
GRAND Stack : Un schéma pour les gouverner tous

Dans cet article je vais vous montrer la puissance de la GRAND stack qui permet de créer une application web moderne basée sur Neo4j et GraphQL, et où toutes les couches sont typées grâce à votre schéma de données.
Note : Le code source associé à l’article est disponible sur GitLab.
Il vous faut également une base Neo4j avec le graphe des films (ie. :play movie dans le navigateur Neo4j)
et changer le login/password dans le fichier backend/src/config.ts
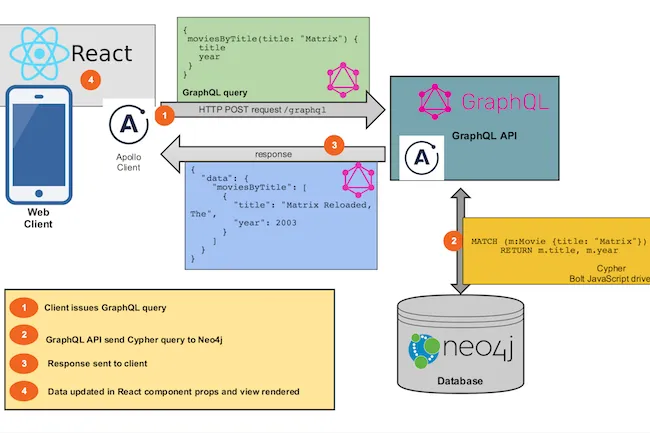
GRAND stack
Développé par Neo4j, la GRAND stack a été créée pour développer des applications web modernes, de manière rapide et performante, le tout basé sur du graphe.
Elle est composée des éléments suivants :
- GraphQL pour le serveur d’API
- React pour l’application web en Single Page Application
- Apollo comme client & serveur GraphQL
- Neo4j Database pour le stockage de vos données
Voici comment s’articule ces éléments :
GraphQL & Neo4j, une belle histoire
Le point clé de GraphQL est que votre schéma de données est un graphe, et justement Neo4j est une base de données orientée graphe. Il y a donc une symbiose parfaite entre les deux.
Neo4j développe la librairie neo4j-graphql-js qui permet de faire le lien entre GraphQL et Neo4j, et c’est plutôt puissant.
Cette librairie vous libère de l’écriture du code de vos resolvers GraphQL, juste en ajoutant des directives à votre schéma.
Ce que j’apprécie aussi, c’est le fait qu’une requête GraphQL ne génère qu’une requête Cypher, ce qui évite le problème N+1 de GraphQL.
Mais cette librairie peut encore en faire plus pour vous, elle peut générer vos schémas, et c’est ce que nous allons voir dans la suite.
Génération du schéma GraphQL depuis celui de Neo4j
La fonction inferSchema de la librairie permet de générer automatiquement votre schéma GraphQL depuis la structure des données d’une base de données Neo4j :
import neo4j from "neo4j-driver";
import { inferSchema } from "neo4j-graphql-js";
import { config } from "../src/config";
// create the neo4j driver
const driver = neo4j.driver(config.neo4j.url, neo4j.auth.basic(config.neo4j.login, config.neo4j.password));
// infer the graphql schema from neo4j
inferSchema(driver).then((result) => {
console.log(result.typeDefs);
process.exit();
});Sur le graphe des films de Neo4j, on obtient le résultat suivant :
type Person {
_id: Long!
born: Int
name: String!
acted_in: [Movie] @relation(name: "ACTED_IN", direction: OUT)
ACTED_IN_rel: [ACTED_IN]
directed: [Movie] @relation(name: "DIRECTED", direction: OUT)
produced: [Movie] @relation(name: "PRODUCED", direction: OUT)
wrote: [Movie] @relation(name: "WROTE", direction: OUT)
follows: [Person] @relation(name: "FOLLOWS", direction: OUT)
reviewed: [Movie] @relation(name: "REVIEWED", direction: OUT)
REVIEWED_rel: [REVIEWED]
}
type Movie {
_id: Long!
released: Int!
tagline: String
title: String!
persons_acted_in: [Person] @relation(name: "ACTED_IN", direction: IN)
persons_directed: [Person] @relation(name: "DIRECTED", direction: IN)
persons_produced: [Person] @relation(name: "PRODUCED", direction: IN)
persons_wrote: [Person] @relation(name: "WROTE", direction: IN)
persons_reviewed: [Person] @relation(name: "REVIEWED", direction: IN)
}
type ACTED_IN @relation(name: "ACTED_IN") {
from: Person!
to: Movie!
roles: [String]!
}
type REVIEWED @relation(name: "REVIEWED") {
from: Person!
to: Movie!
rating: Int!
summary: String!
}Cela évite pas mal de travail sur la création de son schéma. Généralement, j’y fais quelques modifications comme :
- la suppression des champs
_id - renommer les champs correspondant aux relations
- corriger la cardinalité des relations
Donc j’ai souvent une tâche dans mon package.json qui me permet d’afficher en console
le schéma générer en exécutant la commande npm run generate:schema.
Mais le schéma généré est fonctionnel, vous pouvez l’utiliser tel quel.
Generation du schéma Neo4j depuis GraphQL
La librairie vous permet aussi de maintenir à jour les indexes et contraintes Neo4j directement depuis votre schéma GraphQL.
Depuis la version 2.16.0, neo4j-graphql-js, la librairie dispose des directives suivantes :
@id: pour définir les clés primaires (ne peut être utilisé qu’une fois par type, lesnode keysn’étant pas supportés pour l’instant)@index: pour créer les indexes (ne supporte pas les indexes composites pour l’instant)@unique: pour créer les contraintes d’unicités
Voici un exemple :
type Person {
id: ID! @id
name: String! @index
hash: String! @unique
born: Date
}Une fois la définition faite, il ne reste plus qu’à utiliser la fonction assertSchema
pour appliquer le schéma sur la base :
import { ApolloServer } from "apollo-server-express";
import { Express } from "express";
import { Server } from "http";
import neo4j from "neo4j-driver";
import { assertSchema, makeAugmentedSchema } from "neo4j-graphql-js";
import { config } from "../config";
import { config as gqlConfig, resolvers, typeDefs } from "./schema";
export function register(server: Server, app: Express): void {
// create the neo4j driver
const driver = neo4j.driver(config.neo4j.url, neo4j.auth.basic(config.neo4j.login, config.neo4j.password));
// create the Neo4j graphql schema
const schema = makeAugmentedSchema({
typeDefs,
resolvers,
config: gqlConfig,
});
// create the graphql server with apollo
const serverGraphql = new ApolloServer({
schema,
context: { driver },
});
// Register the graphql server to express
serverGraphql.applyMiddleware({ app });
// Sync the Neo4j schema (ie. indexes, constraints)
assertSchema({ schema, driver, debug: true });
}Et voici le résultat de son exécution :
┌─────────┬─────────────────┬─────────┬─────────────┬────────┬───────────┐
│ (index) │ label │ key │ keys │ unique │ action │
├─────────┼─────────────────┼─────────┼─────────────┼────────┼───────────┤
│ 0 │ 'Person' │ 'name' │ [ 'name' ] │ false │ 'CREATED' │
│ 1 │ 'Person' │ 'id' │ [ 'id' ] │ true │ 'CREATED' │
│ 2 │ 'Person' │ 'hash' │ [ 'hash' ] │ true │ 'CREATED' │
└─────────┴─────────────────┴─────────┴─────────────┴────────┴───────────┘La fonction assertSchema synchronise votre définition de schéma GraphQL avec Neo4j.
Ainsi si vous enlevez @unique sur le champs hash et que vous ré-exécuter le code,
vous obtiendrez le résultat suivant :
┌─────────┬──────────┬────────┬────────────┬────────┬───────────┐
│ (index) │ label │ key │ keys │ unique │ action │
├─────────┼──────────┼────────┼────────────┼────────┼───────────┤
│ 0 │ 'Person' │ 'name' │ [ 'name' ] │ false │ 'KEPT' │
│ 1 │ 'Person' │ 'id' │ [ 'id' ] │ true │ 'KEPT' │
│ 2 │ 'Person' │ 'hash' │ [ 'hash' ] │ true │ 'DROPPED' │
└─────────┴──────────┴────────┴────────────┴────────┴───────────┘Comme vous pouvez le voir, la contrainte d’unicité a été supprimée.
React, TypeScript & GraphQL
Si vous voulez créer une application React avec des types, évidemment TypeScript est de la partie.
Mais ce qui est cool, c’est qu’avec GraphQL on peut générer nos types ! Avant de voir ça en action, la première chose à faire c’est d’initialiser notre project.
Initialisation du projet React
La façon la plus simple c’est d’utiliser le template create-react-app avec le support de TypeScript :
$> npx create-react-app frontend --template typescriptPuis pour le support de GraphQL, nous devons installer les dépendances suivantes :
$> npm install @apollo/client graphqlÀ présent, c’est fini pour les dépendances, mais on doit faire un peu de code
pour créer le client GraphQL (fichier src/graphql/client.ts) :
import { ApolloClient, InMemoryCache } from "@apollo/client";
export const client = new ApolloClient({
uri: "http://localhost:4000/graphql",
cache: new InMemoryCache(),
});Finalement, il ne reste plus qu’à encapsuler notre application react
avec le composant ApolloProvider (fichier ./srcindex.tsx) :
// graphQl
import { ApolloProvider } from "@apollo/client";
import React from "react";
import ReactDOM from "react-dom";
import * as serviceWorker from "./serviceWorker";
import { App } from "./App";
import { client } from "./graphql/client";
import "./index.css";
ReactDOM.render(
<React.StrictMode>
<ApolloProvider client={client}>
<App />
</ApolloProvider>
</React.StrictMode>,
document.getElementById("root"),
);
serviceWorker.unregister();Note : Pour plus d’informations sur l’intégration d’Apollo, vous pouvez consulter cette page.
Au final, vous avez une application React fonctionnelle avec le support de TypeScript et de GraphQL.
Generation des Types et des Hooks schema
Pour voir la génération de code à partir du code GraphQL, nous devons en ajouter dans notre application. Ainsi je vais continuer l’exemple sur le modèle du graphe des films.
Un peu de code GraphQL
Comme exemple, je vais faire une requête simple qui permet de récupérer les acteurs avec les films dans lesquels ils ont joué.
Premièrement, je vais créer un fragment GraphQL pour chacun des modèles :
import { DocumentNode } from "graphql";
import gql from "graphql-tag";
export const fragments: { [name: string]: DocumentNode } = {
movie: gql`
fragment Movie on Movie {
_id
title
tagline
released
}
`,
person: gql`
fragment Person on Person {
_id
name
born
}
`,
};Et voici la requête :
import gql from "graphql-tag";
import { fragments } from "./fragments";
export const getActors = gql`
query GetActors {
actors: Person {
...Person
acted_in {
...Movie
}
}
}
${fragments.person}
${fragments.movie}
`;Maintenant on peut s’attaquer à la génération du code.
Génération de code
La génération du code se fait avec la librairie graphql-codegen. Il faut l’installer avec les dépendances dont nous allons avoir besoin :
$> npm install \
@graphql-codegen/cli \
@graphql-codegen/typescript \
@graphql-codegen/typescript-graphql-files-modules \
@graphql-codegen/typescript-operations \
@graphql-codegen/typescript-react-apolloEt j’ajoute une tache dans le package.json pour la génération :
...
"scripts": {
...
"generate:types": "graphql-codegen",
}
...Le dernier point, c’est de créer le fichier de configuration pour graphql-codegen.
Il s’agit du fichier codegen.xml à la racine du projet avec le contenu suivant :
schema: http://localhost:4000/graphql
documents: ["src/graphql/**/*.ts"]
generates:
./src/graphql/types.tsx:
plugins:
- typescript
- typescript-operations
- typescript-react-apollo
config:
withHooks: true
avoidOptionals: trueQuelques explications :
schema: http://localhost:4000/graphql: permet de définir l’URL de votre serveur GraphQLdocuments: ["src/graphql/***/**.ts"]: la localisation de votre code GraphQL (queries, fragments…,) au sein de votre applicationgenerates: comment et où le code est généré. Pour le où ici c’est dans le fichier./src/graphql/types.tsx
Quant au comment, c’est par la définition des plugins :
- typescript pour le support TypeScript
- typescript-operations pour la génération des types des opérations votre schéma GraphQL (queries, mutations, inputs, variables, …)
- typescript-react-apollo pour la génération des hooks react via Apollo
Maintenant vous pouvez exécuter la commande suivante :
$> npm run generate:types
> frontend@0.1.0 generate:types /home/bsimard/worspaces/ouestware/grand-stack-example/frontend
> graphql-codegen
✔ Parse configuration
✔ Generate outputsVous pouvez voir le résultat dans le fichier src/graphql/types.
Le code généré
Depuis le schéma GraphQL
La génération depuis le schéma comprend les éléments suivants :
- GraphQL types (dans notre exemple donc
Movie&Person) - GraphQL inputs & variables, pour vos requêtes & mutations
- La définition complète de vos requêtes et mutations (vous pouvez rechercher
export type Mutation = {ouexport type Query = {)
Si on cherche notre type Movie, voici ce qu’on trouve :
export type Movie = {
__typename?: "Movie";
_id: Maybe<Scalars["String"]>;
released: Scalars["Int"];
tagline: Maybe<Scalars["String"]>;
title: Scalars["String"];
persons_acted_in: Maybe<Array<Maybe<Person>>>;
persons_directed: Maybe<Array<Maybe<Person>>>;
persons_produced: Maybe<Array<Maybe<Person>>>;
persons_wrote: Maybe<Array<Maybe<Person>>>;
persons_reviewed: Maybe<Array<Maybe<Person>>>;
};C’est l’exact traduction de notre type GraphQL.
Depuis le code GraphQL (queries, fragment, …)
Le générateur parse également vos requêtes et fragments.
Pour chaque fragment, un type est créé dont le nom suit la convention ${my_fragment_name}Fragment.
Vu que dans le code nous avons défini un fragment nommé Movie, regardons son type généré MovieFragment :
export type MovieFragment = { __typename?: "Movie" } & Pick<Movie, "_id" | "title" | "tagline" | "released">;Et la meilleur partie, c’est la génération des hooks React pour Apollo.
Pour chaque requête (ou mutation), un hook est généré suivant la convention de nommage use${my_query_name}Query.
Vu que dans le code nous avons défini le requête GetActors, recherchons useGetActorsQuery dans le fichier :
export function useGetActorsQuery(baseOptions?: Apollo.QueryHookOptions<GetActorsQuery, GetActorsQueryVariables>) {
return Apollo.useQuery<GetActorsQuery, GetActorsQueryVariables>(GetActorsDocument, baseOptions);
}
// for reference
export type GetActorsQueryVariables = Exact<{ [key: string]: never }>;
export type GetActorsQuery = { __typename?: "Query" } & {
actors: Maybe<
Array<
Maybe<
{ __typename?: "Person" } & {
acted_in: Maybe<Array<Maybe<{ __typename?: "Movie" } & MovieFragment>>>;
} & PersonFragment
>
>
>;
};Et ce qu’on constate, c’est que tout est typé, des variables aux résultats, en passant par les options. Il ne nous reste plus qu’à utiliser tout ça !
Comment l’utiliser
L’utilisation des hooks générés se fait de la même manière que ceux qu’on trouve dans la documentatino d’Apollo :
import React from "react";
import { ActorBox } from "./ActorBox";
import { useGetActorsQuery } from "./graphql/types";
export const ActorsList: React.FC = () => {
// Loading the data
const { data, loading, error } = useGetActorsQuery({ variables: {} });
return (
<>
<h1>Actors</h1>
{loading && <p>Loading ...</p>}
{error &&
error.graphQLErrors.map((e) => {
return <p>e.message</p>;
})}
{data?.actors &&
data.actors.map((actor) => {
return <ActorBox actor={actor} />;
})}
</>
);
};Ce que j’apprécie aussi c’est l’utilisation des fragments dans mes composants d’affichage :
import React from "react";
import { MovieBox } from "./MovieBox";
import { MovieFragment, PersonFragment } from "./graphql/types";
interface Props {
actor: (PersonFragment & { acted_in: Array<MovieFragment | null> | null }) | null;
}
export const ActorBox: React.FC<Props> = (props: Props) => {
const { actor } = props;
if (actor === null) return null;
return (
<div className="actor">
<h2>
{actor.name} - ({actor.born})
</h2>
<div className="actor-movies">
{actor.acted_in?.map((movie) => {
return <MovieBox key={movie?._id} movie={movie} />;
})}
</div>
</div>
);
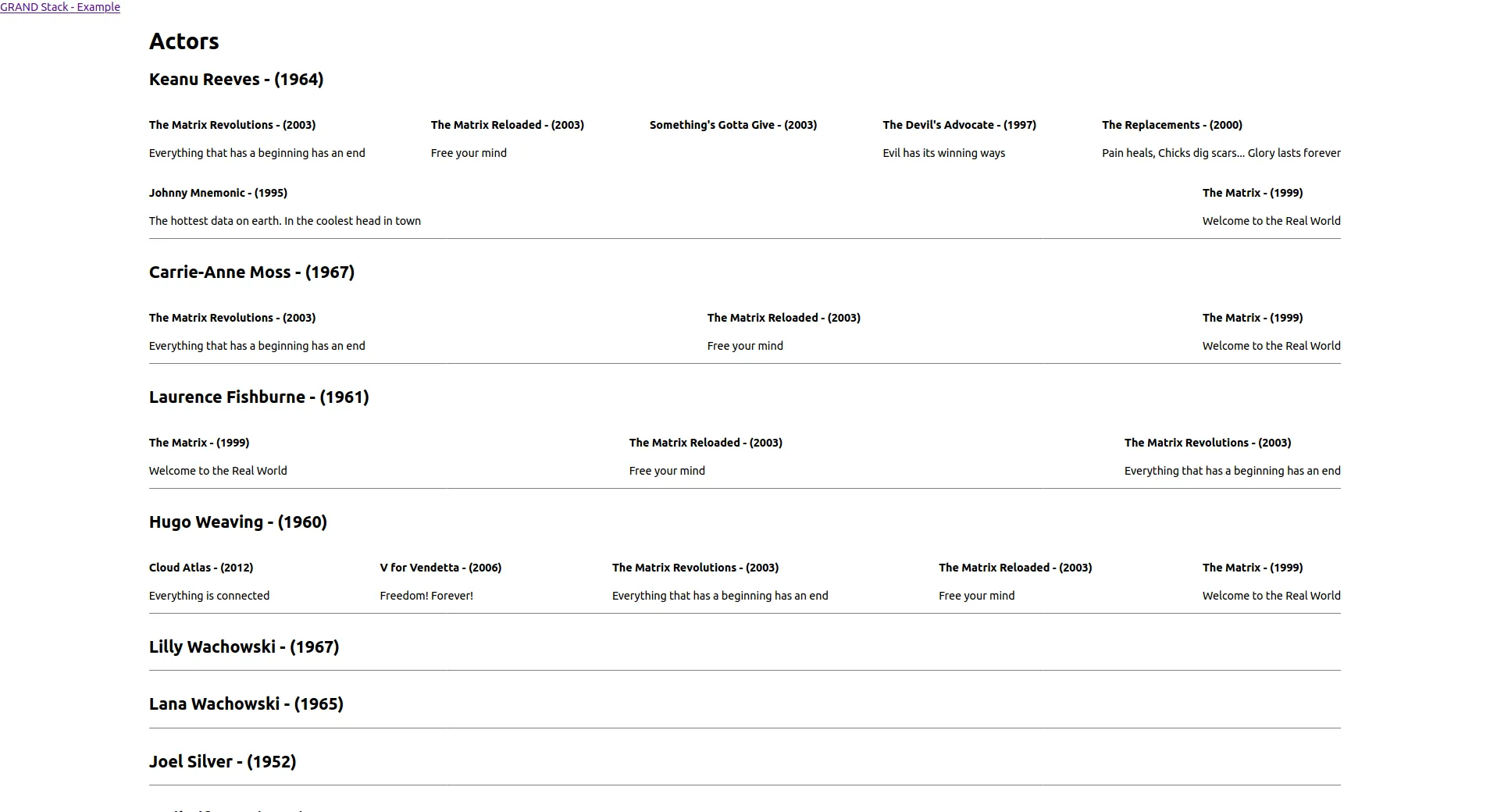
};Et voici le résultat final de l’application :
Conclusion
Avec la GRAND stack et tout ce process, nous avons une stack technique où toutes les couches sont typées. De surcroît, les types sont propagés depuis la base de données jusqu’à l’application web. Les avantages de cette solution sont multiples et en voici quelques un :
- Le développement est plus rapide grâce à la génération du code ( neo4j-graphql-js & graphql-codegen)
- L’ajout des types facilite le développement, via l’auto-completion des IDE
- Le schéma des données est le même pour tout le monde, tout le monde parle le même langage
- La stack est fortement typée avec une solide interface entre chaque couche
- Et enfin le refactoring du modèle de données est beaucoup plus aisé, vu que les impacts se voient directement à la compilation