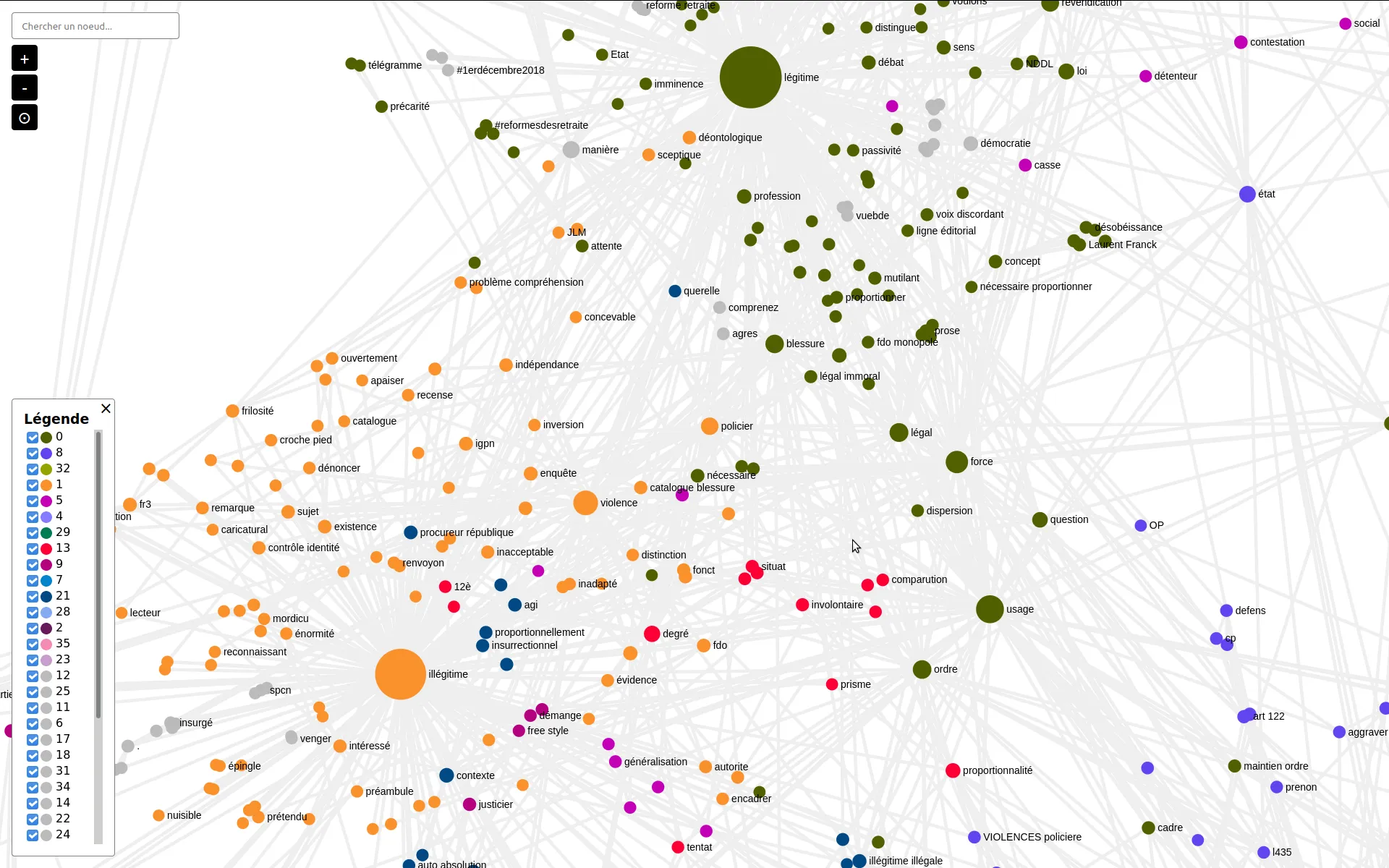
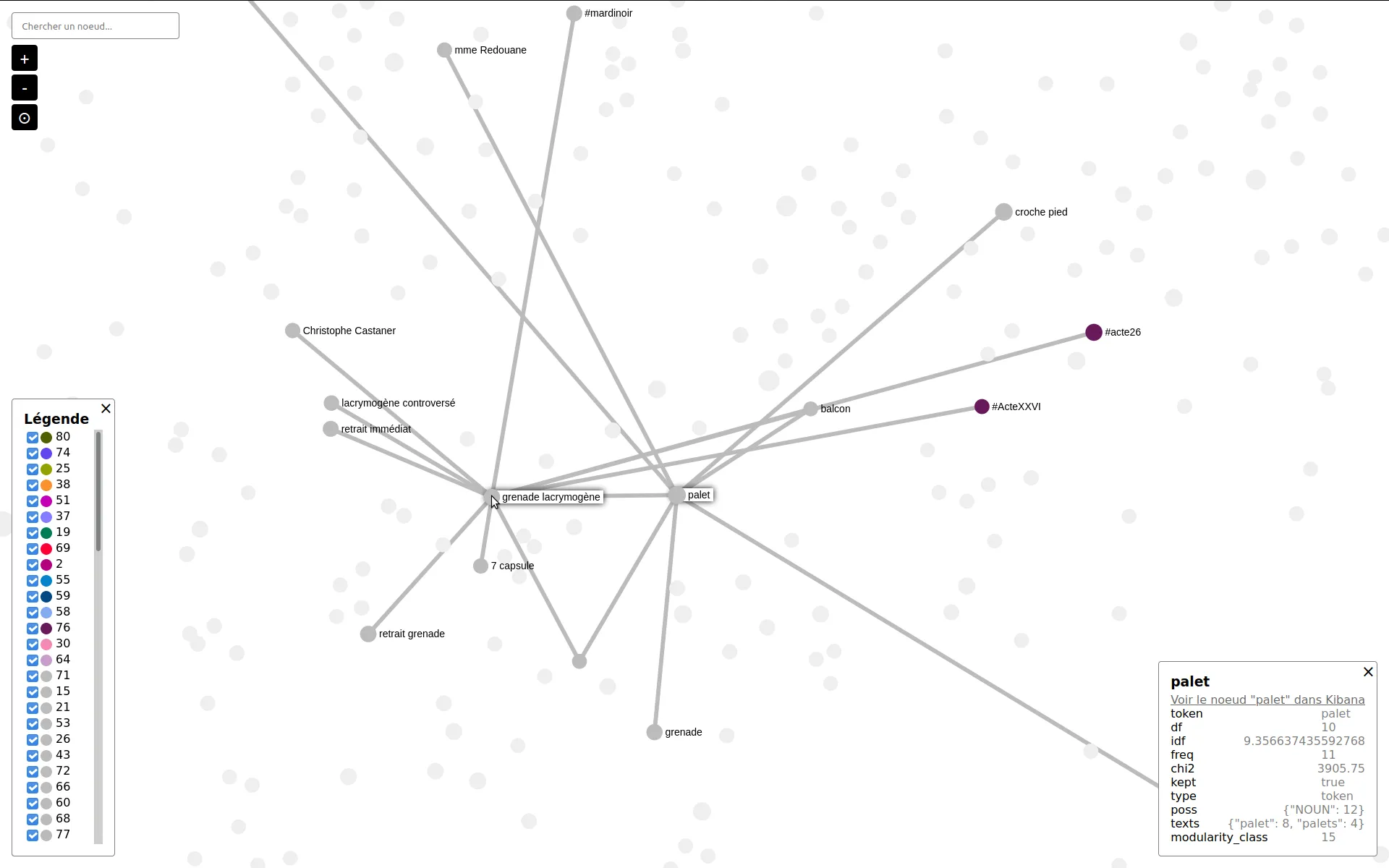
Analyse visuelle et extraction sémantique des thèmes d'un corpus de tweets
En réponse à un besoin d'analyse sémantique d'un corpus de tweets, nous avons mis en place une chaîne d'extraction de thèmes de ce corpus, par analyse des cooccurrences et filtrage de tokens par CHI². Nous avons également sorti un outil en ligne pour explorer les communautés thématiques, sous forme de réseaux de cooccurrences des termes.
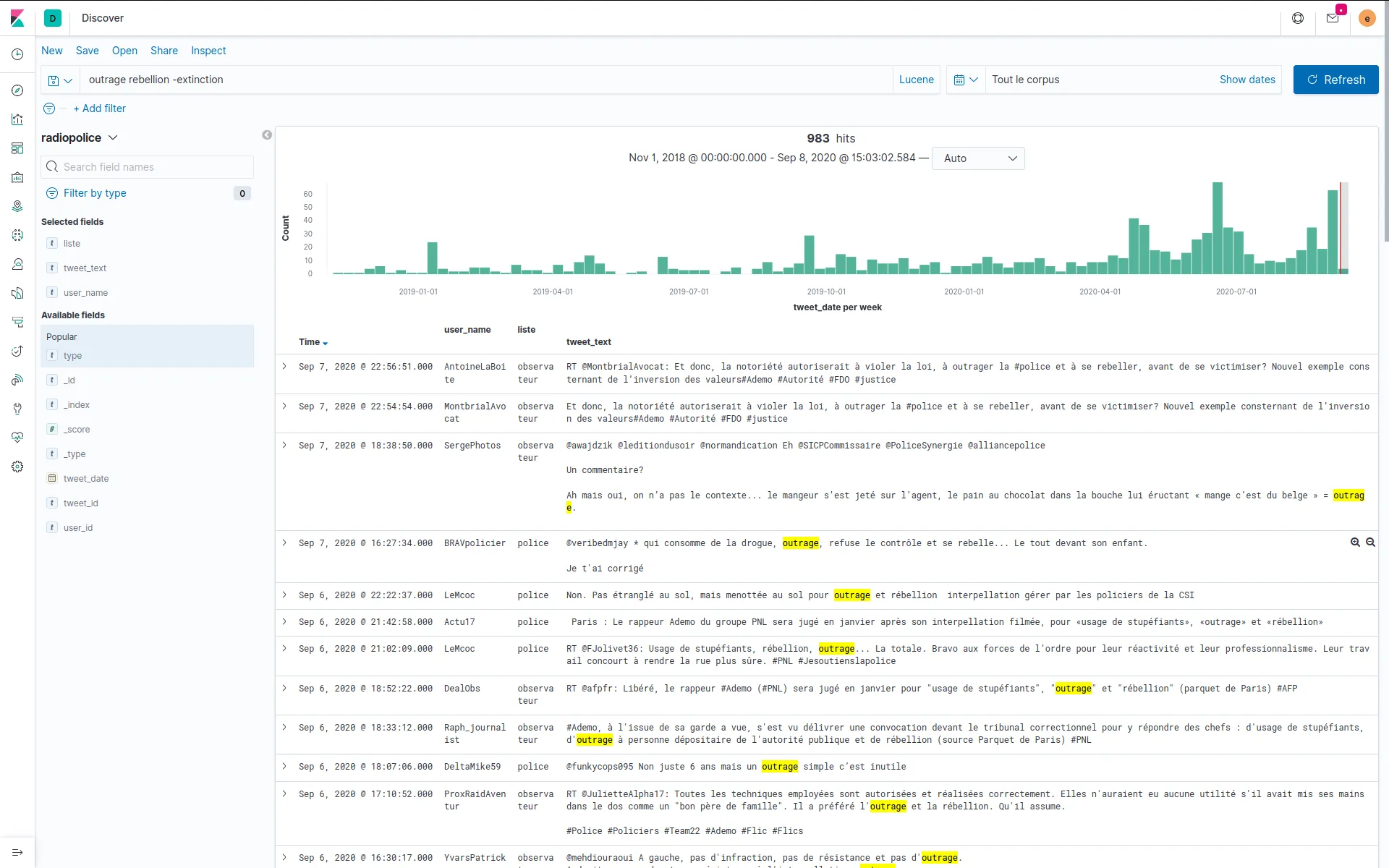
Dans le cadre de la publication du corpus par David Dufresne et le journal Mediapart, nous avons ensuite proposé l'usage d'ElasticSearch et Kibana pour former des requêtes correspondant à chacun des thèmes définis par l'équipe éditoriale, et aggréger les indicateurs représentés dans l'interface finale conçue et développée par WeDoData, Etamin Studio et Philippe Rivière / Visions carto.
Un projet de Valorisation de données
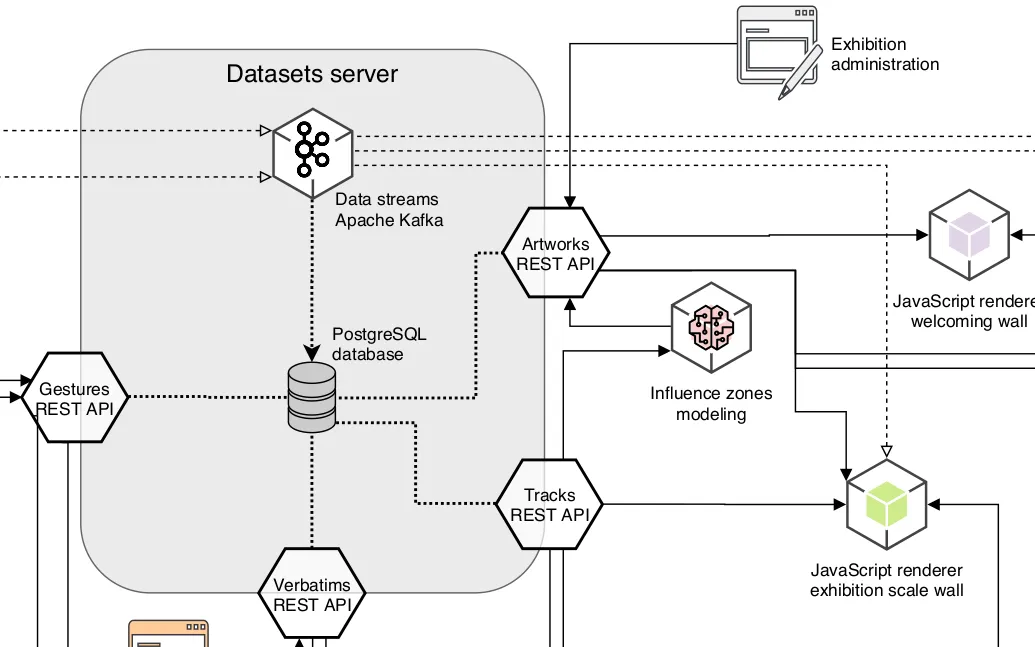
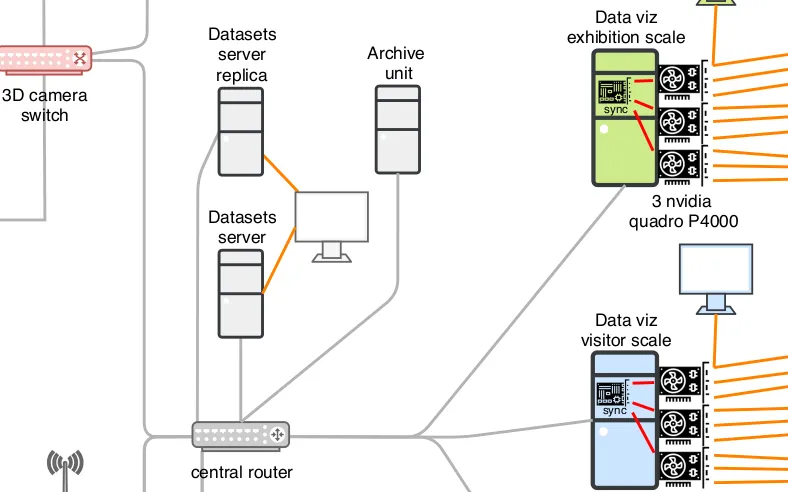

Spécifications de l'infrastructure de données d'une exposition interactive
Nous avons conçu l'infrastructure des données d'une exposition observant ses visiteurs : spécifications des flux de données depuis les systèmes de captation, jusqu'aux mur-écrans projetant les visualisations en passant par les processus d'analyse, d'archivage et de rendus graphiques.
L'exposition ayant été annulée à cause de l'épidémie de COVID-19, nous n'avons pas pu passer en production pour le moment.
Un projet de Conseils et accompagnement

Nous avons participé au développement du tunnel de paiement d'un des plus gros sites français de e-commerce, en Clojure et ClojureScript.
Un projet de Conseils et accompagnement
Développement de plugins métier pour Kibana
Notre client, un acteur industriel, voulait distribuer des tableaux de bord dans un de leur produit. Après une brève étude, Kibana a semblé la meilleure option, mais manquait certaines fonctionnalités.
Nous avons développé un plugin pour Kibana avec ces fonctionnalités (intégration des tableaux de bords dans une page sur mesure, styles personnalisés).
Un projet de Conseils et accompagnement

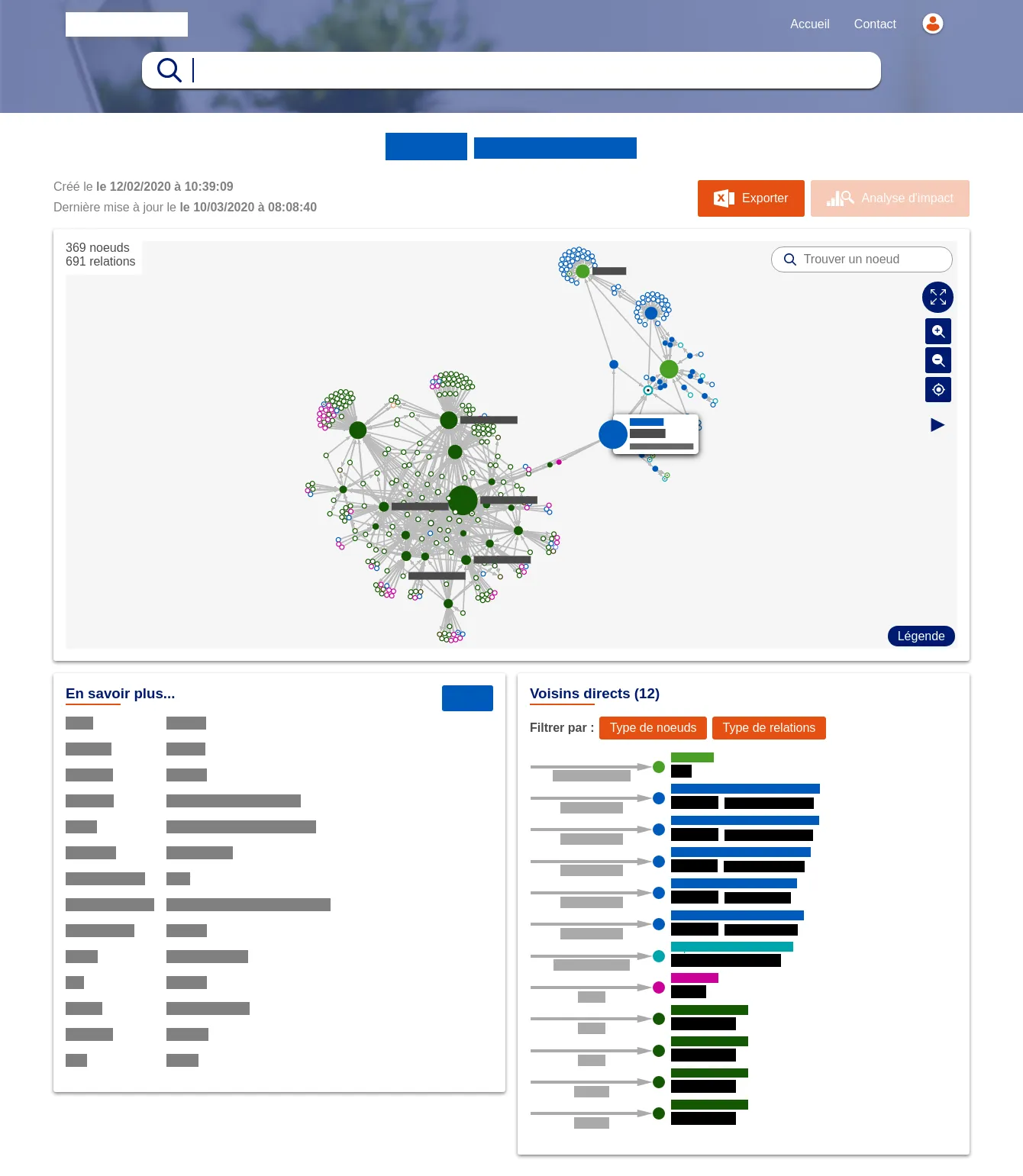
Nous intervenions pour le compte de Neo4j chez plusieurs de leurs clients pour les assister dans leurs projets de graphes. Cela allait de la mission d'expertise sur Neo4j ou de chargement et/ou de visualisation de données, à la réalisation d'innovation labs, de prototypes, voire de projets web complets.
Un projet de Conseils et accompagnement